Содержание статьи
Достаточно часто случается так, что затраты на хостинг проекта больше, чем все прочие расходы на его содержание. Особенно это касается тех проектов, которые активно используют Amazon AWS. Но далеко не все знают, что Amazon предоставляет различные средства для того, чтобы позволить своим клиентам платить за пользование сервисами AWS меньше.
Что такое Auto Scaling и как он работает
Auto Scaling — это технология от Amazon, которая позволяет увеличивать/уменьшать количество твоих инстансов в EC2 в зависимости от заданных тобой условий: нагрузки на инстансы, объема трафика и прочего. Таким образом, ты всегда сможешь быть уверен в том, что твой проект будет продолжать свою работу даже при резком росте трафика, а в случае минимального количества посетителей ни один цент не будет потрачен впустую на оплату неиспользуемых мощностей.
Итак, основные преимущества использования Auto Scaling заключаются в следующем:
- Меньше вреда от некорректно работающего инстанса. Auto Scaling может определять неисправный инстанс, удалять его и запускать новый на замену удаленному.
- Схема работы проекта будет более отказоустойчивой. Auto Scaling можно сконфигурировать на использование нескольких подсетей или Availability Zones. Таким образом, если одна подсеть или Availability Zone станет недоступна, Auto Scaling начнет создавать инстансы в другой для того, чтобы проект был доступен извне.
- Увеличение и уменьшение количества используемых инстансов по мере необходимости. Немаловажен тот факт, что плата за использование Auto Scaling не взимается, ты платишь лишь за те инстансы EC2, которые были запущены.
Как вообще работает Auto Scaling? Типовой пример изображен на рисунке.
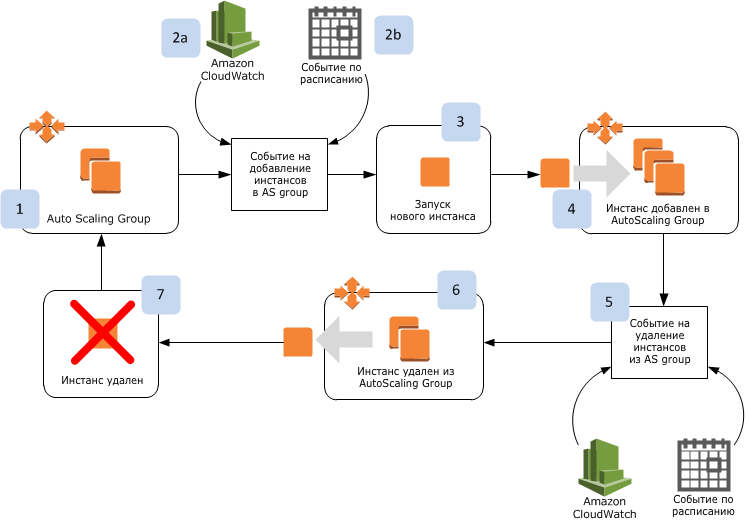

Мы начинаем с Auto Scaling Group, у которой желаемое количество инстансов выставлено в 2. Происходит событие на добавление инстансов в Auto Scaling Group. В рамках этого события Auto Scaling получает инструкции на запуск нового инстанса. Данное событие может либо быть запланированным согласно расписанию, либо возникать по результатам срабатываний CloudWatch-событий. После этого новый инстанс создается, конфигурируется и добавляется в Auto Scaling Group. Процедура инициации удаления инстанса происходит точно так же — она срабатывает либо по расписанию, либо на основе метрик CloudWatch.
Углубление в детали
С услугой Auto Scaling тесно связаны такие три понятия, как Groups, Launch Configurations и Scaling Plans. Разберем их подробнее.
В Auto Scaling Groups объединяются инстансы, выполняющие одинаковые функции (например, только www-инстансы или только MySQL) с целью управления ими и увеличением/уменьшением их количества. То есть если твоему приложению для достижения максимальной производительности необходимо увеличить количество инстансов того или иного типа, это делается в настройках соответствующей Auto Scaling группы. Ты можешь делать это вручную, а можешь задать некоторый набор условий, согласно которым инстансы будут добавляться/удаляться, и тогда количество запущенных инстансов будет регулироваться автоматически. Как уже упоминалось выше, Auto Scaling умеет проверять «здоровье» каждого инстанса. Если, по мнению Auto Scaling, инстанс из какой-либо Auto Scaling группы окажется «нездоров», то он будет уничтожен и будет создан новый инстанс ему на замену.
Launch Configuration — это совокупность параметров (таких как ID образа, тип инстанса, SSH-ключи, группы безопасности и маппинг блочных устройств), однозначно описывающих конфигурацию инстанса, который необходимо создавать при использовании данной Launch Configuration. Когда ты создаешь Auto Scaling группу, тебе необходимо связать ее с одной из существующих Launch Configuration. Достаточно важный момент: Launch Configuration нельзя изменять после создания. То есть если тебе необходимы новые инстансы с какими-то новыми параметрами (например, переделанный AMI), то необходимо создать новую Launch Configuration. После чего ты указываешь новую Launch Configuration в настройках Auto Scaling группы, и новые инстансы будут создаваться с новыми настройками. Старые инстансы изменены не будут.
А с помощью Scaling Plan можно указать Auto Scaling, при каких условиях нужно создавать дополнительные инстансы / удалять лишние существующие.
