

Баззворды наподобие Big Data, Data Science, Spark и Hadoop уже довольно плотно въелись в наш мозг. Обычно при их упоминании мы сразу представляем себе большой дата-центр, поверх которого работает мощная распределенная система, ищущая сложные закономерности и тренирующая модели. Но не зря кто-то из титанов сказал: «Вы заслуживаете получить второй компьютер, только когда научитесь правильно пользоваться первым». Многие утилиты командной строки *nix уже давно написаны на C, хорошо оптимизированы и позволяют решать многие современные задачи с очень высокой эффективностью всего лишь на одной машине. Не веришь? Тогда читай дальше.
(Уже прочитал? Тогда переходи ко второй части)
С резкого скачка популярности анализа данных уже прошло некоторое время, и простые смертные постепенно начинают понимать, чем именно занимаются эти самые пресловутые data scientist’ы и data-инженеры. Однако ворочание гигантскими массивами данных обычно требует времени, поэтому тяжелые джобы на Hadoop или Spark инженеры запускают далеко не каждый день. Если говорить точнее, то все, что можно автоматизировать, автоматизируется, но это отнюдь не значит, что можно плевать в потолок весь день, — есть множество небольших, но важных задач, которые приходится решать. И обычно это рутина, которая как раз и представляет собой то самое сочетание технологии и магии data-инженерии, прикладного программирования и научных методов. Я взял на себя смелость составить наверняка неполный, но включающий основное список:
- фильтрация набора записей по какому-то критерию;
- семплирование;
- извлечение конкретных колонок либо сортировка по ним;
- замена значений, их формата либо же заполнение пропусков;
- подсчет базовых статистических показателей и операции GroupBy.
А что там с данными? Обычно они лежат по старинке в какой-нибудь реляционной базе наподобие PostgreSQL, либо же они могут быть доступны через API, например социальной сети или корпоративного веб-сервиса. Иногда можно столкнуться с чем-то чуть более экзотическим вроде формата HDF5, однако топы чартов обычно занимает (как ни банально) куча tar.gz-файлов где-нибудь на HDFS или даже локально. Эти файлы разложены по частично детерминированной иерархии каталогов и представляют собой обычные CSV/TSV либо же логи какого-нибудь сервиса в определенном формате.
«Все ясно, — сразу скажет разработчик/аналитик. — Грузим все поблочно в Pandas либо же запускаем Hadoop MapReduce job’у». Стоп, серьезно? Это же просто файлы данных, разделенные на колонки и поля, нас с такими учили работать еще на вводных лекциях по Линуксу. Плюс они доступны с более-менее вменяемой скоростью чтения чаще всего не локально, а с какого-то сервера, на котором и Pandas-то соберется не всегда (например, из-за комбинации древнего CentOS’а и отсутствия админских прав). А уж использовать мощности корпоративного Hadoop’а для того, чтобы посчитать среднее арифметическое, да и ждать результата много минут — это как-то не выглядит эффективно.
Ах, если бы была возможность делать все перечисленные операции быстро, с использованием нескольких ядер CPU, читая файлы поколоночно и извлекая нужные данные регулярными выражениями, используя готовые, проверенные временем утилиты, написанные на низкоуровневом языке! OH WAIT~
Shell-команды на каждый день
Да, практически в любой *nix/BSD-системе присутствует командная оболочка Bash (или Zsh, или даже Tcsh), в которой типичный инженер проводит довольно большую долю своего рабочего времени. В винде с этим сильно хуже (не будем про PowerShell), но большинство команд вполне можно заставить работать через Cygwin. Вот список команд, которые мы используем каждый день: cat, wc, tar, sort, echo, chmod, ls, ps, grep, less, find, history. Дальше в тексте я подразумеваю, что этот стандартный минимум тебе известен (а если нет — прочитай man по тем, что незнакомы).
