

Машинное обучение — тренд
Когда-то давно я рассказывал, как проходил курс по машинному обучению на Coursera. Курс ведет Andrew Ng, который объясняет все настолько простыми словами, что довольно сложный материал поймет даже не самый усердный студент. С тех пор тема машинного обучения мне стала близка, и я периодически смотрю проекты как в области Big Data (читай предыдущую колонку), так и в области машинного обучения.
Помимо огромного количества стартапов, которые где-то внутри себя используют алгоритмы машинного обучения, уже сейчас доступны несколько сервисов, предлагающие машинное обучение в виде сервиса! То есть они предоставляют API, которым ты можешь воспользоваться в своих проектах, при этом вообще не вникая в то, как осуществляется анализ и предсказание данных.
Google Prediction API
Одним из самых первых предлагать Machine Leaning as a Service стал Гугл! Уже довольно долгое время любой желающий может воспользоваться Google Prediction API (дословно «API для предсказаний»). До определенного объема данных использовать его можно абсолютно бесплатно, просто заведя аккаунт на Google Prediction API. О каких предсказаниях идет речь? Задача может быть разная: определить будущее значение некоего параметра на базе имеющихся данных или определить принадлежность объекта к какому-то из типов (например, язык текста: русский, французский, английский).
После регистрации у тебя появляется доступ к полноценному RESTful API, на базе которого можно построить, скажем, рекомендательную систему, детектирование спама и подозрительной активности, анализа поведения пользователей и многое другое. Уже успели появиться интересные проекты, построенные на базе интенсивного использования Google Prediction API, например Pondera Solutions, который использует машинное обучение от Гугла для построения системы антифрод.
В качестве эксперимента можно взять готовые модели данных: идентификаторов языка для построения системы, определяющих, на каком языке написан входящий текст, или идентификаторов настроения, чтобы автоматически определить тональность комментариев, которые оставляют пользователи. Думаю, в будущем мы расскажем о Google Prediction API подробнее.
BigML
Сегодня же хочу коснуться другого похожего проекта, который попался мне на глаза относительно недавно, — BigML. По сути, он предоставляет ровно тот же самый Rest API для собственного ML-движка, но с одним важным для новичка плюсом — наличием довольно наглядного интерфейса. А последний факт сильно упрощает задачу старта, когда нужно с нуля разобраться, что к чему.
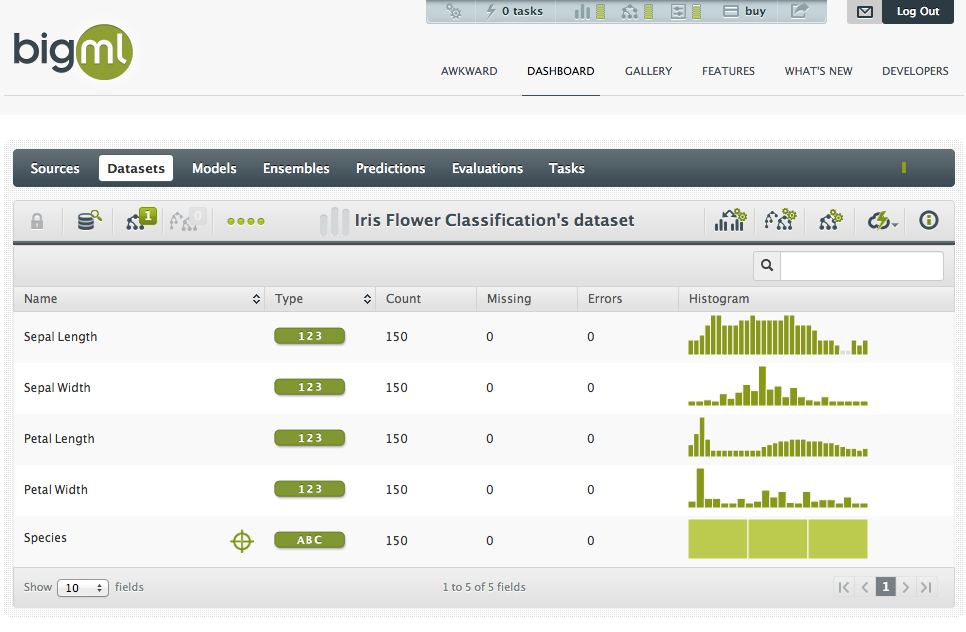
Разработчики сделали все, чтобы с системой могла справиться домохозяйка. После регистрации к твоим услугам несколько примеров исходных данных, в том числе часто используемый в учебниках набор данных «Ирисы Фишера», который считается классикой для решения задачи по классификации. В набор описывается 150 экземпляров цветка ириса трех разных видов, с описанием характеристик. На базе этих данных можно построить систему, которая будет определять принадлежность цветка к одному из видов по введенным параметрам.
Эксперимент
Все действия выполняются в понятной админке (не стану описывать нюансы, все будет предельно доступно).
- Выбираем CSV-файл, в котором хранятся строчки, описывающие характеристики разных видов цветков, как источник данных (Source).
- Далее используем эти данные для построения набора данных (Dataset), указав, что предсказывать нужно будет тип цветка. BigML автоматически распарсит файл и, проведя анализ, построит различные графики, визуализируя данные.
- На базе этого Dataset’а одним кликом строится модель, на которой будут основываться предсказания. Причем BigML опять же визуализирует модель, объясняя логику ее работы. Можно даже экспортировать результат в виде скрипта для Python или любого другого языка.
- После того как модель готова, появляется возможность делать предсказания (Predictions). Причем делать это в разных режимах: сразу задать все параметры цветка или же отвечать на вопросы системы, которая, исходя из ситуации, будет спрашивать только то, что ей нужно.
То же самое можно было бы провернуть и без UI, а общаясь с BigML через консольное приложение BigMLer или через REST API, общаясь из консоли обычным curl’ом.

Хакер #179. Интернет вещей — новый вектор атак
Две главные задачи
Внутри BigML и Google Prediction API ничего сверхъестественного нет. И неглупые разработчики смогут реализовать аналогичные движки самостоятельно, дабы не платить сторонним сервисам (и не выгружать им данные, которые часто нельзя выгружать).
И все-таки сервисы решают как минимум две очень важные задачи. Во-первых, они способны буквально за вечер дать человеку понять, что машинное обучение — это не только круто и трендово, но и во многих ситуациях довольно просто. А во-вторых, с их помощью можно быстро набросать прототип новой фичи для своего приложения или сервиса и проверить идею практически без трудозатрат.