Использование Auto Scaling
Не стоит думать, будто использование Auto Scaling для проекта — это еще один шаг в сторону увольнения штатного системного администратора :). На самом деле есть и специфичные для Auto Scaling’a проблемы. Вот часть из тех, с которыми мы столкнулись:
- Чересчур долгие периоды удаления старых записей из ARP-кеша у тех инстансов, которые взаимодействуют с Auto Scaling инстансами. Значения по умолчанию были для нас слишком велики. Выражалось это в итоге вот в чем: Auto Scaling инстанс с IP 10.0.1.100 был удален двадцать минут назад. В ARP-кеше на MySQL-сервере осталась запись, где IP 10.0.1.100 однозначно привязан к некоторому MAC-адресу. Пять минут назад был создан новый Auto Scaling инстанс с IP 10.0.1.100, но с другим MAC-адресом. Догадываешься, что получилось в итоге? Правильно, из-за того, что ARP-кеш на MySQL-сервере своевременно не обновился, у нас отсутствовала связь между www и MySQL — так как с MySQL-сервера пакеты уходили на старый MAC-адрес. Решилось это правкой настроек, уменьшением тайм-аутов на очистку ARP-кеша, но ситуация все равно была неприятная.
- Время создания автоскейлов должно быть минимальным. В этом очень сильно помогает создание Launch Configuration на базе преконфигуренного AMI. Из нашей практики: на достаточно крупных проектах имеет смысл создавать AMI, которые будут содержать не только соответствующим образом настроенное ПО, но и последнюю ревизию кода. Это позволит Auto Scaling инстансу принимать и обрабатывать запросы от посетителей буквально сразу же после загрузки операционной системы. Если же время создания автоскейла достаточно велико и занимает порядка пяти-десяти минут, то это может негативно сказаться на производительности проекта. Особенно когда только что стартовала рекламная кампания клиента, которая дала поток посетителей, втрое превышающий норму на этот день недели и это время.
- Точная настройка условий, при которых будет создан новый Auto Scaling инстанс. В первое время работы с Amazon Auto Scaling мы столкнулись с проблемой: выяснялось, что созданные нами условия, по которым Amazon определял необходимость создания новых автоскейлов, хоть и выглядят верными, но на самом деле далеки от реальности. Мы не учитывали, сколько времени уходит на создание одного инстанса, за какое время нагрузка на существующие инстансы прыгала от «выше среднего» до «сверхвысокая», и еще некоторые мелкие детали. В результате — шлифовка корректных условий для Auto Scaling заняла у нас несколько дней.
Эти проблемы были самыми основными. Порой случаются мелкие, но досадные казусы, например, недавно не сразу смогли собрать новый AMI с некоторыми изменениями из-за проблем на стороне API Amazon, что задержало выкладку новой версии продукта в production.
При использовании Auto Scaling достаточно важным остается такой момент, как мониторинг всего и вся на созданных автоскейлах. Причем крайне важно, чтобы инстансы подключались к мониторингу автоматически сразу после создания: при высоких величинах посещаемости проекта за день может быть создано/удалено порядка нескольких десятков автоскейлов, добавлять их все в мониторинг вручную будет сложновато. Мониторинг важен по одной простой причине: периодически новый автоскейл создается некорректно. Код отрабатывает с ошибками, коннекты по нужным адресам не проходят. В таких ситуациях сразу после обнаружения подобных инстансов необходимо исключить их из Load Balanсer’a для того, чтобы запросы посетителей не отправлялись на них.
Типовая схема применения Auto Scaling

Как выглядит обычный проект, чья инфраструктура полностью состоит из сервисов Amazon? В качестве DNS-серверов для основных доменов используется Amazon Route 53. Это отказоустойчивый DNS-сервер от Amazon, который обладает очень полезными функциями. Все инстансы общаются между собой только по внутренним IP-адресам, чтобы трафик ходил только внутри дата-центров Amazon. Инстансы с MySQL, memcached, Redis, MongoDB и прочими — обычного типа. Инстансы, на которых выполняется код проекта (обрабатываются запросы посетителей), состоят в Auto Scaling группе. При различных изменениях величины входящего трафика от пользователей проекта соответствующим образом меняется и количество www-автоскейлов, что позволяет выдерживать любую нагрузку.
Заключение
Автоматизация работы системного администратора всегда была актуальной задачей. Сначала это были bash-скрипты, потом уровень вырос до применения инструментов, автоматизирующих настройку серверов, таких как Puppet/Chef/CfEngine, сейчас же появляется новый уровень — автоматизация управления железом серверов.
Да, в данном случае железо виртуальное, но сейчас есть возможность создания виртуальных серверов, которые могут быть мощнее, чем многие из существующих физических. Amazon Auto Scaling — яркий пример технологии, которая позволяет в автоматизированном режиме управлять количеством серверов, задействованных в работе вашего проекта, с помощью достаточно удобного и гибкого интерфейса. Также не стоит забывать, что именно с помощью Auto Scaling ваша организация сможет сэкономить тысячи долларов на оплате хостинга проекта — это тоже достаточно немаловажный фактор.
До встречи! Увидимся, когда будем разговаривать еще об одной технологии, помогающей сделать нашу жизнь лучше :).