

Содержание статьи
Системы мониторинга ежесекундно собирают тысячи параметров с сотен систем, визуализируя данные в виде графиков и предупреждая админа о превышении установленного значения. Но преодоление порога не всегда означает проблему, оно может быть вызвано рядом факторов. Причем нагрузочное тестирование отличается от действий реальных пользователей весьма серьезно. Увидеть зависимости в большом числе таблиц и графиков практически нереально, как и установить правильное значение порогов для метрик.
Проблемы мониторинга сложных сетей
Для мониторинга IT-инфраструктуры разработано множество инструментов, в том числе и под open source лицензиями: Nagios, клоны Shinken и Icinga, StatsD, Zabbix, Cacti и другие. Очевидные проблемные ситуации, такие как загрузка CPU или RAM, свободное место на харде, дисковые операции, просты в понимании, легко отслеживаются при помощи установленных порогов, корректируемых для каждого конкретного случая, в том числе и по результатам нагрузочного тестирования. Получаемые графики наглядны, и такой способ покрывает большинство потребностей и рекомендуется как единственный. Но сегодня системы очень сложны, и, главное, их количество растет. На сервере могут работать сотни виртуальных машин, обменивающихся информацией с другими, и поэтому проблема, снижающая производительность, часто неочевидна, а алерты молчат. Количество метрик уже исчисляется сотнями, настройка и подстройка их всех требует времени. И главное — чтобы уследить за ними всеми, требуется уже серьезная команда.
Но это еще не все. Реальная модель поведения пользователя отличается от идеальной, заложенной разработчиками приложения, которую можно проверить под нагрузкой и прописать в шаблоны мониторинга. Построенные на правилах оповещения являются пороговыми, то есть мы получаем предупреждение, когда уже что-то произошло и нужно срочно принимать меры. Их статичный характер приводит к тому, что нередко выдаются ложные срабатывания (false positives) во время пика нагрузки и пропускаются знаковые события (false negatives) в обычной работе.
В итоге для того, чтобы найти проблему, нужно отследить не только множество данных, но и зависимости, полученные из нескольких источников в течение продолжительного времени, показывающих значение в пределах допустимого порога (то есть обычно выпадающих из зоны внимания). Вручную сделать это просто нереально, придется обработать большое количество данных, не зная, что искать и как должен выглядеть результат. Здесь уже придется задействовать автоматизацию, использующую разные математические модели, которые помогают обнаружить опасные ситуации до того, как они стали критическими.
Из чего выбираем
Средства обнаружения аномалий в поведении приложений развивались двумя способами: одни анализировали события в журнале (есть ли подозрительные записи) или считывали цифры, другие использовали метрики, полученные от различных инструментов мониторинга. Но общий принцип их работы прост. Чтобы понять закономерности поведения, предсказывается вероятный диапазон будущих значений; если оно не совпадает с текущим, регистрируется аномалия. Также используются различные формы прогнозирования, обеспечивающие точность результатов и предсказание состояния системы. Сегодня уже доступно несколько рабочих решений, легко подхватывающих любую сеть, адаптирующихся к изменениям среды и не требующих длительного обучения.
Anomaly Detective — универсальный инструмент, способный обрабатывать любые данные и обнаруживающий любые изменения, указывающие на проблемы с производительностью или безопасностью, не требует предварительной настройки. Информацию получает из лог-файлов, результат выводится в виде внятных графиков и оповещений. Предлагаемый API REST позволяет получать данные из любого источника.
Дополнительно предлагается Anomaly Detective Application for Splunk Enterprise, который расширяет стандартные поисковые запросы этой платформы новыми алгоритмами, выявляющими аномалии. Ставится Anomaly Detective на Win, Linux, OS X и SunOS, развертывание относительно просто, и с ним справится новичок. Прайс зависит от объема данных. Доступна триал-версия.
