Содержание статьи
Часто ли ты делаешь бэкапы? Между тем, в *nix-системах существует множество самых разнообразных средств для их создания, начиная от самых маленьких и заканчивая огромными пакетами для энтерпрайз-сектора. Каждое из этих средств имеет свои особенности, у каждого свои преимущества и недостатки... Какое из них будешь использовать ты?
Введение
Аспект сохранения резервных копий (и их хранения), безусловно, один из важнейших в информационном мире: кому хочется, чтобы его данные в результате ошибки (программной ли или аппаратной) пропали? Соответственно, средств для создания бэкапов существует великое множество. Перечислю самые, на мой взгляд, необходимые требования к данным средствам:
- Удобство автоматизации и сам факт наличия таковой. Это требование, впрочем, практически полностью нивелируется наличием Cron’а во всех *nix-дистрибутивах общего назначения. Однако резервное копирование как раз тот самый случай, когда не стоит складывать все яйца в одну корзину.
- Поддерживаемые носители и сетевые резервные копии. Средство резервного копирования может быть сколь угодно замечательно, но если оно поддерживает только ограниченный набор носителей, на которые позволяется сохранять бэкапы, то оно не стоит и ломаного гроша. Особняком стоит создание бэкапов с помощью сетевых (в том числе и облачных) хранилищ. Здесь появляется такой аспект, как шифрование и передачи данных, и самих бэкапов.
- Удобство восстановления. Полагаю, здесь комментарии излишни, ибо если произошла потеря данных, их восстановление должно быть как можно более быстрым и безболезненным.
- Удобство начального конфигурирования. Это требование, конечно, дискуссионно, поскольку настраивается создание бэкапов единожды. Тем не менее люди зачастую производят выбор в пользу куда менее функциональных средств только из-за их простоты.
Я не ставил цели описать подробно то или иное средство — практически по каждому из них можно написать отдельную книгу или как минимум статью. Здесь же будет именно краткий их обзор.
rsync и rsnapshot
Несмотря на то что rsync изначально не был предназначен для резервного копирования (это всего лишь удобное средство для синхронизации файлов/каталогов по сети), его чаще всего используют именно с целью создания бэкапа на удаленном компьютере. Перечислю его возможности:
- Работа по протоколу SSH (по желанию).
- Передача только дельт файлов, то есть при внесении изменений передаются не файлы целиком, а лишь их изменившиеся части.
- Сжатие данных при передаче.
- Продолжение передачи файла после обрыва связи с того места, на котором произошел обрыв.
Приведу для начала самый простой пример его использования:
$ rsync --progress -e ssh -avz /home/adminuser/Docs root@leopard:/home/adminuser/backup/
Ключи:
- -r — рекурсия;
- -l — сохранять симлинки;
- -p — сохранять права (стандартные, UGO, — для сохранения же ACL и расширенных атрибутов нужно использовать опции -A и -X соответственно);
- -t — сохранение mtime;
- -o — сохранение владельца файла (на удаленной машине, как и две последующие опции, доступно только root);
- -g — сохранение группы;
- -D — сохранение специальных файлов;
- -a — делает то же самое, что и комбинация перечисленных выше ключей (без сохранения ACL и расширенных атрибутов);
- -v — вывод имен файлов;
- -z — сжатие;
- -e ssh — команда, вызываемая для доступа к удаленной оболочке. То есть, если SSH находится на нестандартном порту, нужно использовать -e 'ssh -p3222';
- --progress — вывод индикатора прогресса.
Кроме того, следует обращать внимание на каталоги — если в конце имени передаваемого каталога стоит слеш, в каталог назначения будет передано только его содержимое, но не он сам.
