


Современный мир — это мир данных и мир сетей. Компании хранят и обрабатывают все больше информации, которая используется и для работы с клиентами, и для анализа и принятия решений. Данные хранятся уже не только локально и доступны многим пользователям с разной ролью. В итоге современные СУБД, изначально разработанные для других целей, постепенно начинают обрастать всевозможными функциями. Посмотрим, что нового в недавнем релизе MS SQL Server 2016.
Знакомимся с MS SQL 2016
Новая версия разрабатывалась воистину ударными темпами. Не успели познакомиться с версией 2014 (вышла 1 апреля 2014 года), как буквально через год, в мае 2015-го, на конференции Ignite был представлен очередной релиз, а для загрузки выложили сразу Community Technology Preview 2. Финальная версия вышла 1 июня 2016 года. В новом релизе MS, очевидно, сделала шаг в направлении общей кодовой базы SQL Server и Azure SQL Database, что довольно логично. Функции, ранее появившиеся в Azure SQL DB (вроде Row-Level Security и Dynamic Data Masking), теперь доступны и для локального сервера.
Вместе с релизом SQL Server 2016 MS представила агрессивную программу перехода с СУБД лидера рынка Oracle (занимает примерно 40% против 21% у MS), включающую «бесплатную» лицензию (заплатить нужно будет за подписку на Software Assurance), инструменты для миграции и обучение персонала. При построении БД с нуля СУБД от Miсrosoft обойдется на порядок дешевле. Предлагаются две лицензии: одна основана на вычислительных мощностях (Core-based), вторая — на количестве пользователей или устройств (Server + Client Access License). Oracle работает под Linux, и здесь у MS тоже есть сюрприз: анонсировано, что новая версия также будет работать под управлением этой ОС. Хотя сам релиз под Linux выйдет примерно в середине 2017 года.
Реализовано пять версий: Enterprise, Standard, Express, Developer и Web. Версия Developer Edition доступна бесплатно и обладает всеми возможностями Enterprise, но предназначена исключительно для разработки и тестирования, ее нельзя использовать в рабочих средах. Числовые показатели по сравнению с 2014 практически не изменились. Максимальный размер баз данных 524 Пбайт, у Express — 10 Гбайт. Максимальный объем используемой памяти на экземпляр: Express — до 1 Гбайт, Standard — 128 Гбайт, остальные ограничены возможностями ОС. Максимальное количество ядер: Express — до четырех, Standard — 24 (в 2014 — 16).
Как принято, новый релиз поддерживает минус одно поколение ОС. Из списка выпали Win7 и Win2k8. Возможна установка SQL Server на все x64-редакции Windows от 8 и Win2012, в том числе и урезанные Core и Nano. Особо отмечается, что процессоры x86 больше не поддерживаются.
С нового релиза SQL Server Management Studio (SSMS) поставляется отдельно, а сам он теперь управляет всеми редакциями SQL Server от 2008 (включая будущую SQL 2016 под Linux). То есть теперь не придется держать несколько SSMS для работы с разными релизами СУБД. Установка SSMS возможна на Win7SP1+/Win2k8+.