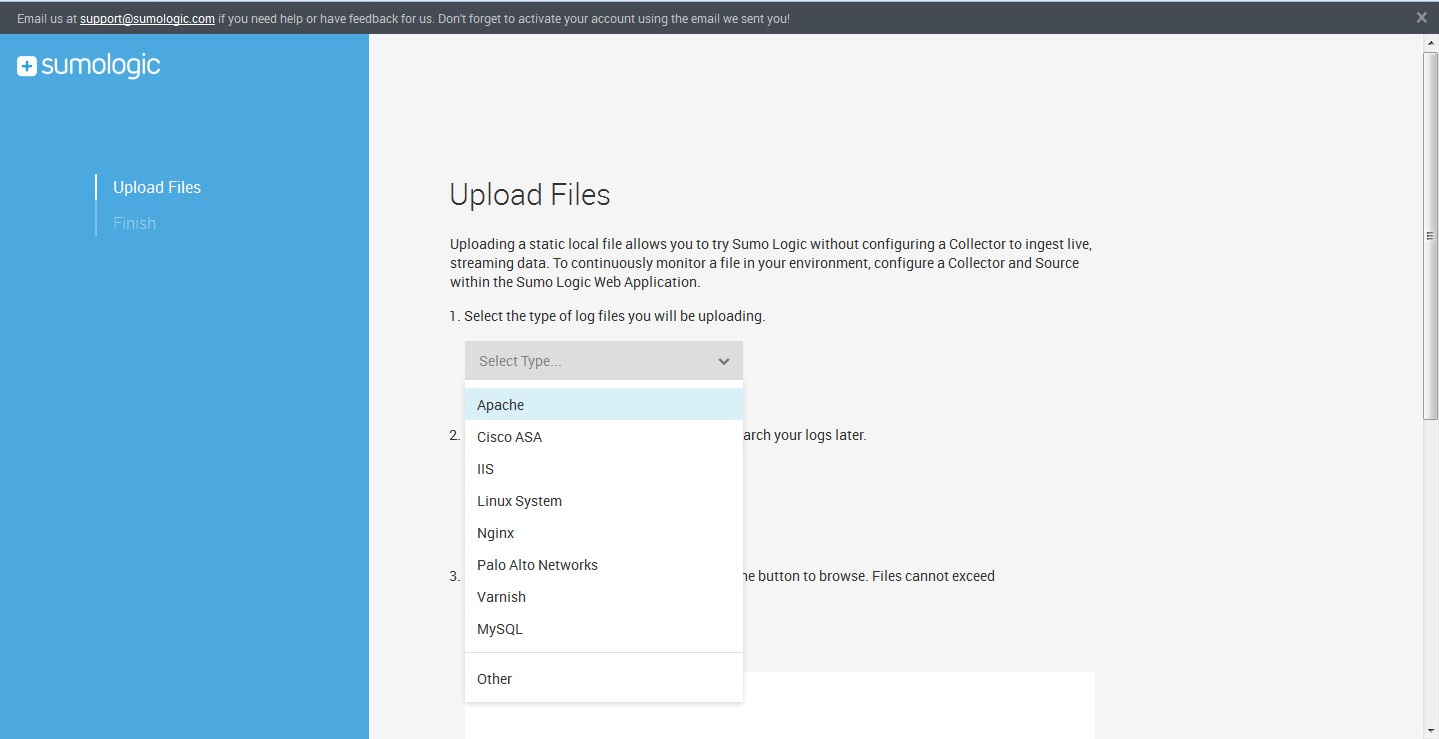
Sumo Logic реализован в виде SaaS, позволяющего собирать, накапливать и анализировать информацию от журналов различных источников. Внешне похож на подобные сервисы агрегации журналов, но специальный механизм LogReduce умеет объединять повторяющиеся позиции, уменьшая количество данных. Поверх LogReduce реализовано решение, обнаруживающее аномалии. Для этого вначале сканируются собранные данные и создается профиль нормальной работы системы, после чего система отслеживает отклонения и если их обнаруживает, то выдает предупреждения, графики и, главное, внятные комментарии.