Кроме базового набора, существует также целый ряд команд, дающих дополнительные плюшки в отдельных случаях; часть из них — это разновидности приведенных выше. Давай глянем на некоторые.
seq — генерирует последовательность чисел с заданным шагом:
$ seq 4 # От 1 до 4
1
2
3
4
$ seq 7 -2 3 # От 7 до 3 с шагом –2
7
5
3
$ seq -f "Line %g" 3 # Небольшая шаблонизация
Line 1
Line 2
Line 3tr — производит простейшую замену символов во входном потоке:
$ echo "lol" | tr 'l' 'w'
wow
$ echo "OMG" | tr '[:upper:]' '[:lower:]'
omgzcat / gzcat / gunzip -c — то же, что cat, но для файлов, сжатых в gzip-архив. Первая команда под OS X работает иначе, поэтому можно поставить gzcat через brew install coreutils либо просто использовать третий вариант — он работает везде, хоть и длиннее.
head — выводит несколько (по умолчанию десять) строк с начала файла. Удобна тем, что не требует загрузки файла в память целиком. Помогает подглядеть формат данных, например названия колонок и пару строк значений в CSV.
$ head -n 100 file.csv # Задаем число строк рукамиtail — то же самое, только выводит строки не с начала, а n последних. И эту, и предыдущую команду можно безбоязненно запускать на файлах практически любого размера.
$ tail -n 100 # 100 последних строк
$ tail -n+100 file.csv # Выводим все строки файла до конца, начиная с сотойzgrep — аналог grep для поиска по содержимому файлов в архивах.
uniq — передать на вывод только неповторяющиеся строки:
$ echo "foo bar baz foo baz omg omg" | tr ' ' '\n' | sort | uniq -c # Сколько раз встречаем уникальные строки
1 bar
2 baz
2 foo
2 omgСтоит помнить о том, что по умолчанию uniq отслеживает только одинаковые строки, идущие подряд, поэтому, если хочется найти уникальные строки по всему входу, надо его сначала отсортировать.
shuf — делает случайную выборку из переданных на вход строк:
$ echo "foo bar baz foo baz omg omg" | tr ' ' '\n' | shuf -n 2 # Здесь 2 — размер выборки
omg
bazУ нас также есть готовая система pipe’инга, которую за нас реализует система, позволяя связывать стандартный вывод одной команды со стандартным вводом другой. В Bash это вертикальная черта между двумя командами, ну, ты знаешь:
$ cat jedi.txt | grep -v AnakinПравда, есть небольшой подвох — такая конструкция всегда при выполнении вернет exit-код последней команды в цепочке, даже если посередине что-то упало. Но мы же хотим быть в курсе! Поэтому в продакшене большинство shell-скриптов содержат такой вот вызов:
$ set -o pipefailТаким макаром мы перехватываем коды выхода у всех команд и падаем, если что не так. Однако это сразу может привести к новым открытиям — к примеру, ты знал, что grep возвращает ненулевой exit-код и повалит весь трубопровод, если просто ничего не найдет? Но эта ситуация тоже решаемая (злоупотреблять этим не стоит, но в случае grep ненулевой код по другой причине мы вряд ли когда-нибудь получим). Можно сделать вот так:
$ cat file | (grep "foo" || true) | less # Всегда хорошая мина при плохой игреДвойная вертикальная черта здесь означает, что вторая команда отработает только в случае ненулевого exit-кода первой, а круглые скобки запускают всю конструкцию в subshell’е, то есть как одну команду. Разумеется, все минусы такого подхода налицо — мы маскируем любые неудачи, однако иногда это все-таки помогает. Кстати, а как запустить вторую только при успехе первой? Правильно, через &&.