Xakep #210. Краткий экскурс в Ethereum
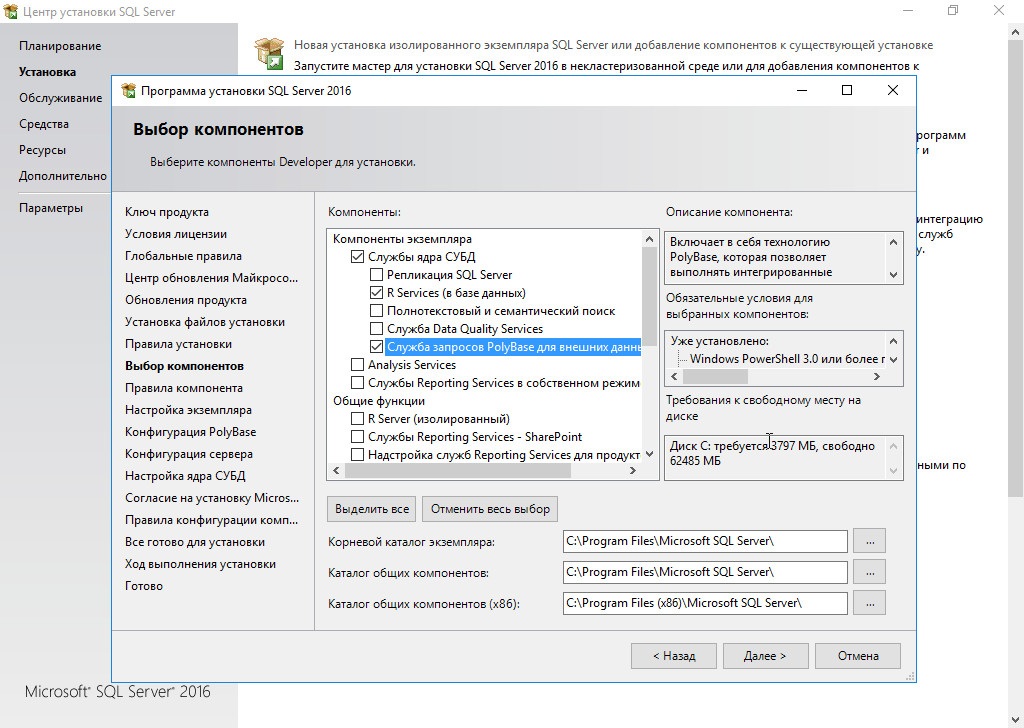
В SSMS появилось несколько полезных возможностей. Например, Live Query Statistics позволяет наблюдать за ходом выполнения запроса. Полученные сведения (время, количество данных, процент выполнения) можно использовать для оптимизации. Активируется функция при помощи кнопки Include Live Query Statistics, в сессии должен быть включен сбор статистики (SET STATISTICS XML ON, SET STATISTICS PROFILE ON). Модуль PowerShell для работы с MS SQL sqlps, идущий в комплекте SQL 2016, поддерживает управление всеми версиями от SQL2k (конечно, в более ранних версиях сервера будут недоступны некоторые функции). Также изменения коснулись набора дополнений к Visual Studio — SQL Server Data Tools для Visual Studio. Раньше были доступны две версии: собственно SSDT и SSDT-BI (Business Intelligence), теперь они объединены в один пакет.
В документе SQL Server 2016 and Windows Server 2016 Better Together разработчики приводят примеры, почему только сочетание MS Server 2016 и SQL Server 2016 обеспечит максимальную безопасность и производительность. Например, Win2016 поддерживает технологию энергонезависимой памяти Storage Class Memory (SCM), в том числе и NVDIMM — они заменяют обычные DIMM-модули памяти, но умеют хранить информацию при потере питания. Применяя их, можно добиться существенного прироста производительности. С помощью технологии Storage Spaces Direct на основе стандартных серверов с локальным хранилищем можно создать высокодоступное и масштабируемое хранилище данных.
Еще две технологии — Just-In-Time (JIT) и Just Enough Administration (JEA) — позволяют ограничить администратора в правах по времени или при помощи PowerShell делегировать пользователю ровно те права, которые ему нужны, чтобы выполнять работу.
Безопасность
Функции SQL Server, позволяющие обезопасить данные и бороться с угрозами, расширяются и совершенствуются от версии к версии. В основу положен принцип минимальных привилегий, доступ к информации через хранимые процедуры и определяемые пользователем функции, обеспечивающие доступ только к разрешенным ресурсам. Прозрачное шифрование данных и журналов (Transparent data encryption, TDE), шифрование на уровне ячеек и шифрование соединений защищают информацию от кражи. Плюс размещение файлов базы на Encrypting File System. Однако новые угрозы и задачи для SQL-сервера возникают постоянно, и инструменты безопасности не всегда с ними справляются.
В SQL Server 2016 появилось три больших нововведения, позволяющих защитить данные от действий недобросовестных сотрудников, гибко разграничить доступ и скрыть данные от администратора сервера. Это Always Encrypted, Row-Level Security и Dynamic Data Masking.
