


Содержание статьи
- Знакомимся с языком R и готовим рабочее место
- Готовим данные
- Как конструируют признаки
- Пишем функцию чтения писем из файлов
- Готовим корпус текстов для спамных писем
- Готовим почву для конструирования признаков
- Генерируем тренировочные данные
- Обрабатываем письма easy_nonspam
- Пишем классификатор
- Как работает classifyEmail
- Проверяем детектор
- Тестируем детектор
- Рисуем результат на графике
Сначала, впрочем, должен предупредить, что для полного понимания будет хорошо, если ты уже знаком с азами статистических методов. Я, конечно, постараюсь изложить материал так, чтобы у вдумчивого читателя, незнакомого со статистикой, тоже был шанс вникнуть в тему, но теоретические основы статистики останутся за рамками этой статьи.
Плюс я исхожу из того, что ты, с одной стороны, хорошо подкован в теории и практике программирования, разбираешься в алгоритмах и структурах данных, но, с другой стороны, еще не сталкивался с языком R. Я познакомлю тебя с ним в том объеме, которого тебе хватит, чтобы комфортно написать, запустить и понять первую программу.
Знакомимся с языком R и готовим рабочее место
Для начала посмотрим, как установить R и как в нем запускать и отлаживать программы, как искать и устанавливать нужные библиотеки (в мире R они называются пакетами), как удобно искать документацию к разным функциям.
Язык R чрезвычайно мощный в том, что касается обработки и анализа данных. Де-факто это стандарт в Data Science. Язык создан математиками-статистиками для математиков-статистиков. В нем, как и в других инструментах, предназначенных для наукоемких вычислений, самый ходовой тип данных — это вектор. Самая популярная структура данных в R — это data frame (срез данных). Срез данных представляет собой матрицу с атрибутами, которая по виду очень похожа на реляционную БД.
IDE для R качай с официального сайта. Доступны версии для трех ОС: Linux, Mac и Windows. Установка должна пройти легко, но если что-то пойдет не так, попробуй первым делом заглянуть в FAQ.
Теперь запускаем IDE. Выглядеть она будет примерно так.
Подсветка синтаксиса здесь, конечно, так себе — вернее, ее вообще нет, — так что код можно спокойно писать в каком-нибудь другом редакторе, а IDE использовать только для запуска уже готового кода. Лично я пишу на R в онлайновом редакторе на rextester.com.
Чтобы установить нужный пакет (библиотеку), используй функцию install.packages. В install.packages есть полезная опция — suggests. По умолчанию ей присвоено значение FALSE. Но если перевести ее в TRUE, install.packages подгрузит и установит все вторичные пакеты, на которые полагается тот пакет, который ты ставишь. Рекомендую всегда устанавливать эту опцию в TRUE, особенно когда начинаешь с чистого листа и только-только (пере)установил R.
Вот тебе для удобства скрипт, который проверяет, установлены ли нужные тебе пакеты. Если какие-то из них не установлены, скрипт подгружает и устанавливает их. Перепечатай и сохрани скрипт в файл update_packages.r. Сейчас он подгружает только два пакета, которые нам понадобятся, когда будем писать детектор спама. По мере необходимости можешь добавлять и другие пакеты.
