

Содержание статьи
Известно, что приложения бывают однопоточные и многопоточные. Single thread софт кодить легко и приятно: разработчику не надо задумываться о синхронизации доступа, блокировках, взаимодействии между нитями и так далее. В многопоточной среде все эти проблемы часто становятся кошмаром для программиста, особенно если опыта работы с тредами у него еще не было. Чтобы облегчить себе жизнь в будущем и сделать multi thread приложение надежным и производительным, нужно заранее продумать, как будет устроена работа с потоками. Эта статья поможет твоему мозгу увидеть правильное направление!
Асинхронное программирование набирает обороты. Пользователи любят, когда софт выполняет все действия практически моментально, а UI работает плавно и без лагов. Как бы ни росла производительность железа, но соответствовать таким высоким требованиям можно только с помощью тредов и асинхронности, а это, в свою очередь, создает множество мелких и не очень проблем, которые придется решать обычным программистам.
Для того чтобы понять, что за подводные камни таит в себе работа в многопоточной среде, нужно взглянуть на следующий код:
Singlethread код
int Foo()
{
int res;
// Что-то долго делаем и возвращаем результат
retrun res;
}
// В основном потоке вызываем Foo
auto x = Foo();
// ...
У нас есть функция Foo, которая выполняет некоторые действия и возвращает результат. В главном потоке программы мы запускаем ее, получаем результат работы и идем делать дальше свои дела. Все хорошо, за исключением того, что выполнение Foo занимает довольно длительное время и ее вызов в GUI-потоке приведет к замерзанию всего интерфейса.
Это плохо, очень плохо. Современный юзер такого не переживет. Поэтому мы, немного подумав, решаем вынести действия, выполняемые в нашей функции, в отдельный поток. GUI не залипнет, а Foo спокойно отработает в своем треде.
Асинхронный вызов функции
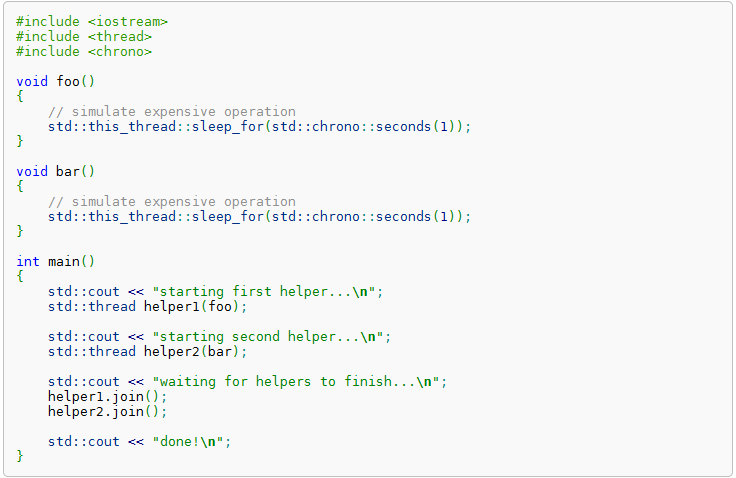
С выходом C++11 жить стало проще. Теперь для создания своего треда не надо использовать сложные API Майкрософт или вызывать устаревшую _beginthread. В новом стандарте появилась нативная поддержка работы с потоками. В частности, сейчас нас интересует класс std::thread, который является не чем иным, как STL представлением потоков. Работать с ним — одно удовольствие, для запуска своего кода достаточно лишь передать его в конструктор std::thread в виде функционального объекта, и можно наслаждаться результатом.
Стоит также отметить, что мы можем дождаться, когда поток закончит свою работу. Для этого нам пригодится метод thread::join, который как раз и служит для этих целей. А можно и вовсе не дожидаться, сделав thread::detach. Наш предыдущий однопоточный пример может быть преобразован в multi thread всего лишь добавлением одной строки кода.
Многопоточность с помощью std::thread
// ...
auto thread = std::thread(Foo);
// Foo выполняется в отдельном потоке
// ...
Казалось бы, все хорошо. Мы запустили Foo в отдельном потоке, и, пока она отрабатывает, мы спокойно занимаемся своими делами, не заставляя основной поток ждать завершения длительной операции. Но есть одно но. Мы забыли, что Foo возвращает некий результат, который, как ни странно, нам нужен. Самые смелые могут попробовать сохранять результат в какую-нибудь глобальную переменную, но это не наш метод — слишком непрофессионально.
