

Содержание статьи
О, это ты. Проходи, садись поближе к системному блоку, тут тепло. Настало время приступить ко второй части (не пропусти и первую часть тоже) наших исследований и понабирать еще зеленоватых буковок на черном экране. Сегодня будет настоящий хардкор, мы привлечем все наши знания, чтобы составить действительно сложные и почти нечитаемые команды, с помощью которых перепашем кучу данных в параллельном режиме.
Нужно больше крестьян
Мы запомнили множество команд, освоили grep и awk и разобрались, как обходить подводные камни, но еще не можем сказать, что заставляем комп работать на все сто процентов. Однако это легко исправить, если всего лишь научиться использовать несколько ядер процессора и, например (один из стандартных подходов), создать очередь для параллельной обработки данных воркерами.
Не надо напрягаться, я не буду сейчас рассказывать про тонкости многопоточного программирования и примитивы синхронизации. Мы же договорились, что все будет в консоли, — так и поступим. А поможет в этом квесте, как ни странно, еще одна стандартная утилита командной строки, про которую ты наверняка слышал, — xargs. Да, ее основная задача — это подставлять результат выполнения одной команды в качестве аргумента другой, но этим ее возможности не исчерпываются. Освежим память:
$ find . -name "*.sh" -print0 | xargs -0 -I'{}' mv '{}' ~/backup_scriptsЗдесь все просто: находим в текущем каталоге все файлы с расширением .sh и скармливаем их поочередно команде mv, которая швыряет их в бэкап. Ключи -print0 и -0 здесь указывают на то, что данные, поступающие из выхода find на вход в xargs, будут по-сишному разделены null-байтом. Параметр -I, в свою очередь, задает шаблон, который будет использоваться при подстановке значений в управляемую команду.
Казалось бы, при чем здесь очередь сообщений и воркеры? Сейчас это просто обычный цикл, в котором на каждой итерации команда mv что-то куда-то копирует. А хитрость вот в чем: никто не говорил, что xargs умеет и обязан запускать ровно один экземпляр команды. Представим, например, такую структуру каталогов (да, это вывод еще одной полезной консольной команды):
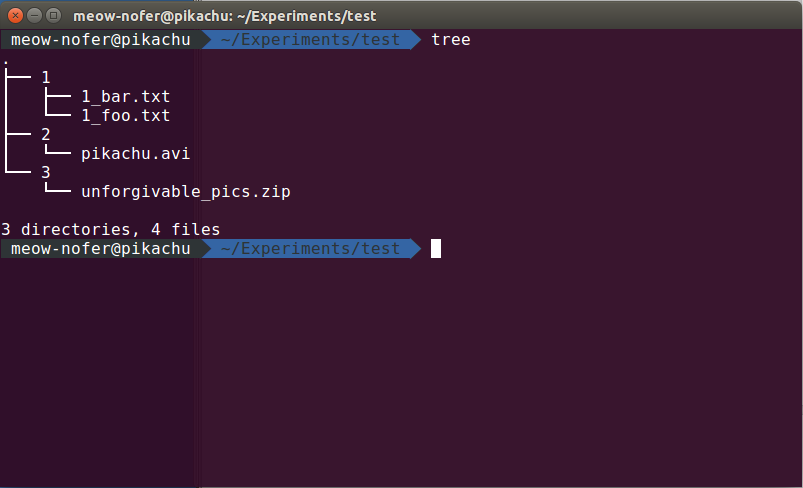
Что получится, если мы запустим такую (абсолютно бесполезную, но все же) команду?
$ ls | xargs -P3 -n1 lsИли (а это даже интереснее) что будет, если мы запустим ее несколько раз?
$ ls | xargs -P3 -n1 ls
pikachu.avi
1_bar.txt 1_foo.txt
unforgivable_pics.zip
$ ls | xargs -P3 -n1 ls
1_bar.txt 1_foo.txt
pikachu.avi
unforgivable_pics.zipЧто-то эта ситуация напоминает, не правда ли? Несколько независимых процессов, пишущих в одну консоль, например? Да-да, параметр -P здесь задает количество процессов для запуска (можно поставить число ядер процессора, например ;)), а -n указывает, сколько строк из входа одновременно передавать каждому процессу. В результате запускается не один, а сразу три экземпляра команды ls, каждый из которых начинает разбирать строчки из очереди, организованной xargs. Кто первый встал — того и тапки, причем команда не завершается, пока не отработает последний воркер, то есть барьер здесь тоже есть.
Дальше — больше. Понадобилось мне как-то скопировать приличное количество файлов с HDFS. Делать это в большом цикле — очень долго, писать навороченные скрипты специально для этой задачи — как-то уныло. В итоге через несколько минут появилось вот такое детище Франкенштейна:
$ cat file.txt | xargs -l bash -c 'echo hdfs dfs -get $0 $1' | xargs -I {} -d '\n' -n1 -P8 -t bash -c "eval {}"Сейчас объясню. На входе был файл, в котором на каждой строчке два пути — адрес файла внутри HDFS и место, куда его надо скопировать локально. Чтобы скопировать данные быстро, необходимо было запустить операции копирования в несколько потоков. Первый вызов xargs превращает поток из пар адресов в поток команд по копированию данных (file1 file2 становится echo hdfs dfs -get file1 file2), также разделенных переносом строки (-d во втором xargs как раз для обработки такого случая). После этого поток передается второму xargs, который выполняет сформированные на предыдущем шаге команды в восемь потоков. Громоздко? Да, можно так сказать. Но на отлично решает задачу и сильно экономит время.