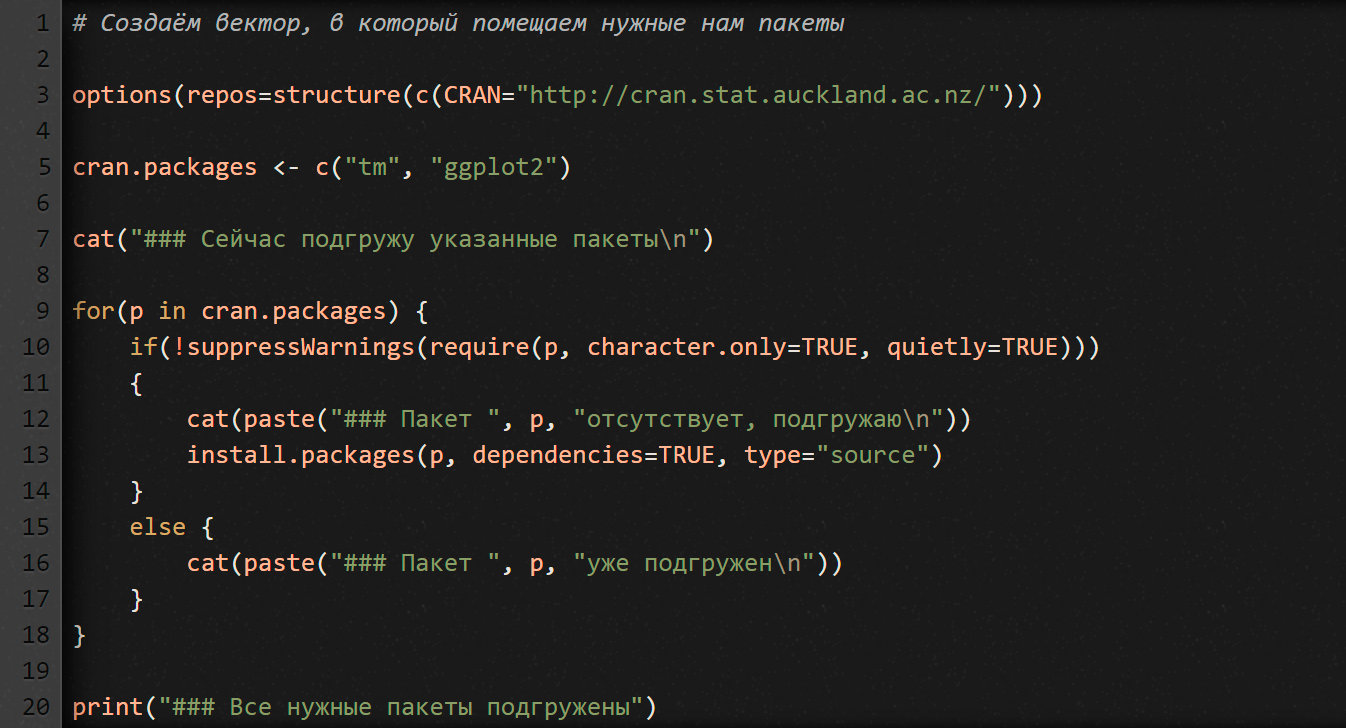
Чтобы выполнить скрипт (и этот, и все остальные, которые ты напишешь), сначала переключи рабочую директорию на ту, куда его сохранил. Для этого введи в консоль R функцию setwd (например, setwd("e:/work/r")). Потом выполни команду source вот таким образом: source("install_packages.r"). Она запустит твой скрипт, и ты увидишь, как подгружаются пакеты, которые у тебя еще не установлены.
Чтобы подключить пакет к программе, используй функцию library или require. Например, library('tm').
Чтобы найти документацию к функции, просто введи в консоли ?xxx, где xxx — имя интересующей тебя функции. IDE откроет в браузере страницу с информацией по этой функции.
Готовим данные
Сначала давай подготовим наборы данных для тренировки и проверки будущего детектора. Предлагаю взять их из архива Apache SpamAssassin. По ссылке ты найдешь подборку писем, расфасованную по трем категориям: spam (собственно, спам), easy_ham (правомерные письма, которые легко отличить от спама), hard_ham (правомерные письма, которые тяжело отличить от спама).
Создай в своей рабочей директории папку data. Перейди в нее и создай в ней еще пять папок:
easy_nonspam_learn,easy_nonspam_verify;spam_learn,spam_verify;hard_nonspam_verify.
По папкам spam_learn и spam_verify распредели по-братски письма из spam. По папкам easy_nonspam_learn, easy_nonspam_verify – из папки 'easy_ham'. В папку hard_nonspam_verify скопируй все письма из hard_ham.
Как ты уже наверно догадался, письмами из папок _learn мы будем тренировать свой детектор отличать спам от не-спама, а письмами из папок _verify – будем проверять, как хорошо он научился это делать.
Но почему тогда мы не создали папку hard_nonspam_learn? Для остроты эксперимента! Мы будем тренировать детектор только теми письмами, которые легко отличить от спама. А в конце посмотрим, сможет ли он узнавать в письмах из категории hard_nonspam правомерную почту без предварительной тренировки.
Как конструируют признаки
Теперь, когда у нас есть исходные данные для тренировки и проверки, нам нужно «сконструировать признаки», которые наш детектор будет выискивать в сырых текстовых файлах с письмами. Умение конструировать признаки — один из базовых навыков в Data Science. Залог успеха здесь — профессиональная интуиция, которая приходит с годами практики. Компьютеры пока еще не могут делать эту работу автоматически, вместо нас. И, скорее всего, никогда не смогут.
С другой стороны, компьютеры могут облегчить нашу работу по конструированию признаков. В частности, у R есть пакет tm (от слов Text Mining), предназначенный для анализа текстов. С его помощью мы подсчитаем, какие слова чаще всего встречаются в спаме и в не-спаме, и будем использовать их частотность в качестве признаков.