Специально для таких случаев в STL есть замечательные std::async и std::future — шаблонная функция и класс, которые позволяют запустить код асинхронно и получить по запросу результат его работы. Если переписать предыдущий пример с использованием новых примитивов, то мы получим приблизительно следующее:
Пробуем std::async и std::future
// ...
std::future<int> f = std::async(std::launch::async, Foo);
// Работаем дальше в основном потоке
// Когда нам нужно, получаем результат работы Foo
auto x = f.get();
В std::async мы передали флаг std::launch::async, который означает, что код надо запустить в отдельном потоке, а также нашу функцию Foo. В результате мы получаем объект std::future. После чего мы опять продолжаем заниматься своими делами и, когда нам это понадобится, обращаемся за результатом выполнения Foo к переменной f, вызывая метод future::get.

Хакер #174. Собираем квадрокоптер
Выглядит все идеально, но опытный программист наверняка задаст вопрос: «А что будет, если на момент вызова future::get функция Foo еще не успеет вернуть результат своих действий?» А будет то, что главный поток остановится на вызове get до тех пор, пока асинхронный код не завершится.
Таким образом, при использовании std::future главный поток может заблокироваться, а может и нет. В итоге мы получим нерегулярные лаги нашего GUI. Наша цель — полностью избежать таких блокировок и добиться того, чтобы главный тред работал быстро и без фризов.
Concurrent Queue
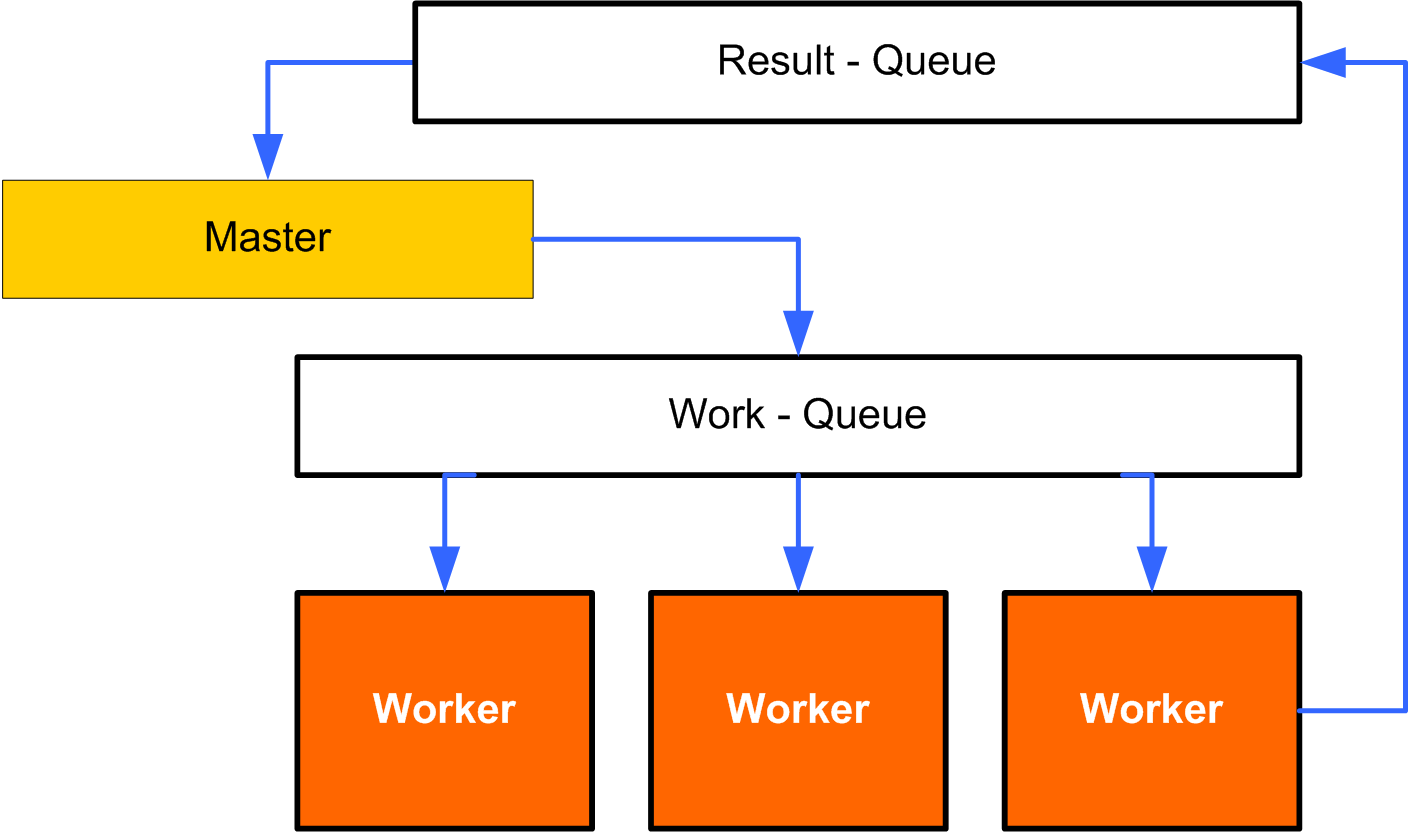
В примере с future::get мы фактически использовали мьютекс. Во время попытки получения значения из std::future код шаблонного класса проверял, закончил ли свою работу поток, запущенный с помощью std::async, и если нет, то ожидал его завершения. Для того чтобы один поток никогда не ждал, пока отработает другой, умные программисты придумали потокобезопасную очередь.
