
Многопроцессорность и многоядерность уже давно стали обыденностью среди пользователей, что не мешает программистам не в полной мере, а то и просто неправильно использовать заложенные в них возможности. Не обещаем, что после прочтения этой статьи ты станешь гуру параллельных вычислений в среде Win, но в некоторых вещах точно разберешься.
Введение
Близился закат эры 32-битных камней, и было очевидно, что надо повышать не только мощность, но и разрядность. Разработчики процессоров столкнулись с рядом проблем в увеличении тактовой частоты: невозможно рассеивать выделяемую кристаллом теплоту, нельзя дальше уменьшать размер транзисторов, однако главной проблемой стало то, что при увеличении тактовой частоты быстродействие программ не повышалось. Причиной этому явилась параллельная работа современных компьютерных систем, а один процессор, каким бы мощным бы он ни был, в каждый момент времени может выполнять только одну задачу. Для примера, у меня в системе Windows 7 в момент написания статьи выполняется 119 процессов. Хотя они далеко не все находятся в бэкграунде, им не всем нужна высокая мощность. На одном камне выполнение нескольких процессов/потоков может быть только конкурентным. То есть их работа чередуется: после того как определенный поток отработает свой квант времени, в течение которого он выполнил полезную нагрузку, его текущее состояние сохранится в памяти, а он будет выгружен из процессора и заменен следующим находящимся в очереди на выполнение потоком — произойдет переключение контекста, на что тратится драгоценное время. А пока идет обмен данными между процессором и оперативной памятью, из-за ограниченной пропускной способности системной шины микропроцессор нервно курит бамбук, в сторонке ожидая данные. На помощь могут прийти аппаратный и программный (например, из операционной системы) планировщики, чтобы подгружать данные в кеш. Однако кеш очень ограничен по объему, поэтому такое решение не может служить панацеей. Выходом стала параллельная обработка, при которой в реальном времени одновременно выполняются несколько процессов. А чтобы ее реализовать, потребовалось фундаментально перепроектировать и перестроить камень — совместить в одном корпусе два исполняющих кристалла и более.
Планирование
При разработке параллельной программы стадия проектирования становится еще более важной, чем при разработке однопоточных приложений. И поскольку на самом деле параллельное программирование в узком кругу задач используется уже десятилетиями, были выявлены некоторые зарекомендовавшие себя концепции. Самое важное — посмотреть на разработку иначе, не последовательно, выделить единицу выполняемой работы, провести декомпозицию задачи. Имеется три способа: декомпозиция по заданиям, декомпозиция по данным, декомпозиция по информационным потокам. Первый способ декомпозиции самый простой: мы просто привязываем отдельную функцию к определенному потоку и запускаем его на выполнение. Параллельная обработка готова. Однако могут быть проблемы — конкуренция, если в исполняемой единице используются общие глобальные данные. Но об этом мы поговорим позже. Второй способ тоже достаточно понятный метод распараллеливания: например, большой массив данных обрабатывается несколькими потоками, каждый из которых работает над частью, ограниченной определенными пределами. Декомпозиция по информационным потокам служит для задач, когда работа одного потока зависит от результата выполнения другого. Например, во время чтения из файла поток — обработчик считанных данных не может начать работу, пока поток-читатель не считает определенный объем данных.


Аппаратные решения

Прежде чем перейти к многоядерности, разработчики процессоров выяснили, что при выполнении одного потока процессорное ядро загружается не полностью (думаю, для этого не надо быть провидцем). И поскольку для выполнения второго программного потока используются не все ресурсы микропроцессора (так как аппаратное состояние — исполнительные устройства, кеш — может храниться в одном экземпляре), то в дублировании нуждается только область состояния программной архитектуры (логика прерываний). Эта технология получила название гиперпоточности (Hyper-Threading). Гиперпоточность — аппаратный механизм, в котором несколько независимых аппаратных потоков выполняются в одном такте на единственном суперскалярном процессорном ядре. С ее помощью один физический процессор представляется как два логических, то есть так его видит операционная система, потому что планирование и выполнение, по сути, осуществляется с расчетом на два ядра. Это происходит благодаря непрерывному потоку команд, выполняющихся на совместном оборудовании. Эта технология была добавлена к архитектуре NetBurst, реализованной в процессорах Pentium 4. Поэтому гиперпоточность была реализована еще в последних версиях Pentium 4, но мне в то время как-то не удалось ее застать. Зато сейчас я могу наблюдать ее в процессоре Atom, установленном в нетбуке. В этом камне, помимо гиперпоточности, реализована многоядерность (в количестве двух штук), поэтому в операционной системе я наблюдаю четыре камня. Но, например, в Core 2 Duo гиперпоточность отсутствует, равно как и в Core i5. С помощью гиперпоточности скорость исполнения оптимизированных для многопоточности программ удалось повысить на 30%. Подчеркну, что прирост производительности будет иметь место только в специально подготовленных приложениях.