Современные детекторы спама делают значительно больше, чем подсчитывание частоты слов, но, как ты скоро убедишься, даже наш простенький детектор будет весьма неплохо отделять спам от не-спама.
В основу нашего детектора положим наивный байесовский классификатор. Логика его работы такая: если видим слово, которое в спаме встречается чаще, чем в не-спаме, то кладем его в копилку спам-признаков. По такому же принципу формируем копилку признаков для не-спама.
Как эти признаки помогут нам отделять спам от не-спама? Мы ищем в анализируемом письме оба вида признаков. Если в итоге получается, что признаков спама больше, чем признаков не-спама, значит письмо спамное, иначе — правомерное.
Вычисляя вероятности того, спам ли наше письмо, мы не учитываем, что какие-то слова могут быть взаимозависимыми. Мы оцениваем каждое слово в отрыве от всех остальных слов. На статистическом сленге такой подход называется «статистической независимостью». Когда математики-статистики исходят из такого предположения, не будучи до конца уверенными в том, что оно здесь правомерно, они говорят: «Наша модель наивная». Отсюда и название: наивный байесовский классификатор, а не просто байесовский классификатор.
Пишем функцию чтения писем из файлов
Сначала подгружаем библиотеки, которые нам понадобятся, и прописываем пути к папкам, в которых хранятся файлы с письмами.
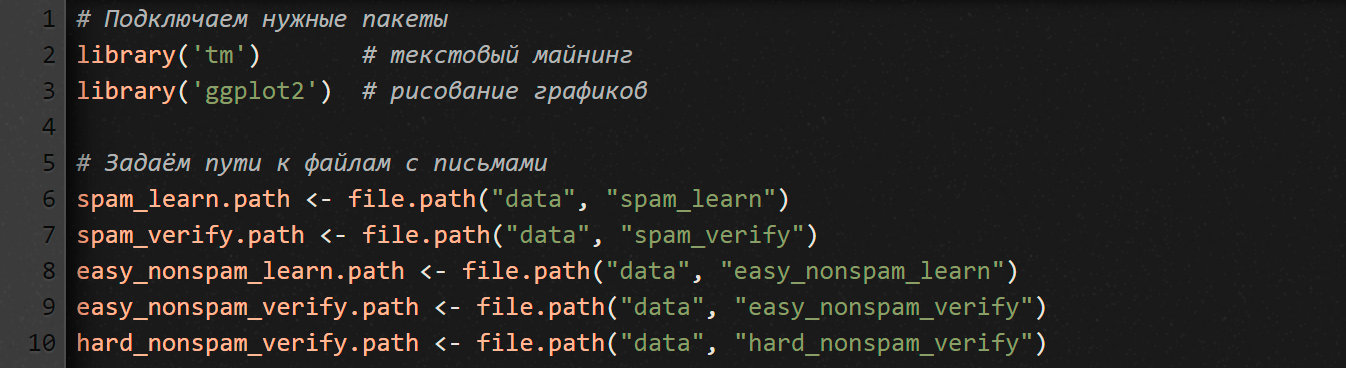
Каждый отдельно взятый файл с письмом состоит из двух блоков: заголовок с метаданными и содержание письма. Первый блок отделен от второго пустой строкой (это особенность протокола электронной почты описана в RFC822). Метаданные нам не нужны. Нас интересует только содержимое письма. Поэтому напишем функцию, которая считывает его из файла с письмом.