Любой кодер знает такие структуры данных, как вектор, массив, стек и так далее. Очередь — это одна из разновидностей контейнеров, работающая по принципу FIFO (First In First Out). Thread-safe очередь отличается от обычной тем, что добавлять и удалять элементы можно из разных потоков и при этом не бояться, что мы одновременно попробуем записать или удалить что-нибудь из очереди, тем самым с большой долей вероятности получив падение программы или, что еще хуже, неопределенное поведение.
Concurrent queue можно использовать для безопасного выполнения кода в отдельном потоке. Выглядит это примерно так: в потокобезопасную очередь мы кладем функциональный объект, а в это время в рабочем потоке крутится бесконечный цикл, который на каждой итерации обращается к очереди, достает из нее переданный ей код и выполняет его. Чтобы лучше понять, можно взглянуть на код:
Реализация потокобезопасной очереди команд
class WorkQueue
{
public:
typedef std::function<void(void)> CallItem;
WorkQueue() :
done(false),
thread([=]()
{
while (!done)
queue.pop()();
})
{
}
void PushBack(CallItem workItem)
{
queue.push(workItem);
}
// ...
private:
concurrent_queue<CallItem> queue;
bool done;
std::thread thread;
};
Теперь наш код выполняется в очереди, в другом потоке. Более того, мы можем отправить на выполнение не только Foo, но и другие функции, которые выполняются слишком долго. При этом мы не будем каждый раз создавать отдельный thread для каждой функции.
Но мы опять забыли про возвращаемое значение. Одним из способов решения этой проблемы будет обратный вызов. Мы должны передавать в рабочую очередь не только код, требующий выполнения, но и callback-функцию, которая будет вызвана вычисленным значением в качестве параметра.
Callback для возврата значения
class WorkQueue
{
public:
typedef std::function<int(void)> WorkItem;
typedef std::function<void(int)> CallbackItem;
WorkQueue() :
done(false),
thread([=]()
{
while (!done)
queue.pop()();
})
{
}
void PushBack(WorkItem workItem, CallbackItem callback)
{
queue.push([=]()
{
auto res = workItem();
callback(res);
});
}
// ...
private:
typedef std::function<void(void)> CallItem;
concurrent_queue<CallItem> queue;
bool done;
std::thread thread;
};
Но тут следует помнить, что обратный вызов будет сделан в рабочем потоке, а не в клиентском, поэтому заранее следует позаботиться о безопасной передаче значения. Если все приложение построено на основе архитектуры потокобезопасных очередей, то есть у каждого объекта есть своя очередь команд, то решение данной проблемы становится очевидным — мы просто будем поручать выполнение обратного вызова очереди, в которой работает объект, запросивший у нас выполнение Foo.
На словах это звучит довольно просто, но на практике придется решать множество проблем, которые так или иначе связаны с многопоточностью. Так как все происходит асинхронно, то вполне может быть, что по окончании выполнения какого-либо кода объект, запросивший это выполнение, уже не будет существовать и, возвращая ему значение вычислений, мы можем сломать всю программу. Такие нюансы надо учитывать с самого начала, чтобы на этапе проектирования исключить все подобные ситуации.
Заключение
Асинхронное программирование нынче в тренде. Пользовательские интерфейсы iOS и Windows Phone работают плавно и без лагов как раз из-за того, что в их основу заложены принципы, позволяющие избегать блокировок потоков в ожидании результатов работы тех или иных длительных действий. И чем дальше, тем более ярко будет выражено движение в сторону асинхронности работы ПО.