Ну и еще один хак: бывает, нам нужно объединить результат запуска нескольких независимых команд в один вывод и использовать его как часть нашего трубопровода. Делается это так:
$ { echo "1"; echo "2"; } | другая_командаОбрати внимание, что есть тонкая грань между использованием круглых скобок выше и фигурных здесь. Круглые скобки — это гарантированное создание сабшелла, то есть системный вызов fork() c ожиданием результата выполнения child-процесса. Фигурные же скобки — это просто ограничение области видимости и создание блока кода в контексте текущего шелла, как в языках программирования (которым, собственно, можно назвать и Bash).
Fun fact
Почему-то подсознание заставляет нас думать, что эти команды запускаются последовательно и начинают что-то делать, только когда приходит что-то на стандартный ввод. Чтобы избавиться от этого убеждения, попробуй запустить такую команду:
sleep 3 | echo 1Да, единицу мы увидим сразу, а потом будем еще три секунды ждать. Хитрость в том, что все команды в цепочке запускаются всегда одновременно, а в этом случае они просто еще и не ждут никаких данных на вход и не пишут ничего на выход.
Работа с HTTP
Как есть споры между любителями Nikon и Canon, так существуют и перепалки между приверженцами разных консольных HTTP-клиентов, например cURL и Wget. Я расскажу про cURL, потому что он лучше :).
Собственно, рассказывать особо и нечего — cURL позволяет довольно легко общаться по HTTP-протоколу с сервером, обрабатывать куки и редиректы, делать REST-запросы и выводить все это дело на stdout. Чего нам, вообще говоря, и хочется. Разумеется, если речь идет, скажем, о скачивании файла большого размера, то лучше его сохранить на диск, а потом по нему что-то считать, иначе при любой проблеме придется начинать все с самого начала и гонять трафик.
Я не буду сейчас в подробностях расписывать все хитрости с курлом (RTFM в помощь, поверь, это проще, чем делать запрос из программы на C/Java/Python), упомяну только, что выбор типа запроса делается так:
$ curl [-XGET|-XPOST|-XPUT|-XHEAD]А также стоит отметить полезный флаг -s, который запрещает выводить всякую отладочную информацию, например о прогрессе скачивания, на стандартный вывод. Все потому, что нам не нужны эти данные на стандартном вводе следующей программы, если код запущен в pipeline.
Итак, возьмем вот такую цепочку:
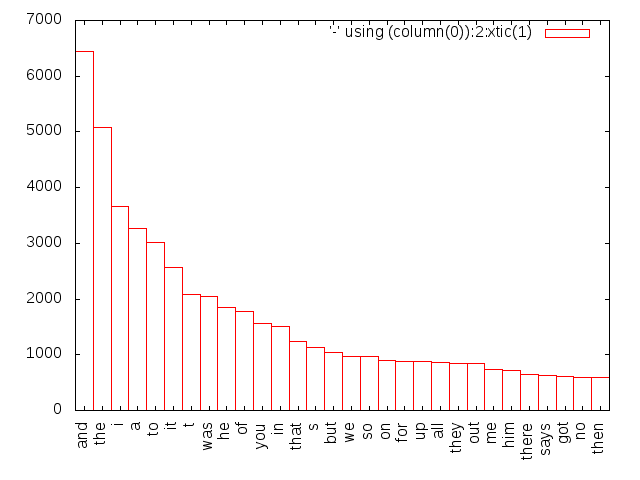
$ curl -s http://URL/some_file.txt | tr '[:upper:]' '[:lower:]' | grep -oE '\w+' | sort | uniq -c | sort -nr -k1,1 | head -n 100Все понятно? Как это нет? Качаем файл, конвертируем на лету в нижний регистр, разбиваем на буквочисленные (alphanumeric, ага) слова, сортируем, считаем гистограмму, которую снова сортируем, но уже по первому столбику в обратном порядке и численно, а не лексикографически. Осталось взять 100 первых строк, чтобы увидеть, какие слова в нашем тексте встречаются чаще всего.