Технология Predictive Analytics расширяет систему обнаружения аномалий, строя прогнозы будущих нарушений на основе текущего поведения системы, и дает возможность увидеть проблемы до того, как они наступят. Обеспечивается должный уровень конфиденциальности, данные шифруются.

Xakep #200. Тайная жизнь Windows 10
Реализация в виде SaaS снимает необходимость в организации бэкапа собранных данных, все эти вопросы реализованы на стороне сервиса. Как большой плюс можно отметить возможность просто загрузить офлайн-файлы журналов для последующего анализа алгоритмами Sumo Logic. Есть версия Free, дающая возможность использовать бесплатно сервис при трафике до 500 Мбайт в день, чего хватает для небольших проектов. Развертывание в общем несложно, на системы устанавливаются коллекторы (доступны пакеты для Linux, Win, OS X и Solaris), которые подключаются к серверу. С учетом триал-периода, это позволяет быстро оценить свои сайты и попробовать найти проблему.
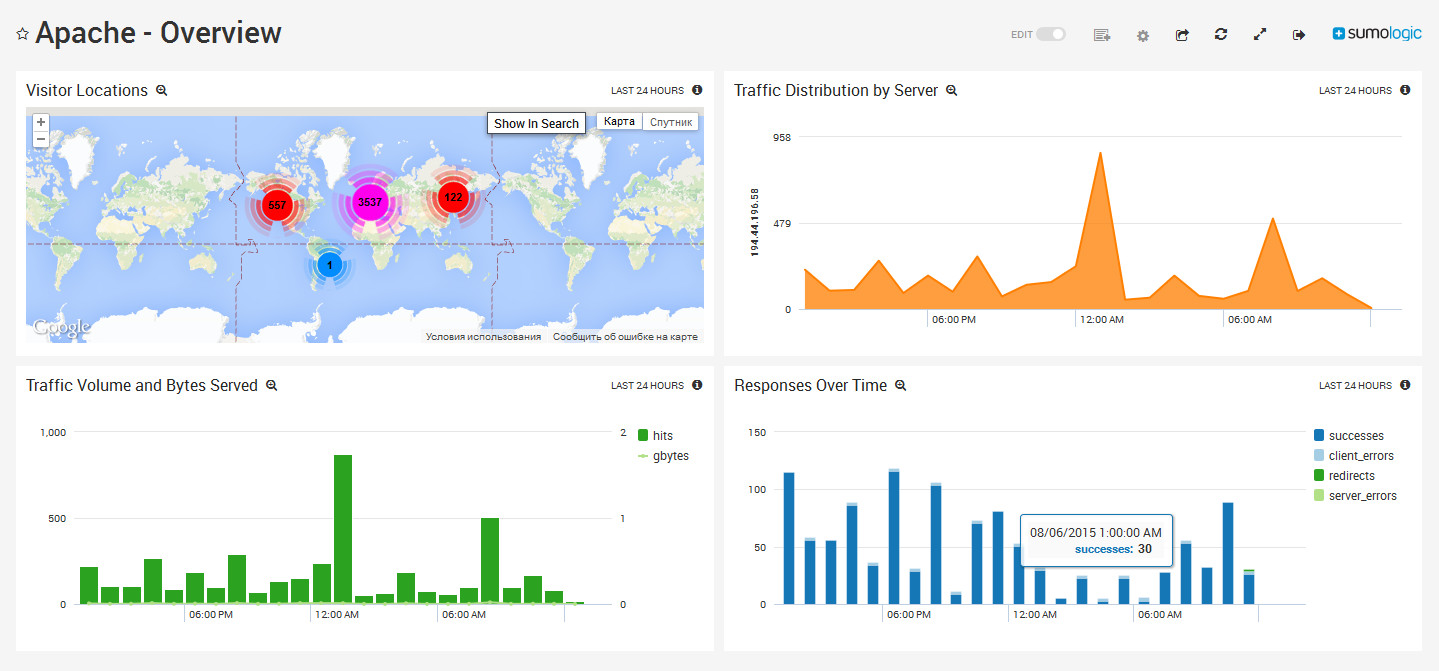
Grok — продукт, представляющий собой коммерческую версию и дальнейшее развитие open source проекта NuPIC компании Numenta. Предназначен для обнаружения аномалий в AWS, работает со всеми веб-сервисами Amazon: EC2, EBS, ELB, RDS и другими. Для анализа используются системные метрики Amazon CloudWatch, на основе которых строятся модели нормальной работы системы, администратору показываются гистограммы для визуализации уровня аномалий, раскрашенные в зависимости от ситуации: зеленый — все хорошо, красный — есть проблемы.