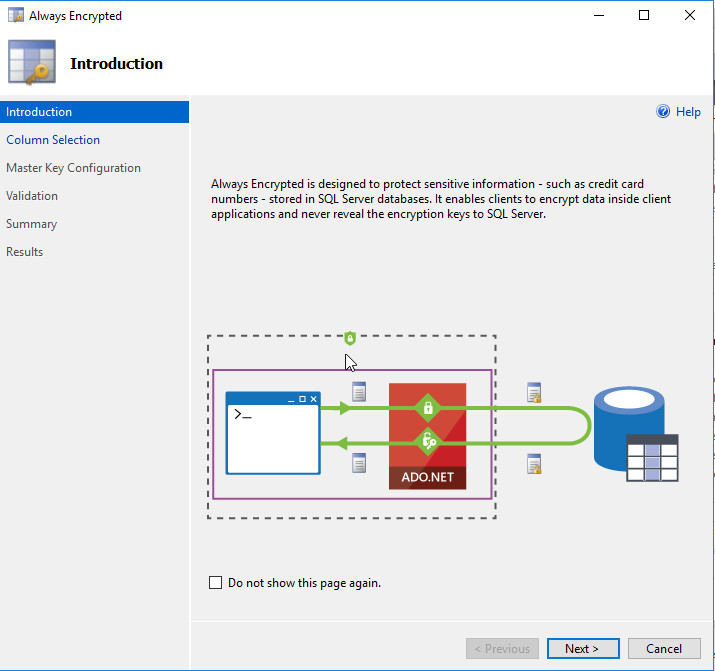
TDE шифрует данные всей базы в состоянии покоя, но сисадмин без проблем может получить доступ к данным, хранящимся в базе. Функция Always Encrypted, доступная в Enterprise (и Developer), позволяет шифровать и дешифровать данные внутри клиентских приложений, не раскрывая ключей шифрования SQL Server. Данные шифруются на уровне столбца как в покое, так и в памяти. То есть с Always Encrypted обеспечивается четкое разделение между владельцами данных и теми, кто управляет данными (но не должен иметь доступа). Теперь клиенты могут уверенно хранить конфиденциальную информацию на сторонних серверах, не беспокоясь об утечке.
Расшифрование производится с использованием расширенной клиентской библиотеки. Это приводит к важному ограничению Always Encrypted — библиотеки должны поддерживать клиент. Фактически сегодня с Always Encrypted работает единственная библиотека — ADO.NET 4.6 (.NET Framework 4.6). Также поддерживаются не все виды данных и некоторые функции (поиск, репликация, распределенные запросы, триггеры частично). Полный список доступен по ссылке. Использование Always Encrypted скажется также на производительности и потребует больше места под хранение зашифрованных данных.
Используется два вида ключей: ключи шифрования столбца (для непосредственно шифрования) и мастер-ключ столбца (защита ключей). И два вида шифрования: рандомизированное и детерминированное. Функция очень просто активируется при помощи мастера в SSMS (Tasks -> Encrypt Columns). Использование учетной записи с ALLOW_ENCRYPTED_VALUE_MODIFICATIONS дает возможность переносить старые данные в Always Encrypted.
Конфиденциальная информация, хранящаяся в БД, должна быть доступна только определенному кругу лиц. Например, поддержке банка необязательно знать весь номер кредитки, достаточно последних четырех цифр, чтобы ориентироваться (XXXX-XXXX-XXXX-1234). Традиционно задачу сокрытия информации возлагали на клиентские приложения, имевшие доступ к базе данных, сами данные приложение получало в полном объеме, что давало возможность их скомпрометировать.