Если же у тебя слово «гистограмма» ассоциируется только с красивыми картинками — что ж, ты сам напросился. Можно вспомнить, что у нас есть такая утилита, как gnuplot, и дописать в конец команды выше (через pipe, разумеется) вот такую жесть:
$ … | awk '{ print $2 "\t" $1 }' | gnuplot -p -e "set term png; set xtic rotate; plot '-' using (column(0)):2:xtic(1) smooth freq with boxes" > 123.pngПро awk я расскажу подробнее чуть дальше (к тому же тут все просто: мы меняем местами колонки и ставим разделителем между ними табуляцию), а вот про gnuplot читай сам. По функциональности он немногим уступает matplotlib’у (это навороченная библиотека для построения графиков из Python), но позволяет задавать практически любые параметры напрямую через консоль. Я не спорю, на каком-нибудь Pandas всю эту катавасию тоже можно написать в несколько строк, но это будет намного длиннее, и еще большой вопрос, что быстрее отработает.
Кстати, у тебя наверняка возникли вполне обоснованные сомнения насчет частого использования команды sort, и не зря: в случае больших объемов данных ее стоит применять крайне осторожно, так как память она съедает за один присест и без хлеба. Но у нее есть и несомненный плюс — она разбивает входные данные на блоки и пытается не засовывать в память все целиком. Именно поэтому даже на очень больших файлах и маленькой оперативке она когда-нибудь успешно закончит работать и выведет результат. Когда-нибудь.
Sed и awk
Чаще всего изнеженные макбуками и мышкой студенты забывают эти две команды сразу после лекции, потому что считают их неоправданно сложными и ненужными. Но одно дело — проникаться благоговейным ужасом при взгляде на тетрис, написанный на sed, и совсем другое — использовать несомненные удобства этих команд в каждодневной работе. Серьезно, давай вспомним базовые случаи и перестанем наконец их бояться.
Итак, sed — это потоковый редактор, то есть еще одна команда, которая принимает что-то на вход, обрабатывает определенным образом и выдает на выход. Так вот, в чем sed’у нет равных — это в замене строк по шаблону, для чего, собственно, его чаще всего и используют:
$ cat file.txt | sed 's/First/Second/g'Стоит обязательно обратить внимание на букву g в конце команды, что расшифровывается как greedy, то есть жадный. Хитрость здесь в том, что по умолчанию (без этой буквы) sed заменит только одно, самое первое вхождение подстроки в строку, даже если оно встречается несколько раз. Сложно сказать, почему так было сделано изначально, но предупрежден — значит вооружен.
Другая проблема, с которой часто сталкиваются при попытке использовать sed, — это так называемый синдром забора. При попытке использовать пути в качестве аргументов для подмены пользователи упираются в то, что надо экранировать каждый прямой слеш в путях, поскольку он является разделителем полей в самом sed, то есть получается что-то подобное:
$ cat paths.txt | sed 's/\/usr\/bin/\/usr\/share\/bin/g'Забавный момент здесь состоит в том, что в качестве разделителя полей в sed может использоваться любой символ, который не встречается в аргументах. То есть никто не запретит тебе написать так, и это будет работать:
$ cat paths.txt | sed 's:/usr/bin:/usr/share/bin:g'Еще одна хитрость состоит в использовании регулярных выражений. Как и в случае с grep, можно подключить расширенные регулярки с помощью -r или -E (первое — в *nix-системах, второе — в BSD, включая OS X). Причем второе поле (результат замены) может ссылаться на первое и частично его переиспользовать. Например, так мы загоним все слова в нижнем регистре в скобки:
$ echo "foo bar OMG" | sed -r "s/[a-z]+/(&)/g"
(foo) (bar) OMGАмперсанд просто подставляет в результат то, что у нас заматчилось с регуляркой в первом аргументе. Если же хочется именно «частичности» — можно вспомнить, что в регулярках есть так называемые группы, которые выделяются фигурными скобками и позволяют ссылаться на себя. Например, можно сделать так:
$ echo "Fooagra Foozilly" | sed -r "s/(Foo)[a-z]*/\1fel/g"
Foofel FoofelЗдесь \1 ссылается на то, что находится в круглых скобках в первом аргументе, то есть на строку "Foo". Вот такой вот фуфел.