Кроме этого, с его помощью можно отследить тенденции и устранить проблему до ее появления. Можно настроить уведомления на почту или СМС. В качестве основного интерфейса используется мобильный клиент для устройства на базе Android. Для контроля двухсот метрик продукт можно использовать бесплатно. Поддерживается только *nix. Установка и конфигурация проста, он есть на Amazon Marketplace. Для установки потребуется учетная запись на AWS.
Как видишь, все проекты требуют некоторых вложений, а бесплатные ограничены трафиком, но выход есть.
Проект Kale
Компания Etsy, столкнувшаяся с задачей мониторинга большого количества систем, разработала open source решение Kale (некоторое время проект назывался Loupe, но это имя оказалось занято, и название было изменено), позволяющее на основе собранной статистики найти аномалию без необходимости настройки порогов для метрик. Предназначен для использования в системах с большим количеством параметров, требующих постоянного наблюдения. Идея расписана в статье Introducing Kale: вначале создается модель нормального поведения системы, затем статистический анализ определяет отклонения в этой модели и показывает коррелированные результаты, поясняя причину. Написан на Python, код открыт, поэтому многие компоненты легко поддаются изменению.
Kale состоит из двух частей, которые могут использоваться независимо. Основной компонент, Skyline, собственно, и предназначен для автоматического обнаружения аномалий, без необходимости установки метрик и порогов. Он просто получает данные с системы мониторинга (теоретически и любых других) и анализирует при помощи сразу нескольких алгоритмов, что само по себе составляет важную особенность этого проекта. Если обнаружится ненормальное поведение, администратору будет показан список метрик и связанные графики, при помощи простого интерфейса их можно отбирать и изучать. При необходимости в процедуру отслеживания легко добавить новые метрики или изменить алгоритмы.
Дополнение Skyline Oculus используется как компонент корреляции метрик в найденных Skyline аномалиях. Достаточно выбрать в веб-интерфейсе Skyline нужную метрику, и Oculus покажет все коррелирующие с ней метрики. Для поиска исходные данные нормализуются и кодируются, в итоге получается некий отпечаток, показывающий ход графика, закодированный при помощи пяти ключевых слов: sdec (резко вниз), dec (вниз), s (ровно), inc (вверх), sinc (резко вверх). Производится поиск по отпечатку, далее при помощи одного из двух алгоритмов сравнения (FastDTW или Euclidian) отбираются схожие результаты. Естественно, возможно использовать оба алгоритма и сравнить результаты. Полученным данным можно дать описание, можно сохранить их, исключить ненужное при помощи фильтра, сгруппировать в коллекцию. Коллекции позволяют повторно использовать информацию о ранее найденных проблемах, если они появятся вновь, без необходимости разбираться, что к чему.
Для поиска аномалий достаточно на первых порах развернуть только Skyline, многие довольствуются им одним. Но при необходимости впоследствии можно добавить и Oculus.