Есть еще одна команда, специально для параллелизации, с довольно неожиданным названием parallel. Она сама определяет, сколько процессов запустить (хоть это можно и задавать явно, как в примере ниже), а кроме того, позволяет буквально «разветвить трубопровод» и разбрасывать данные, поступающие с одного pipe’а по нескольким другим pipe’ам. Так, с ее помощью можно организовать параллельное конвертирование WAV-файлов в MP3:
$ ls *.wav | parallel lame {} -o {}.mp3Если ты злишься на меня за cURL из предыдущей части статьи, то вот пример с Wget:
$ cat urls.txt | parallel -j+2 'wget "{}" -O - | python parse.py'Здесь у нас на входе файл с большим числом урлов, а parallel запускает количество воркеров, равное числу ядер CPU плюс 2. Каждый воркер скачивает страничку и передает ее на стандартный вход скрипту на Python, который, возможно, ее парсит и делает еще какую-нибудь хакерскую магию.
Форматы вокруг нас
Думаю, не погрешу против истины, если скажу, что два самых популярных формата данных, с которыми приходится сталкиваться при анализе (да и при программировании вообще), — это CSV (включая подвиды с другими разделителями) и JSON. В последнее время также становится популярен YAML, но аналитические данные в нем обычно не хранят, это скорее из стана конфигурационных файлов и прочих декларативных описаний.
Если ты думаешь, что с CSV в общем случае работать легко и просто, то это только потому, что тебе не попадались такие строки:
1,2, "vova,dima",7
3,, "lenin",0Это абсолютно корректный CSV, однако что получится, если мы попробуем разбить верхнюю строчку по запятой? Или какое значение у нас окажется во втором поле нижней строки? Погоди рвать волосы, решение есть. И оно, как ни странно, реализовано в виде модуля для Python, который, в свою очередь, предоставляет набор консольных команд для разных задач. Модуль называется csvkit и включает в себя несколько интересных утилит:
- in2csv — «не знаю, что это, но я хочу преобразовать это в CSV», работает, например, с файлами Excel;
- csvcut — позволяет корректно манипулировать колонками, в том числе используя их имена;
- csvlook— выводит CSV как красивую табличку в терминале, по аналогии с консольными клиентами к БД;
- csvjson — конвертирует CSV в JSON в виде списка объектов с полями и значениями;
- csvsql — всего-навсего позволяет делать SQL-запросы к CSV-документам. Not a big deal;
- csvsort — позволяет сортировать по колонкам, в том числе используя их имена.
Неплохо, да? Целая инфраструктура. Если хочется осознать всю прелесть — можно, например, взять файл imdb-250-1996-2011-lists-only.xlsx, а потом сделать так:
$ in2csv imdb-250-1996-2011-lists-only.xlsx | csvsql --query "select Title,Year from stdin where Year<2009" | csvsort -r -c Year | head -n 10 | csvlookМне кажется, даже объяснять, что конкретно здесь происходит, не требуется — после прочтения текста выше это должно быть довольно очевидно. Попробуй понять и прочувствовать сам.
«Ну да, с CSV-то и простыми текстовыми форматами это все работает, но в случае JSON мне ничто такое не поможет», — подумал ты. И напрасно. Утилита jq позволяет делать с JSON-файлами чуть менее, чем все. Если учесть, что парой абзацев выше упоминалась команда csvjson, то простор для действия практически неограничен.
Самый простой способ начать работу с ней — это подать на вход какой-нибудь JSON-файл и получить выдачу в консоли с красивыми отступами и подсветкой синтаксиса (!). Поскольку в JSON все — либо объект, либо список объектов, то мы обращаемся ко всему, используя либо точку, либо квадратные скобки:
$ echo '{"first_name": "Paul", "last_name": "McCartney"}' | jq "."