Одновременно с гиперпоточностью вдобавок к суперскалярной архитектуре была создана новая архитектура EPIC, реализованная в процессорах Itanium, но эта тема уже не поместится в сегодняшней статье.
Затем были изобретены многоядерные процессоры, которые ныне используются повсеместно. Многоядерные процессоры поддерживают мультипроцессорную обработку на кристалле. В этой архитектуре два ядра или более реализуются в одном процессоре, устанавливаемом в один сокет. В зависимости от конструкции эти ядра могут совместно использовать большой кеш на том же кристалле. Многоядерные процессоры также требуют совместимого чипсета. Так как каждое ядро представляет собой самостоятельный исполняющий модуль, то многоядерные процессоры обеспечивают истинный параллелизм — выполнение каждого потока в обособленной среде. В случае присутствия нескольких исполняющих ядер должен быть способ обмена информацией между ними, без чего попросту невозможно создать параллельную систему, причем нужен специальный ресурс. Для этого был изобретен усовершенствованный программируемый контроллер прерываний (APIC). Он выполняет обмен информации между процессорами/ядрами, используя механизм межпроцессорного прерывания (Interprocessor Interrupt). Последний, в свою очередь, используется операционной системой для планирования/выполнения потоков.
Также на первый план выходит энергопотребление. И это касается не только различных мобильных платформ, питающихся от аккумуляторов, но также и серверных систем и десктопов. Первые x86-процессоры потребляли доли ватт, в то время как современные высокопроизводительные модели могут потреблять 130 и более ватт. Между тем многоядерные процессоры позволяют экономить энергию, так как рост производительности достигается за счет параллелизма, а не за счет увеличения тактовой частоты.
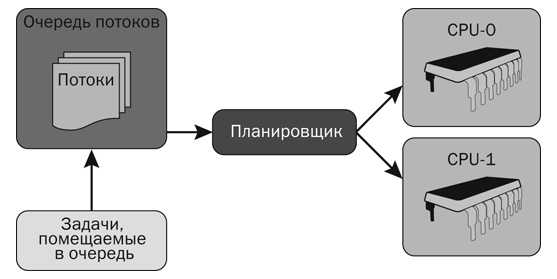
Программные решения
В параллельном выполнении кода огромную роль играют программные решения. На сцену выходят как системные программные продукты (операционные системы, компиляторы), так и приложения пользовательского уровня. С точки зрения прикладного программиста мы можем воспользоваться только вторым подмножеством. На самом деле этого вполне достаточно, если операционная система надежна. Дальнейшее повествование в большинстве своем относится к Windows NT 6.1, если не оговорено иное. Как тебе известно, Windows NT использует модель вытесняющей многопоточности. Когда запускается приложение, стартует процесс, в нем могут выполнять свою работу один или несколько потоков, все они разделяют общую память и общее адресное пространство. Поток же, в свою очередь, — это обособленная последовательность команд, выполняемая независимо. Существует три вида потоков:
- пользовательского уровня — создается в пользовательской программе (на уровне пользователя). Эти потоки в Windows NT проецируются на потоки уровня ядра, так их видит процессор;
- поток ядра — управляется ядром операционной системы;
- аппаратный поток — единица, исполняемая на процессоре.
Создание потока протекает в три этапа. Сначала происходит его описание с помощью поточного API, затем на стадии выполнения этот вызов обрабатывается как вызов ядра, в результате создается поток, потом он выполняется внутри своего процесса. Но в связи с тем, что в программе одновременно выполняется несколько действий, может возникнуть куча проблем. Их удобно классифицировать под четыре типа. Проблема синхронизации возникает, когда один поток ждет выполнения другого, который по каким-то причинам не может завершить выполнение. При проблеме взаимодействия один поток не может вовремя передать информацию другому, например из-за задержек. Когда один поток напрягается, а другой прохлаждается, возникает проблема балансировки. Если в момент переноса программы на более мощный компьютер ее быстродействие не повышается, то говорят о проблеме масштабируемости. Для решения всех этих проблем предназначены примитивы для работы в многопоточной среде. Давай кинем на них поверхностный взгляд.