Компоненты Skyline
Сам Skyline состоит из нескольких компонентов. За сбор данных отвечает Horizon, который при помощи Listeners принимает входные данные в двух форматах: pickle (TCP) (адаптирован под сервис carbon-relay из Graphite, по умолчанию 2024-й порт) и UDP MessagePack. Так как не все системы мониторинга поддерживают эти протоколы, используется в качестве основной следующая схема. Данные с коллекторов (вроде collectd, diamond, statsd) или систем мониторинга (Nagios, Icinga, Zabbix, Sensu...) передаются в Graphite, затем carbon-relay перенаправляет их в Skyline. Далее они упаковываются с помощью MessagePack и заносятся в базу данных Redis — еще один компонент Skyline.
Поддержку MessagePack можно легко реализовать на любом языке для любой платформы мониторинга, поэтому подключить новый источник не проблема, как и добавить свой Listener (файл listen.py). Некоторые подробности по настройке смотри в Getting Data Into Skyline. Чтобы не забивать базу ненужной информацией, можно настроить фильтры и игнорировать ненужные метрики. Также Horizon Agent периодически самостоятельно очищает базу данных от устаревших метрик.
За анализ данных отвечает компонент Analyzer. Во время работы он получает метрики с Redis, далее запускается несколько процессов, которым назначаются определенные метрики. Проверка — функция ресурсозатратная, ведь нужно распаковать MessagePack и проанализировать, поэтому есть возможность указать количество процессов (по умолчанию ANALYZER_PROCESSES = 5 в файле settings.py). Анализ производится при помощи нескольких алгоритмов, выдающих каждый свой результат. Если большинство алгоритмов покажет, что обнаружена аномалия, то метрика будет считаться аномальной, сохранится в файл и выведется в виде картинки в веб-интерфейсе.