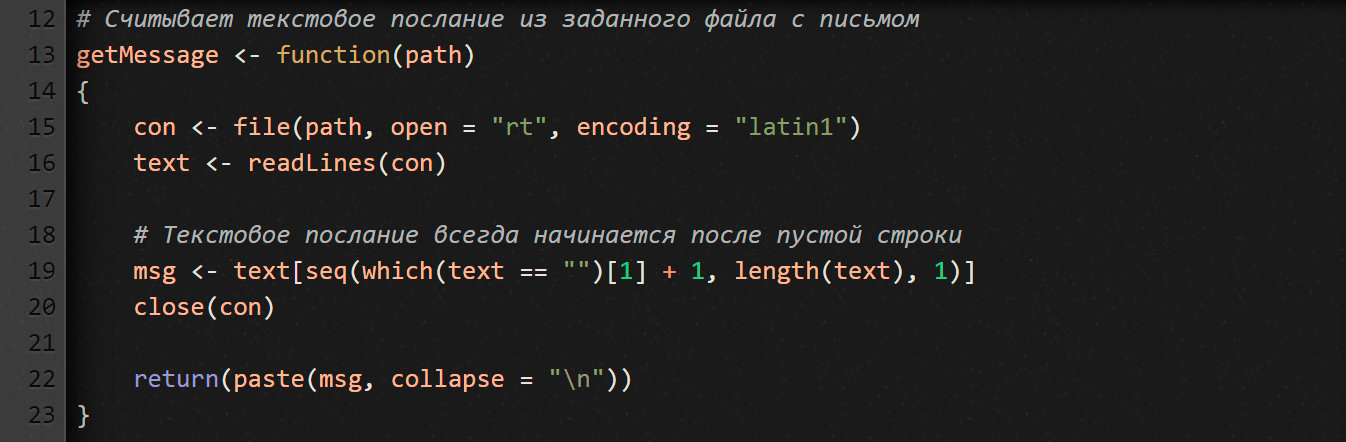
Что мы тут делаем? В языке R файловый ввод/вывод осуществляется точно так же, как и в большинстве других языков программирования. Функция getMessage получает на входе путь к файлу и открывает его в режиме rt (read as text — читать как обычный текст).
Обрати внимание, здесь мы используем кодировку Latin-1. Зачем? Потому что во многих письмах есть символы, которых нет в кодировке ASCII.
Функция readLines считывает текстовый файл построчно. Каждая строка становится отдельным элементом в векторе text.
После того как мы прочитали из файла все строки, ищем первую пустую, а затем извлекаем все строки после нее. Результат помещаем в вектор msg. Как ты, наверно, понял, msg — это и есть содержимое письма, без заголовочных метаданных.
Наконец, сворачиваем весь вектор msg в единый блок текста (см. часть кода с функцией paste). В качестве разделителя строк используем символ \n. Зачем? Так его будет удобнее обрабатывать. И быстрее.
Сейчас создадим вектор, который будет содержать текстовые сообщения из всех спамных писем. Каждый отдельно взятый элемент вектора — это отдельное письмо. Зачем нам такой вектор? Мы будем с его помощью тренировать свой детектор.
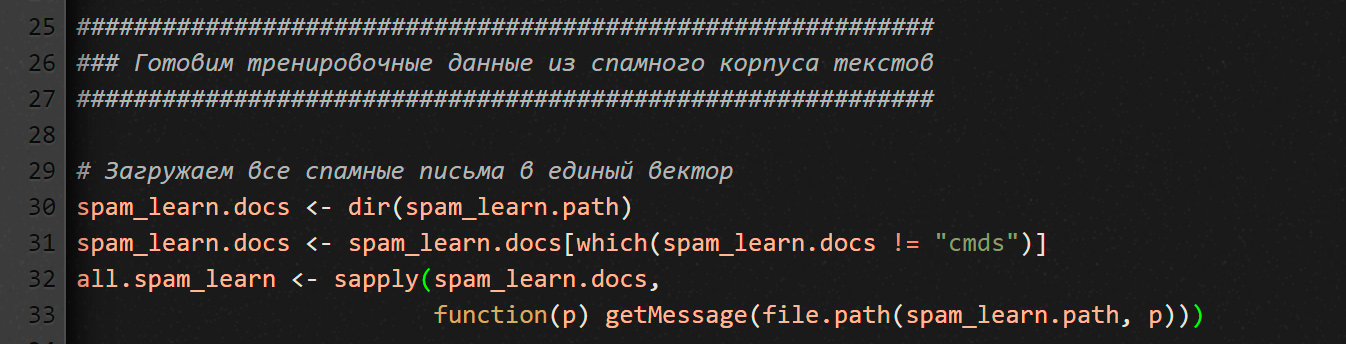
Сначала мы получаем список всех файлов из папки со спамом. Но там, помимо писем, еще хранится файл cmds (служебный файл с длинным списком Unix-команд на перемещение файлов), который нам не нужен. Поэтому вторая строчка из предыдущего фрагмента кода удаляет имя этого файла из итогового списка.
Чтобы создать нужный нам вектор, воспользуемся функцией sapply, которая применит функцию getMessage ко всем именам файлов, которые мы только что получили при помощи dir.
Обрати внимание, здесь мы передаем в sapply безымянную функцию — чтобы объединить имя файла и путь к каталогу, где он лежит. Привыкай, для языка R это весьма распространенная конструкция.