Не умаляя остальных возможностей sed, давай пока на этом остановимся (кому интересно, что там у Гюльчатай под капюшоном, может почитать этот документ). Для большинства задач по замене значений этого уже достаточно.
Теперь про awk. У него другая сильная сторона — это извлечение данных из полей, они же колонки или секции. По сути, все, что от нас надо, — это знать разделитель (а по умолчанию awk пытается угадать его сам, и для TSV, например, это отлично действует), а дальше мы просто работаем со значениями в каждом из этих полей, как с переменными.
Чтобы пояснить, что я имею в виду, давай глянем на структуру программы на awk (да, awk — это вполне себе целый язык программирования, быстрый и удобный):
BEGIN {} {} END {}Несложно заметить, что у нас здесь три секции. Та, которая запускается в самом начале (BEGIN), обычно служит для инициализации переменных, а та, что в конце (END), — для вывода результата. В самых тривиальных программах, наподобие той, что была в одном из примеров выше, первая и последняя секции опускаются, а используется только центральная, которая принимает по строчке из входа за раз и автоматически раскладывает поля из нее по переменным с именами $1, $2 и так далее (нумерация с единицы).
$ cat file.txt | awk -F':' '{ print $2 }' # Выводим значение из второго поля для каждой строки
$ cat file.txt | awk '{ print $2 "," $1 }' # Берем первое и второе поля, меняем местами и выводим через запятую
$ cat file.txt | awk '{ print $1,$3,$2 }' OFS='\t' # Меняем разделитель для всех полей в выводе (будет там, где запятые в print)
$ cat file.txt | awk '{ x+=$2 } END { print x }' # Суммируем значения из второго поля и в конце выводим результатКак видно из последнего примера, в awk имеет место «утиная типизация», то есть тип переменной определяется исходя из того, какое значение мы ей пытаемся присвоить. Кроме того, по умолчанию числовые переменные равны нулю.
Есть еще пара встроенных переменных, которыми удобно пользоваться, — это NF и NR, соответственно, число полей в текущей строке и число строк, прочитанных на данный момент. В секции END второе, что логично, будет равно общему количеству строк на вводе, так что дополнительно это считать не нужно. Так что, пожалуй, вот последний пример — я там выше, кажется, что-то говорил про среднее арифметическое:
$ echo "4 8 15 16 23 42" | sed 's:\s:\n:g' | awk '{ s += $1 } END { print s / NR }'
18Думаю, тебе должно быть вполне понятно, что же именно здесь происходит.
А как же cut?
Кто сказал «cut»? Да, есть такая довольно простая команда для извлечения полей из входных данных. Но, во-первых, у нее очень уж неочевидный интерфейс (попробуй распарсить хоть вывод ps aux — натерпишься), а во-вторых, на больших объемах данных вопреки разумным предположениям она работает в полтора раза медленнее, чем awk-скрипт по выборке тех же полей. Вроде бы это связано с какими-то хитрыми проверками кодировок внутри, но из моего личного опыта — проще взять awk и не париться.
Все только начинается
Сегодня мы узнали или вспомнили довольно много страшных, но полезных слов. Никогда не надо заставлять человека делать за машину ее работу, и лично мне кажется, что каждое новое знание о своем сложном инструменте (это я сейчас про компьютер) позволит на шаг приблизиться к решению мировых проблем, будь то глобальное потепление или закончившееся в холодильнике пиво.
Анализ данных должен и будет популяризироваться, а люди постепенно научатся принимать все более взвешенные решения на основе данных, статистики и теории вероятностей. А мы в это время посидим и поделаем всякие забавные штуки в консольке. До скорой встречи, продолжение следует!