{
"first_name": "Paul",
"last_name": "McCartney"
}$ echo '{"first_name": "Paul", "last_name": "McCartney"}' | jq ".first_name"
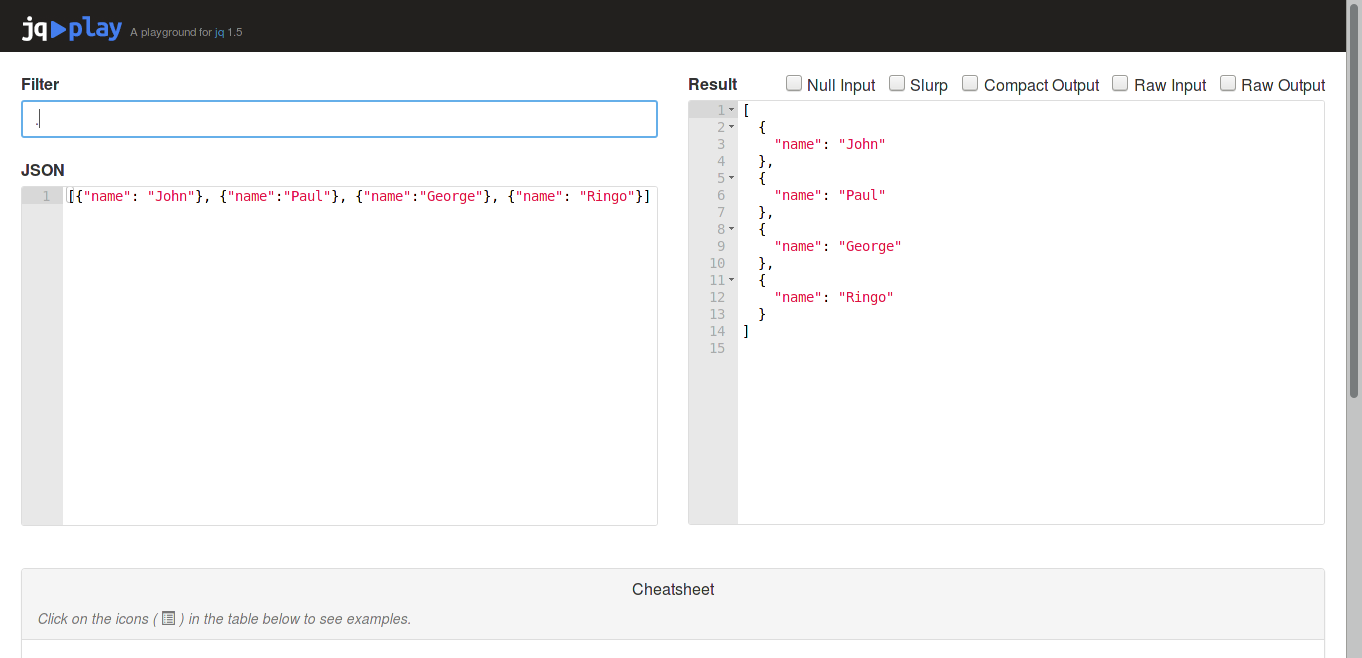
"Paul"$ echo '[{"name": "John"}, {"name":"Paul"}, {"name":"George"}, {"name": "Ringo"}]' | jq '.[] | select(.name | contains("o"))'
{
"name": "John"
}
{
"name": "George"
}
{
"name": "Ringo"
}

Чтобы полнее описать потенциал этой утилиты, приведу один совсем суровый пример, который реально использовался в продакшене:
$ cat file.csv | csvjson —stream | jq -c 'if .createdDate != "" then .createdDate = (.standardRegCreatedDate | split(" ") | .[0:2] | join("T") + "Z" ) else .createdDate = "9999-01-01T00:00:00Z" | to_entries | map(select(.key | contains("rawText") | not ) ) | from_entries' | ...Предыстория здесь такова. У меня была прорва CSV-файлов, в которых в колонке createdDate было полно всякой дряни, не имеющей отношения к датам. Но в поле standardRegCreatedDate даты стояли обычно верные, хотя в не совсем корректном формате. Да еще попадались поля с нечищеными данными — в их названии значились слова rawText, и их можно было вообще выкинуть. Для того чтобы все это разрулить, пришлось написать вот такую довольно громоздкую конструкцию с манипуляцией строками, преобразованием в пары ключ — значение и обратно.
Но и это еще не все. Приведенный мегаконвейер не полный, ведь данные надо было не только обработать, но и залить в Elasticsearch, и не просто залить, а в виде HTTP bulk-запросов в определенном формате (если очень интересно — об этом можно почитать здесь). И вот здесь я как раз и задействовал описанную выше технику распараллеливания:
$ ... | awk '{ print "{\"index\": {} }","\n" $0 }' | parallel --pipe -N500 curl -s -XPOST localhost:9200/items/entry/_bulk --data-binary @- > /dev/nullС awk все просто: формируем запросы определенной структуры. А вот что происходит дальше. Parallel запускает одновременно столько процессов curl, сколько у нас есть ядер CPU, открывает с каждым из них pipe и отдает каждому на stdin по 500 строк из ввода. Каждый curl принимает все данные с stdin и швыряет их сразу в базу, используя запросы к bulk API. Такими темпами я за несколько часов залил более 10 Гбайт данных, что в целом неплохо — по крайней мере куда быстрее, чем обычный цикл.
WWW
Недавно вышла тоненькая, но очень интересная книжка, в которой упоминаются многие из описанных в статье трюков и хитростей, плюс есть много дополнительных приемов и утилит, также вполне достойных внимания. Она на английском языке, но это же тебя не остановит, верно?
Консольные монстры
Данных вокруг нас становится все больше, и работать над понижением уровня энтропии во вселенной все сложнее. Я надеюсь, что использование описанных трюков поможет тебе при выполнении рутинных задач с файлами, данными и процессами, будь ты data scientist’ом, инженером, волшебным гномом или даже сисадмином. В конце концов, можно даже придумать, как подобными трюками впечатлить девушку.