Примитивы параллельного кодинга
Участки кода, которые могут быть одновременно использованы несколькими потоками и содержат общие переменные, называются критическими секциями. В них чтение-запись значений под действием двух и более потоков могут произойти асинхронно. Это состояние называется состоянием гонок. Поэтому в каждый временной промежуток внутри критической секции должен выполняться только один поток. Для обеспечения этого используются примитивы синхронизации — блокировки. Семафор — исторически самый первый механизм для синхронизации, разработанный Дейкстрой в 1968 году. Позволяет войти в критическую секцию определенному количеству потоков, при входе в нее потока уменьшает свое значение и увеличивает в момент его выхода. Обязательным условием является атомарное выполнение операций проверки значения семафора + увеличения значения, а так же проверки значения + уменьшения значения. Развитием семафора служит мьютекс, который является попросту двоичным семафором и поэтому в критической секции допускает выполнение только одного потока. Блокировки чтения-записи позволяют нескольким потокам читать значение общей переменной, находящейся в критической секции, но записывать только одному. Во время ожидания спин-блокировка не блокируется, а продолжает активный опрос заблокированного ресурса. Спин-блокировка — плохое решение проблемы синхронизации для одноядерного процессора, поскольку занимает все вычислительные ресурсы.
Похож на семафоры механизм условных переменных, тем не менее они, в отличие от семафоров (и мьютексов), не содержат реальных значений. Они следят за выполнением внешних условий.
В современных языках программирования присутствуют высокоуровневые механизмы, позволяющие упростить использование блокировок и условных переменных («мониторы»). Вместо того чтобы явно писать операции блокировки и разблокировки участка кода, разработчику достаточно объявить критическую секцию как синхронизируемую.
Для обмена информацией между процессами/потоками используются сообщения, подразделяемые на три группы: внутрипроцессные (для передачи информации между потоками одного процесса), межпроцессные (для передачи инфы между процессами — с зависимостью от потоков) и процесс — процесс (поточно независимая передача инфы между процессами).
В то же время при использовании блокировок для избегания гонок могут наступить мертвые (dead lock) и живые (live lock) блокировки. Мертвая блокировка имеет место, когда один поток заблокирован на ожидании определенного ресурса от другого потока, но тот не может дать его (например, ожидает результат от первого). Мертвая блокировка может произойти при выполнении четырех хорошо определенных условий (мы не будем разбирать эти условия в данной статье). Поэтому при написании многопоточного кода у программиста есть возможность избежать дидлока, но на практике это выглядит гораздо сложнее. Живая блокировка хуже мертвой тем, что в первом случае потоки заблокированы, а во втором они постоянно конфликтуют.
Существует насколько несовместимых между собой прикладных поточных программных интерфейсов. Все они в основном используют одинаковые примитивы, отличия лишь в зависимости от операционной системы. В следующих разделах мы рассмотрим способы работы в многопоточной среде и решения проблем параллельного кода с использованием этих интерфейсов.
Win32 threads
После появления первой версии Windows NT многопоточное программирование в ней улучшалось от версии к версии, одновременно улучшался связанный с потоками API. Итак, когда стартует процесс посредством функции CreateProcess, он имеет один поток для выполнения команд. Поток состоит из двух объектов: объект ядра (через него система управляет потоком) и стек, в котором хранятся параметры, функции и переменные потока. Чтобы создать дополнительный поток, надо вызвать функцию CreateThread. В результате создается объект ядра — компактная структура данных, используемая системой для управления потоком. Этот объект, по сути, не является потоком. Также из адресного пространства родительского процесса для потока выделяется память. И поскольку все потоки одного процесса будут выполняться в его адресном пространстве, то они будут разделять его глобальные данные. Вернемся к функции CreateThread и рассмотрим ее параметры. Первый параметр — указатель на структуру PSECURITYATTRIBUTES, которая определяет атрибуты защиты и свойства наследования, для установки значений по умолчанию достаточно передать NULL. Второй параметр типа DW0RD определяет, какую часть адресного пространства поток может использовать под свой стек. Третий параметр PTHREADSTART_ROUTIME pfnStartAddr — указатель на функцию, которую необходимо привязать к потоку и которую он будет выполнять. Эта функция должна иметь вид DWORD WINAPI ThreadFunc(PVOID pvParam), она может выполнять любые операции; когда она завершится, то возвратит управление, а счетчик пользователей объекта ядра потока будет уменьшен на 1, в случае, когда этот счетчик будет равен 0, данный объект будет уничтожен. Четвертый параметр функции CreateThread — указатель на структуру PVOID, содержащую параметр для инициализации выполняемой в потоке функции (см. описание третьего параметра). Пятый параметр (DWORD) определяет флаг, указывающий на активность потока после его создания. Последний, шестой параметр (PDWORD) — адрес переменной, куда будет помещен идентификатор потока, если передать NULL, тем самым мы сообщим, что он нам не нужен. В случае успеха функция возвращает дескриптор потока, с его помощью можно манипулировать потоком; при фейле функция возвращает 0.