Но эта команда имеет один недостаток. Если пользователь на стороне пункта назначения непривилегированный, скопировать некоторые системные атрибуты (такие как владелец файла/каталога) не получится. Для обхода этой проблемы есть опция --fake-super, которая сохраняет подобные вещи в расширенных атрибутах и которая должна указываться на принимающей стороне (и на ней же должна быть включена поддержка расширенных атрибутов). Кроме того, по умолчанию rsync копирует только имена пользователей, но не их числовые идентификаторы. Для синхронизации и числовых ID стоит использовать опцию --numeric-ids. С учетом всего этого для непривилегированного пользователя команда будет выглядеть так:
$ rsync --progress -e ssh -avz --rsync-path="rsync --fake-super" --numeric-ids /home/adminuser/Docs adminuser@leopard:/home/adminuser/backup/
Rsnapshot, в свою очередь, представляет собой обертку вокруг rsync, написанную на Perl. Удобен тем, что есть конфигурационный файл и не нужно мучиться с параметрами. Также можно задавать preexec- и postexec-скрипты, что полезно, например, для предварительного архивирования. Сам rsnapshot использует по возможности жесткие ссылки, что значительно уменьшает размер копий на удаленном сервере — новые файлы передаются только в случае их изменения.

Хакер #191. Анализ безопасности паркоматов
Rsync/rsnapshot сложно рассматривать в качестве средств именно резервного копирования — они не поддерживают практически ничего, что должны поддерживать нормальные средства подобного рода. Однако если у тебя есть два сервера и тебе нужно время от времени делать бэкапы конфигов — его для этого будет вполне достаточно.
Duplicity и Deja-Dup
Как и практически все средства подобного рода, Duplicity реализует стандартную схему полного/инкрементного резервного копирования. Однако есть у него и свои особенности, одна из которых — шифрование бэкапов, а вторая — поддержка множества протоколов (SCP/SSH, FTP, WebDAV, rsync, HSI...).
Приведу пример использования данной утилиты:
$ duplicity full --encrypt-key 75E1A006 /home/adminuser sftp://adminuser@leopard//home/adminuser/backup
Откомментировать тут надо разве что опцию --encrypt-key, которая указывает, какой ключ из связки ключей GPG будет использован (естественно, сама связка должна существовать). Кроме того, для SSH также используется аутентификация с помощью ключей, так что ключ должен быть импортирован на принимающей стороне.
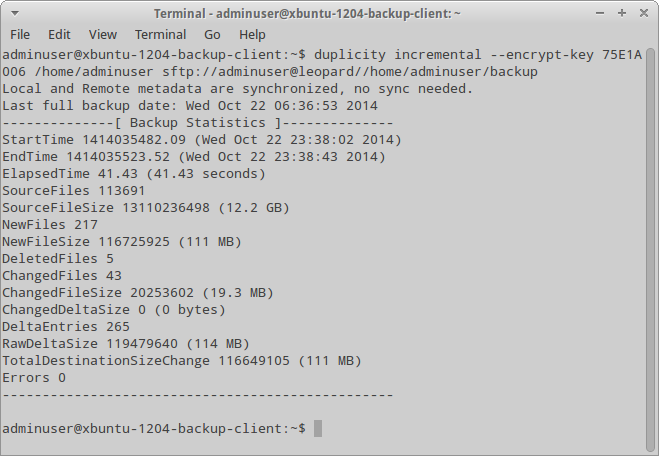
Для создания инкрементной резервной копии можно либо указать аргумент incremental, либо вовсе ничего не указывать — в последнем случае Duplicity определит тип резервной копии автоматически. Можно также указывать список файлов/каталогов, включаемых / не включаемых в бэкап, — опции --include и --exclude. Помимо этих опций, есть еще аналогичные опции для (не)включения файлов по маске, но их лучше смотреть в man-странице.
Для полного восстановления нужно использовать аргумент restore. Например, так:
$ duplicity restore --encrypt-key 75E1A006 sftp://adminuser@leopard//home/adminuser/backup /home/adminuser/restore
Однако иногда требуется восстановить только конкретный каталог/файл. Для этого нужно, во-первых, просмотреть список файлов в текущей резервной копии (аргумент list-current-files), во-вторых же, указать сами восстанавливаемые файлы вместе с аргументом restore — параметр --file-to-restore. Пример:
$ duplicity restore --encrypt-key 75E1A006 --file-to-restore 'Downloads' sftp://adminuser@leopard//home/adminuser/backup /home/adminuser/restore
Кроме всего прочего, у Duplicity существует еще и графический фронтенд под названием Deja-Dup. Он действительно облегчает работу, однако не позволяет использовать асимметричное шифрование, что, впрочем, для домашних пользователей не столь критично.