Кроме этого, можно задать предупреждение, в данный момент доступны SMTP, HipChat и PagerDuty. При необходимости администратор может изменить порог, указав число алгоритмов, положительный результат которых будет показывать аномалию, а также отключить лишние проверки, добавить новые алгоритмы или изменить работу имеющихся. Все алгоритмы описаны в файле algorithms.py, в настоящее время их девять (first_hour_average, mean_subtraction_cumulation, stddev_from_average, stddev_from_moving_average, least_squares, grubbs, histogram_bins, median_absolute_deviation, ks_test), по умолчанию порог срабатывания установлен в шесть (CONSENSUS = 6).
Возможны варианты, когда алгоритмам не хватает данных или данные давно не обновлялись, поэтому, кроме аномалий, администратор может получать соответствующие сообщения.
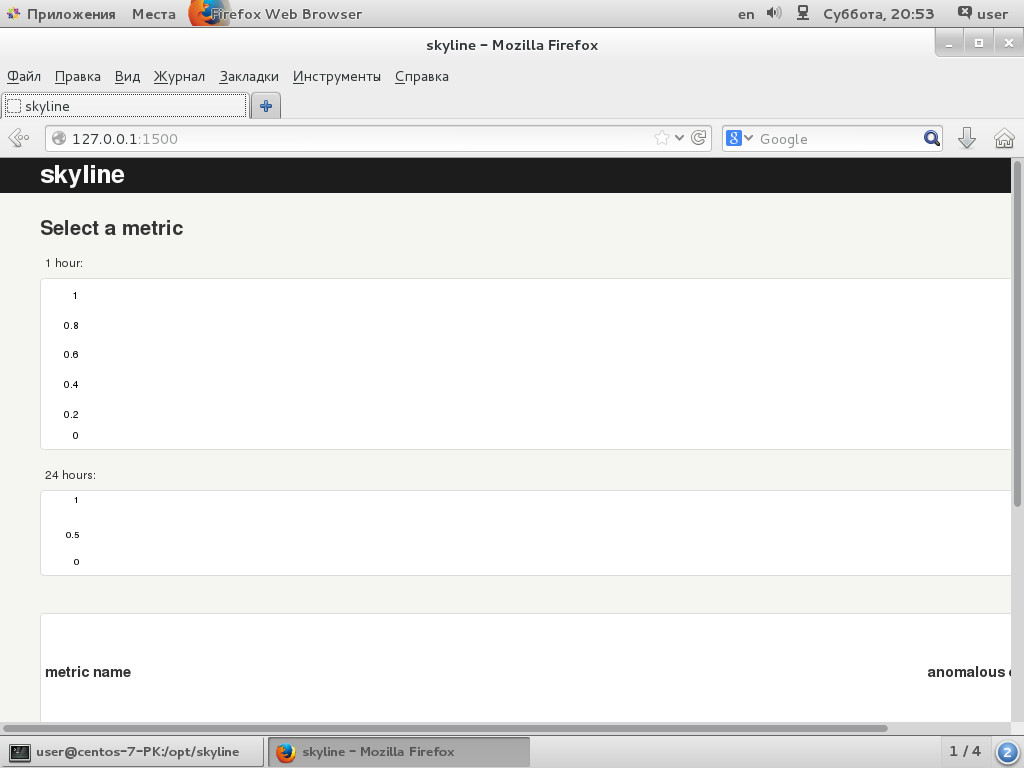
В качестве интерфейса webapp для вывода графиков используется небольшое веб-приложение, написанное на Python с микрофреймворком Flask. По умолчанию работает на 127.0.0.1:1500. Интерфейс очень прост. Вверху отображаются два графика — за час и день, ниже выводится список всех аномальных метрик. При наведении курсора на метрику графики показывают нужный участок. При щелчке открывается окно Oculus.
Установка Skyline
Развертывание Skyline совсем простым назвать нельзя. Проект предоставляет доступ к исходным кодам, общую инструкцию, а также краткие советы по установке в Debian и Vagrant. Также есть проекты, предлагающие модули Puppet и Cookbooks Chef. Поэтому придется немного повозиться, разбираясь с мелочами. Для примера установим Skyline на CentOS 7, в других дистрибутивах процесс в основном схож и будут отличаться только названия пакетов. Для упрощения будем считать, что система развернута, настроены сервисы мониторинга вроде collectd, Nagios и система отрисовки графиков Graphite. Для установки понадобятся права админа, я использую sudo:
$ sudo yum install httpd gcc gcc-c++ git pycairo mod_wsgi python-pip python-devel blas-devel lapack-devel libffi-develПолучаем код Skyline c GitHub:
$ cd /opt
$ sudo git clone https://github.com/etsy/skyline.git
$ cd skylineСтавим рекомендуемые пакеты для Python:
$ sudo pip install -U sixРазработчики подготовили файл requirements.txt, внутри закомментирован модуль python-simple-hipchat, если HipChat планируется к использованию, нужно убрать решетку, хотя можно поставить и потом.
$ sudo pip install -r requirements.txtЗатем доустанавливаем еще Python-пакеты (numpy, scipy, pandas, patsy, statsmodels, msgpack-python). Через pip их сборка займет некоторое время, но часть есть в репозитории:
$ sudo pip install patsy
$ sudo pip install statsmodels
$ sudo yum install python-numpy python-scipy python-pandas python-msgpackВ поставке идет готовый конфигурационный файл, копируем с новым именем:
$ sudo cp /opt/skyline/src/settings.py.example /opt/skyline/src/settings.pyВсе параметры расписывать нет смысла, внутри несколько секций, одни настройки понятны и без объяснений, другие расписаны выше, часть трогать вообще не нужно. Пока нужно указать IP всех компонентов:
GRAPHITE_HOST = '127.0.0.0'
HORIZON_IP = '0.0.0.0'
WEBAPP_IP = '192.168.1.2'По умолчанию webapp доступен только с локального узла, можно это изменить:
WEBAPP_IP = '0.0.0.0'
WEBAPP_PORT = 1500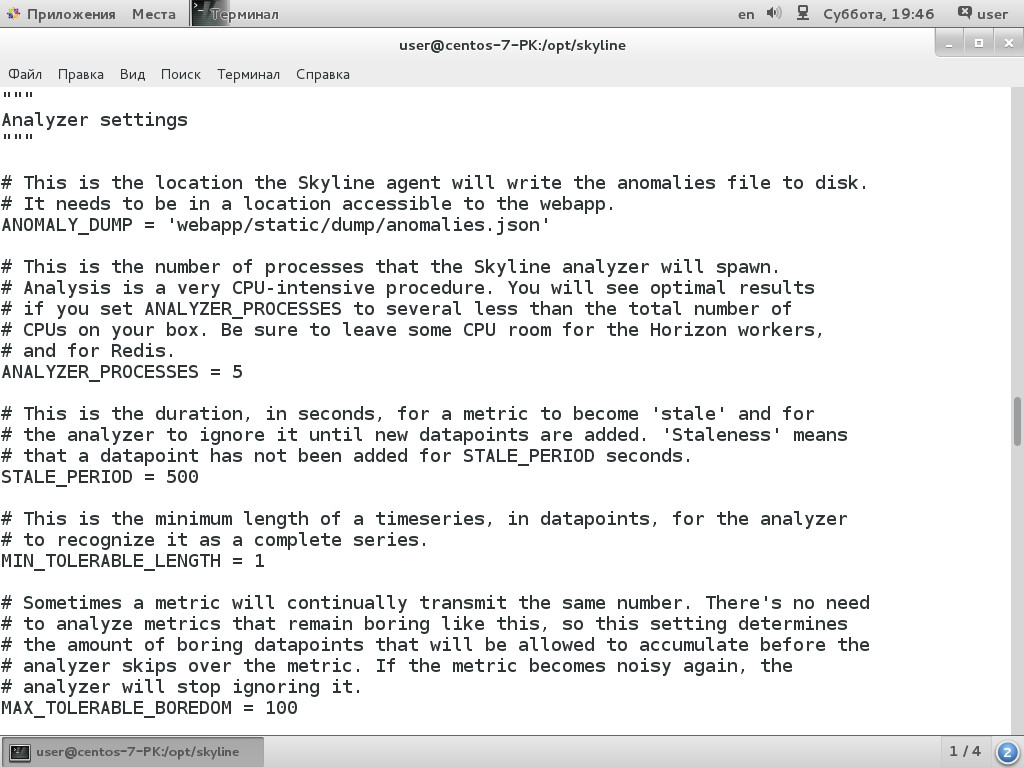
Создаем рабочие каталоги:
$ sudo mkdir /var/log/skyline
$ sudo mkdir /var/run/skyline
$ sudo mkdir /var/log/redis
$ sudo mkdir /var/dump/Ставим Redis:
$ sudo yum install redisЗапускаем компоненты Skyline и Redis:
$ cd /opt/skyline/bin
$ sudo redis-server redis.conf
$ sudo /opt/skyline/bin/horizon.d start
$ sudo /opt/skyline/bin/analyzer.d start
$ sudo /opt/skyline/bin/webapp.d startВ поставке есть скрипт, позволяющий проверить правильность работы Skyline:
$ python /opt/skyline/utils/seed_data.pyЕсли не получаем ошибок, значит, все нормально. Если ошибка, то придется разбираться, так как явно есть проблема. Иногда мешает firewall, на время экспериментов его можно отключить, затем разрешить подключение к определенным портам (сarbon-relay принимает данные на порт 2013, сarbon-cache слушает 2004, а Horizon — 2024). Базовая установка закончена, теперь нужно подать информацию в Skyline. Иногда ответ дает прослушка портов с tcpdump.