Существуют четыре пути завершения потока, три из которых нежелательные: это завершение потока через вызов функции ExitThread, через вызов TerminateThread, при завершении родительского процесса без предварительного завершения потока. Лишь 1 путь – самозавершение потока, которое происходит при выполнении назначенных ему действий, является благоприятным. Потому что только в этом случае гарантируется освобождение всех ресурсов операционной системы, уничтожение всех объектов C/C++ с помощью их деструкторов.
Еще пара слов о создании потока. Функция CreateThread находится в Win32 API, при этом в библиотеке Visual C++ имеется ее эквивалент _beginthreadex, у которой почти тот же список параметров. Рекомендуется создавать потоки именно с ее помощью, поскольку она не только использует CreateThread, но и выполняет дополнительные операции. Кроме того, если поток был создан с помощью последней, то при уничтожении вызывается _endthreadex, которая очищает блок данных, занимаемый структурой, описывающей поток.
Потоки планируются на выполнение с учетом приоритета. Если бы все потоки имели равные приоритеты, то для выполнения каждого (в WinNT) выделялось бы по 20 мс. Но это не так. В WinNT имеется 31 (от нуля) поточный приоритет. При этом 31 — самый высокий, на нем могут выполняться только самые критичные приложения — драйверы устройств; 0, самый низкий, зарезервирован для выполнения потока обнуления страниц. Тем не менее разработчик не может явно указать номер приоритета для выполнения своего потока. Зато в Windows есть таблица приоритетов, где указаны символьные обозначения сгруппированных номеров приоритетов. При этом конечный номер формируется не только на основе этой таблицы, но и на значениях приоритета родительского процесса. Значения скрыты за символьными константами по той причине, что Microsoft оставляет за собой право их изменить и пользуется им от версии к версии своей операционки. При создании поток получает обычный (normal) уровень приоритета. Его можно изменить функцией SetThreadPriority, принимающей два параметра: HANDLE hThread — дескриптор изменяемого потока, int nPriority — уровень приоритета (из таблицы). С помощью функции GetThreadPriority можно получить текущий приоритет, передав в нее дескриптор нужного потока. Перед изменением приоритета потока его надо приостановить, это делается функцией SuspendThread. После изменения приоритета поток надо снова отдать планировщику для планирования выполнения функцией ResumeThread. Обе функции получают дескриптор потока, с которым работают. Все описанные операции кроме приостановки и возобновления применимы и к процессам. Они не могут быть приостановлены/возобновлены, поскольку не затрачивают процессорное время, поэтому не планируются.
Избегание гонок в Win32
В многопоточных приложениях надо везде по возможности использовать атомарные — неделимые операции, в выполнение которых не может встрять другой поток. Такие функции в Win32 API имеют префикс Interlocked, например, для инкремента переменной вместо i++ использовать InterlockedExchangeAdd(&i, 1). Помимо операций увеличения/уменьшения, еще есть операции для атомарного сравнения, но мы их оставим в качестве твоего домашнего задания.
Атомарные функции, однако, позволяют решить очень узкий круг задач. На помощь приходят критические секции. В Win32 есть функции для явной отметки такого куска кода, который будет выполняться атомарно. Сначала надо создать экземпляр структуры критической секции, затем в выполняемой в потоке функции написать операторы для входа и выхода в критическую секцию:
CRITICAL_SECTION g_cs;
DWORD WINAPI ThreadRun(PVOID pvParam) {
EnterCriticalSection(&g_cs);
// Что-то вычисляем
LeaveCriticalSection(&g_cs);
return 0;
}
Критические секции в Win32 не просто код, который может выполняться несколькими потоками, это целый механизм синхронизации данных. Критические секции должны быть как можно меньше, то есть включать как можно меньше вычислений.