В целом Duplicity уже более похож на средство резервного копирования, нежели rsync/rsnapshot. Здесь уже есть и шифрование, и поддержка облачных хранилищ, и разбивка получившегося архива на части (к слову, формат архива — старый добрый tar)... Однако есть у Duplicity и некоторые недостатки. К таковым можно отнести невозможность сохранения ACL и расширенных атрибутов.
Cedar Backup
А это средство изначально было предназначено для резервного копирования на CD/DVD-носители, однако сейчас поддерживается и сохранение в облако Amazon S3. Cedar Backup может сохранять не только файлы из файловой системы, но и репозитории Subversion, БД PostgreSQL/MySQL, информацию о системе... Более того, он, в связи с текущими размерами ФС и файлов, попросту не очень рассчитан на сохранение всего подряд — CD/DVD-болванки, увы, не резиновые. Также Cedar Backup поддерживает и шифрование с использованием все того же GPG, так что, если даже бэкапы будут почему-либо скомпрометированы, их не так просто будет достать.
Он также поддерживает пулы, то есть способен бэкапить с нескольких машин. Машины, с которых он собирает информацию, называются клиентами, а собственно машина, на которой происходит запись на болванку / в облако, — Master (в дальнейшем будет именоваться сервером). Однако ничто не мешает производить как сбор, так и запись на одной машине. Обычно часть действий на клиентах должна выполняться автоматически с помощью клиентского Cron’а, но можно настроить сервер так, чтобы эти действия выполнял по расписанию именно он, заходя на клиентские машины через SSH.
Процесс бэкапа условно делится на четыре стадии, наличие/отсутствие которых может различаться в зависимости от настроек:
- Сбор (Collect) — первая стадия, исполняется как на стороне клиентов, так и на стороне сервера (последнее, впрочем, необязательно). Cedar Backup обходит каталоги и в зависимости от режима выбирает файлы для сохранения. Затем он их архивирует и сжимает.
- Получение (Stage) — процесс копирования бэкапов с клиентских узлов на сервер. Если эта стадия почему-либо не произошла на каком-то из узлов, Cedar Backup по умолчанию переходит к следующему узлу. Но это поведение настраиваемое. Кроме того, возможно также получать данные, которые собраны другим процессом: для этого в каталоге должен быть файл cback.collect.
- Сохранение (Store) — собственно запись бэкапа на носитель. В зависимости от опций и/или поддержки записывающего устройства (если мы пишем на оптический диск) либо создается новая сессия, либо диск пишется «с нуля».
- Очистка (Purge) — удаление временных файлов, которые были собраны и получены на предыдущих этапах.
Конфиг в XML-формате содержит восемь секций, большинство из которых относятся к стадиям и могут вследствие этого различаться:
- — исключительно для удобства пользователя, все поля здесь могут оставаться пустыми.
- — здесь задаются основные опции конфигурации, такие, например, как день начала недели, временный каталог, пользователь и группа, от имени которого происходит бэкап, команды, которые выполняются до и после бэкапа, используемые стадии.
- — настройка узлов. Для каждого узла есть секция , в которой задается имя узла, его тип (local, который, понятно, может быть только один, и remote), каталог, где находятся собранные данные.
- — конфигурация стадии Collect. Здесь указывается в том числе режим сбора (ежедневный, еженедельный или инкрементный), тип архива, который получится на выходе (tar, tar.gz или tar.bz2), и сам список собираемых файлов/каталогов и исключения из него.
- — настройка стадии получения. В простейшем случае здесь указывается только опция , определяющая каталог, куда происходит получение.
- — настройка сохранения. Настраивается в том числе извлечение накопителя, его проверка и объем.
- — настройка очистки. Единственный стоящий внимания параметр — , задающий количество дней, по истечении которого содержимое соответствующих каталогов может быть удалено.
- — настройка расширений. Здесь указываются подсекции действий, в которых задается, например, имя питоновского модуля, имя вызываемой функции из него и, наконец, индекс, определяющий порядок выполнения данного действия. Стадии тоже рассматриваются как действия с заранее заданным индексом, что позволяет определить действия, которые будут совершаться до или после какой-либо стадии.