В поставке Graphite есть готовый конфигурационный файл для carbon-relay:
$ sudo cp /opt/graphite/conf/relay-rules.conf.example /opt/graphite/conf/relay-rules.confНеобходимо прописать внутри IP сервера Skyline:
$ sudo nano /opt/graphite/conf/relay-rules.conf
[default]
default = true
destinations = 127.0.0.1:2004, 192.168.1.2:2024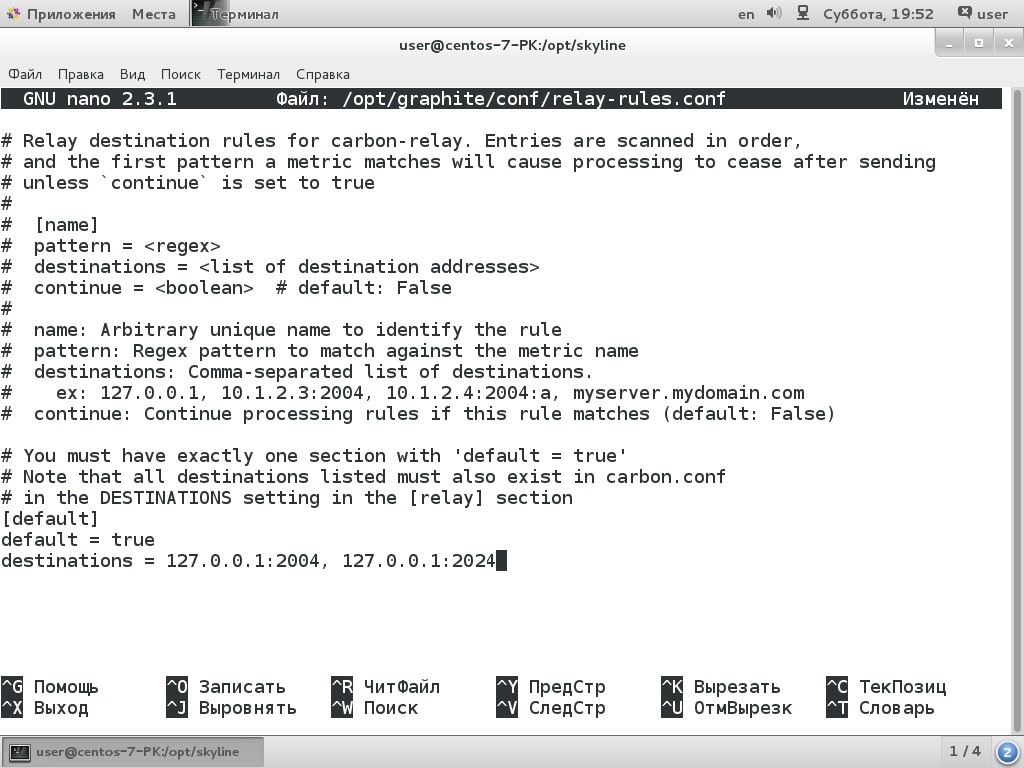
Эти же данные указываем в carbon.conf, раскомментировав строчку DESTINATIONS:
$ sudo nano /opt/graphite/conf/carbon.conf
[relay]
...
DESTINATIONS = 127.0.0.1:2004, 192.168.1.2:2024
...Перезапускаем сервис carbon-relay:
$ sudo systemctl restart carbon-relayТеперь можем подключиться браузером к порту 1500 сервера Skyline http://192.168.1.2:1500 и получим доступ к веб-странице. Первые графики могут появиться в течение часа, лучше в это время не сильно нагружать систему, чтобы был создан нормальный профиль. На полную Skyline заработает через сутки (FULL_DURATION = 86 400 с).
Заключение
В последнее время растет объем данных, анализ которых стандартными средствами практически невозможен. Но пока системы обнаружения аномалий не стремятся полностью заменить традиционные, использующие пороги и правила. Те вполне справляются с большинством задач, и их применение обкатано годами, к тому же они имеют низкий процент ложных срабатываний, чем пока не может похвастаться Kale и другие подобные решения. Но в определенных обстоятельствах это незаменимое дополнение к уже существующим средствам мониторинга. Тем более их внедрение не требует больших усилий, а эффект применения очень высок.