Чтобы позволить читать значение переменной нескольким потокам, а изменять одному, можно применить структуру «тонкой блокировки» SRWLock. Первым делом надо инициализировать структуру вызовом InitializeSRWLock с передачей указателя на нее. Затем во время записи ограничиваем ресурс эксклюзивным доступом:
AcquireSRWLockExclusive(PSRWLOCK SRWLock);
// Записываем значение
ReleaseSRWLockExclusive(PSRWLOCK SRWLock);
С другой стороны, во время чтения осуществляем расшаренный доступ:
AcquireSRWLockShared(PSRWLOCK SRWLock);
// Читаем значение
ReleaseSRWLockShared(PSRWLOCK SRWLock);
Обрати внимание: все функции принимают проинициализированную структуру SRWLock в качестве параметра.
С помощью условных переменных удобно организовать зависимость «поставщик — потребитель» (см. декомпозицию по информационным потокам), то есть следующее событие должно произойти в зависимости от предыдущего. В этом механизме используются функции SleepConditionVariableCS и SleepConditionVariableSRW, служащие для блокировки критической секции или структуры «тонкой блокировки». Они принимают три и четыре параметра соответственно: указатель на условную переменную, ожидаемую потоком, указатель на критическую секцию либо SRWLock, применимую для синхронизации доступа. Следующий параметр — время (в миллисекундах) для ожидания потоком выполнения условия, если условие не будет выполнено, функция вернет False; последний параметр второй функции — вид блокировки. Чтобы пробудить заблокированные потоки, надо из другого потока вызвать функцию WakeConditionVariable или WakeAllConditionVariable. Если выполненная в результате вызова этих функций проверка подтвердит выполнение условия, передаваемого в качестве параметра данным функциям, поток будет пробужден.
В приведенном описании мы познакомились с общими определениями механизмов семафор и мьютекс. Сейчас посмотрим, как они реализованы в Win32. Создать семафор можно с помощью функции CreateSemaphore. Ей передаются такие параметры: указатель на структуру PSECURITY_ATTRIBUTES, содержащую параметры безопасности; максимальное число ресурсов, обрабатываемых приложением; количество этих ресурсов, доступных изначально; указатель на строку, определяющую имя семафора. Когда ожидающий семафора поток хочет получить доступ к ресурсу, охраняемому семафором, то wait-функция потока опрашивает состояние семафора. Если его значение больше 0, значит, семафор свободен и его значение уменьшается на 1, а поток планируется на выполнение. Если же при опросе семафор занят, его значение равно 0, тогда вызывающий поток переходит в состояние ожидания. В момент, когда поток покидает семафор, вызывается функция ReleaseSemaphore, в которой значение семафора увеличивается на 1. Мьютексы, как и семафоры, — объекты ядра. Функционирование мьютексов похоже на критические секции Win32, с разницей в том, что последние выполняются в пользовательском режиме. В каждый момент времени мьютекс разрешает выполняться только одному потоку и предоставляет доступ только к одному ресурсу. При этом он позволяет синхронизировать несколько потоков, храня идентификатор потока, который захватил ресурс и счетчик количества захватов. Чтобы создать мьютекс, можно воспользоваться функцией CreateMutex, ее параметры аналогичны рассмотренным выше. Когда ожидание мьютекса потоком успешно завершается, последний получает монопольный доступ к защищенному ресурсу. Все остальные потоки, пытающиеся обратиться к этому ресурсу, переходят в состояние ожидания. Когда поток, занимающий ресурс, заканчивает с ним работать, он должен освободить мьютекс вызовом функции ReleaseMutex. Эта функция уменьшает счетчик рекурсии в мьютексе на 1. Выбор используемого механизма синхронизации во многом зависит от времени его исполнения и кода, в котором он используется.
Кроме всего прочего, в Windows NT, начиная с четвертой версии, имеется еще один поточный уровень детализации — волокна (или нити). На уровне пользователя объект ядра поток может быть разделен на несколько нитей. И в таком случае операционная система ничего о них не знает, вся работа по планированию и управлению нитями ложится на плечи разработчика прикладного приложения.
Заключение
Создание современного ПО требует использования параллелизма, а в будущем производители процессоров грозятся только увеличивать количество ядер на одном процессоре. Однако у многопоточного программирования есть ряд сложных моментов: организовать синхронное выполнение команд, избежать гонок и при этом оптимально нагрузить железо, чтобы добиться повышения производительности за счет параллелизма.
В этой статье сначала мы разобрались с примитивами параллельного кодинга — общими понятиями, затем разобрались, как они исполнены в конкретном API — Win 32 threads. Рамки статьи не позволили нам рассмотреть другие API для многопоточного кодинга. Будем надеяться, что у нас еще будет возможность когда-нибудь продолжить обсуждение этой нужной темы.
Желаю удачи, до встречи!