Рассмотрю урезанный пример конфигурационного файла для одного узла:
<cb_config>
<reference>
<...>
</reference>
<options>
<starting_day>tuesday</starting_day>
<working_dir>/home/adminuser/tmp</working_dir>
<backup_user>adminuser</backup_user>
<backup_group>adminuser</backup_group>
<rcp_command>/usr/bin/scp -B</rcp_command>
</options>
<peers>
<peer>
<name>debian</name>
<type>local</type>
<collect_dir>/home/adminuser/cback/collect</collect_dir>
</peer>
</peers>
<collect>
<...>
<collect_mode>daily</collect_mode>
<archive_mode>targz</archive_mode>
<ignore_file>.cbignore</ignore_file>
<dir>
<abs_path>/home/adminuser/Docs</abs_path>
<collect_mode>incr</collect_mode>
</dir>
<file>
<abs_path>/home/adminuser/.profile</abs_path>
<collect_mode>weekly</collect_mode>
</file>
</collect>
<stage>
<staging_dir>/home/adminuser/backup/stage</staging_dir>
</stage>
<store>
<...>
</store>
<purge>
<dir>
<abs_path>/home/adminuser/backup/stage</abs_path>
<retain_days>7</retain_days>
</dir>
<dir>
<...>
</dir>
</purge>
<extensions>
<action>
<name>encrypt</name>
<module>CedarBackup2.extend.encrypt</module>
<function>executeAction</function>
<index>301</index>
</action>
</extensions>
<encrypt>
<encrypt_mode>gpg</encrypt_mode>
<encrypt_target>Backup User</encrypt_target>
</encrypt>
</cb_config>
Отмечу, что здесь, в связи с использованием расширения для шифрования (которое срабатывает сразу после стадии получения), появляется секция . В данной секции заслуживает внимания только . В нем указывается псевдоним владельца ключа.
Для выполнения бэкапа достаточно набрать команду cback, в случае необходимости указав опцию --full. Также имеет смысл занести ее в Cron — на сей раз безо всяких опций.
В целом Cedar Backup для декларируемых целей выглядит достаточно неплохо, хотя и непонятно, что сейчас может влезть на одну CD- (да пусть даже и DVD-) болванку: для крупных бэкапов ее емкость нынче слишком мала, а для хранения только бэкапов конфигов использование болванок стандартного объема выглядит крайне расточительно. Кроме того, поддержка расширений дает возможность добавлять функциональность — в целом прикрутить сохранение в облачных хранилищах должно быть достаточно легко. Однако есть у Cedar Backup и жирный минус: в нем нет средства восстановления из бэкапов. То есть в случае указанного выше конфига для восстановления файла нужно будет вспомнить дату его изменения, расшифровать соответствующий архив, распаковать его и только потом вытащить этот самый файл.
Облачные хранилища
В связи с повальным распространением быстрого интернета некоторые хранят резервные копии в облачных хранилищах. Не буду рассуждать о преимуществах и недостатках данного способа, вместо этого приведу несколько сервисов подобного рода:
* CloudMe.com — шведский сервис для облачного хранения данных, предоставляет бесплатно от 3 до 19 ГБ места, также есть WebDAV. К сожалению, объем одного файла на бесплатном аккаунте ограничен 150 МБ.
* DriveHQ.com — бесплатно выдается 1 ГБ, поддерживается WebDAV и FTP. Но ограничение выгрузки на WebDAV — где-то 50 МБ за раз, а загрузка на бесплатном тарифе — 200 МБ в месяц.
* Yadi.sk — Яндекс.Диск. Бесплатно предоставляется 10 ГБ места, WebDAV также поддерживается. Ограничений на размер файла и полосу пропускания нет.
Отмечу, что если планируется хранить бэкапы в облачных хранилищах, то лучше держать их сразу в нескольких — известен как минимум один случай, когда после покупки облачного сервиса доступ к нему предоставлять переставали.
Bacula
Bacula, пожалуй, одно из самых мощных средств резервного копирования. Предназначенное для использования в средних и крупных сетях, оно имеет гибкую архитектуру, состоящую из пяти частей:
- Bacula Director — самый главный сервер, который и управляет всеми процедурами.
- Bacula Console — управляющая консоль. Есть как текстовый, так и графические (в том числе и Web) варианты.