Готовим корпус текстов для спамных писем
Теперь нам надо создать корпус текстов. С его помощью мы сможем манипулировать термами в письмах (в корпусной лингвистике составные части текста, в том числе слова, называют термами). Зачем нам это? Чтобы сконструировать признаки спама для нашего детектора.
Технически это значит, что нам надо создать терм-документную матрицу (TDM), у которой N строк и M столбцов (N – количество уникальных термов, найденных во всех документах; M — количество документов в корпусе текстов). Ячейка [iTerm, jDoc] указывает, сколько раз терм с номером iTerm встречается в письме с номером jDoc.
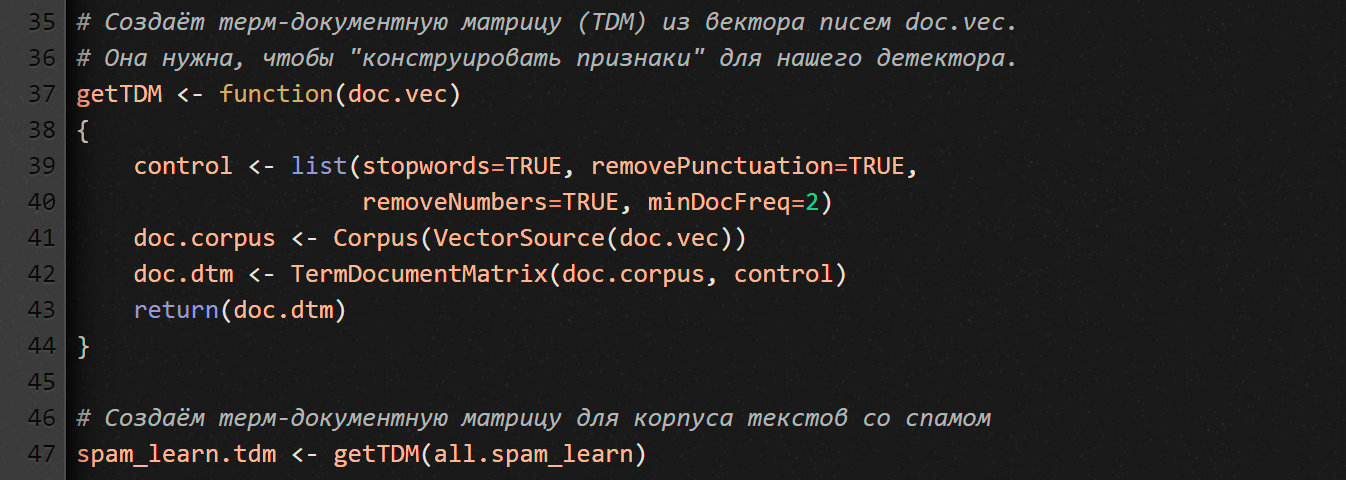
Функция getTDM получает на входе вектор со всеми текстовыми сообщениями из всех спамных писем, а на выходе выдает TDM.
Пакет tm позволяет конструировать корпус текстов несколькими способами, в том числе из вектора писем (смотри функцию VectorSource). Если тебе интересны альтернативные источники, набери в R-консоли ?getSources.
Но прежде чем конструировать корпус, мы должны сказать пакету tm, как надо вычищать и нормализовывать текст. Свои пожелания мы передаем через параметр control, который представляет собой список опций.
Как видишь, мы здесь используем четыре опции.
stopwords=TRUE— не принимать во внимание 488 стоп-слов (распространенные слова английского языка). Чтобы посмотреть, какие слова входят в этот список, набери в консолиstopwords().removePunctuation=TRUEиremoveNumbers=TRUE— говорят сами за себя. Мы их используем для уменьшения шума от соответствующих символов. Тем более что многие наши письма напичканы HTML-тегами.minDocFreq=2— строки в нашей TDM нужно создавать только для тех термов, которые встречаются в корпусе текстов больше одного раза.
Продолжение доступно только участникам
Вариант 1. Присоединись к сообществу «Xakep.ru», чтобы читать все материалы на сайте
Членство в сообществе в течение указанного срока откроет тебе доступ ко ВСЕМ материалам «Хакера», позволит скачивать выпуски в PDF, отключит рекламу на сайте и увеличит личную накопительную скидку! Подробнее
Вариант 2. Открой один материал
Заинтересовала статья, но нет возможности стать членом клуба «Xakep.ru»? Тогда этот вариант для тебя! Обрати внимание: этот способ подходит только для статей, опубликованных более двух месяцев назад.
Я уже участник «Xakep.ru»