- СУБД (MySQL, PostgreSQL или SQLite), необходимая для хранения метаданных.
- Storage Director — тот сервер, на котором бэкапы и хранятся / сохраняются на физические носители.
- File Daemon — сам клиент резервного копирования, который по командам Bacula Director передает данные в Storage Director.
В принципе, все это может быть установлено и на одной машине, однако применять Bacula в подобной ситуации смысла не имеет. Оптимальная же конфигурация такая — Bacula Director и Storage Director (вместе с СУБД и консолью) находятся на одной машине и бэкапят данные с клиентов.
Центральная часть конфигурации Bacula Director — задание (job), в котором и указываются нужные ссылки (расписание, набор файлов, хранилище...). Приведу пример одного из заданий:
Job {
Name = "home_backup" # Имя задания
Type = Backup # Тип задания (backup, restore, verify...)
Level = Full # Тип бэкапа (как правило, переопределяется аналогичной опцией в соответствующем расписании)
Client = backup-client # Имя клиента
FileSet = "bc-home-set" # Имя набора файлов для сохранения
Schedule = "Weekly-schedule" # Имя расписания
Storage = backup-storage # Имя секции, где описана конфигурация файлового хранилища
Messages = Daemon # Поведение уведомлений
Pool = backup-client-pool # Пул бэкапов
Priority = 10 # Приоритет. Указывая приоритеты от 1 до 10, можно контролировать порядок выполнения заданий
Write Bootstrap = "/var/db/bacula/home-backup.bsr" # Файл, предназначенный для восстановления в том случае, если полетит СУБД
}
Теперь посмотрим на расписание:
Schedule {
Name = "Weekly-schedule"
Run = Level=Full mon at 18:00
Run = Level=Incremental tue-fri at 17:00
}
Это расписание описывает, что полный бэкап будет производиться каждую неделю в понедельник в шесть вечера, а инкрементные — со вторника по пятницу, в пять вечера. Помимо полных и инкрементных бэкапов, Bacula поддерживает и дифференциальные.
Стоит отметить, что Bacula работает независимо от демона Cron, что выгодно отличает его от большинства доморощенных средств резервного копирования. Также Bacula поддерживает шифрование бэкапов на основе PKI. Кроме того, восстановление бэкапов происходит достаточно легко, не нужно расшифровывать бэкапы вручную.
Но есть у Bacula и недостатки. Если мы говорим об энтерпрайз-секторе, нужно учитывать также наличие единой точки отказа. В Bacula таковая имеет место: при отказе Bacula Director вся инфраструктура рушится. Кроме того, развертывание оной занимает ненулевое время, впрочем, как и в случае с другими подобными решениями. Облачное резервное копирование в свободной версии Bacula отсутствует, но так ли оно нужно в решениях подобного класса? А в условиях SOHO-сетей применять данное решение попросту нерационально.
Заключение
В статье были рассмотрены пять различных средств резервного копирования, подходящих как для дома и небольших сетей, так и для корпоративного сектора. Выбор средства остается за тобой, можно лишь дать несколько советов.
Так, rsync/rsnapshot имеет смысл применять, если у тебя всего пара-тройка серверов и ты хочешь всего лишь время от времени сохранять каталог /etc и прочие текстовые конфиги. Примерно для этих же целей предназначен и Cedar Backup — отличие разве что в том, что последний не синхронизирует по сети, а записывает на болванку и позволяет шифровать бэкапы, для восстановления которых потребуется приложить некоторые усилия.
Любителям облачных решений, несомненно, придется по вкусу Duplicity и его графический фронтенд Deja-Dup. Для домашних пользователей это действительно простое и удобное решение, позволяющее не только бэкапить (и шифровать по желанию), но и в случае чего достаточно быстро восстанавливать как бэкапы целиком, так и отдельные файлы.
В том же случае, когда ты будешь обслуживать сеть среднего или тем паче крупного масштаба, имеет смысл обратить внимание на Bacula, который и предназначен для подобных целей и в котором есть в том числе независимость от стандартного *nix-планировщика и шифрование резервных копий, то есть два из трех пунктов, о которых говорилось во введении.
Какое бы средство ты ни выбрал, помни — лучше сохранять данные хоть как-то, чем вообще их не сохранять.