Встроенная функция Dynamic Data Masking (DDM) в SQL Server 2016 и SQL Azure DB (с V12) позволяет ограничить доступ к конкретным полям данных, контролируя их вывод при запросе, и теперь реализовать контроль можно средствами самого сервера, оставляя приложению лишь отображение. DDM не требует вносить какие-либо изменения в процедуры БД или код приложения. Данные в самой базе остаются нетронутыми, не меняется их тип, и они полностью доступны авторизованным пользователям. Специальная команда UNMASK позволяет указывать непривилегированных пользователей, которым данные должны выводиться без маскировки:
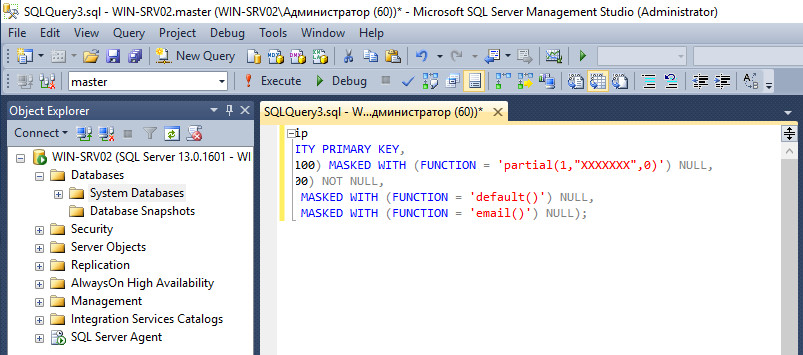
GRANT UNMASK to dbuserПравила DDМ определяются для конкретных столбцов при помощи масок, указывающих, как они будут отображаться при запросе. Поддерживается четыре вида масок: default (строковые заменяются XXXX, числовые — 0, дата — 1 января 1900 года), email, partial (настраиваемая) и случайные. В Azure DB есть еще маски для кредитных карточек и номера social security. Указывается маска как при создании ячейки, так и для уже существующей. Какого-то специального разрешения не требуется, достаточно стандартных — CREATE TABLE и ALTER.
CREATE TABLE Membership (
MemberID int IDENTITY PRIMARY KEY,
FirstName varchar(100) MASKED WITH (FUNCTION = 'partial(1,"XXXXXXX",0)') NULL,
LastName varchar(100) NOT NULL,
Phone varchar(12) MASKED WITH (FUNCTION = 'default()') NULL,
Email varchar(100) MASKED WITH (FUNCTION = 'email()') NULL
);Удалить маскировку так же просто:
ALTER COLUMN Phone DROP MASKEDМаска не поддерживает некоторые типы столбцов, например не работает с Always Encrypted, не поддерживается FILESTREAM, COLUMN_SET. DDМ-колонка не может быть ключевой для индекса FULLTEXT.
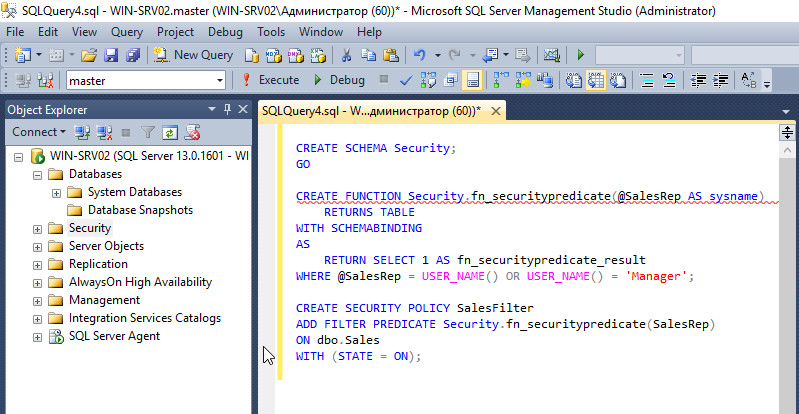
Модель безопасности SQL Server понимала лишь таблицы и столбцы. Строки защищались только с помощью самостоятельно написанных хранимых процедур или функций, которые можно было обойти. При использовании MS SQL обычно возможность контролировать выдачу реализовывали на клиентской стороне (хотя в Oracle 8i такая возможность была реализована еще в прошлом веке). Но всегда есть риск, что кто-то подключится напрямую к БД и получит данные. Теперь Row-Level Security стала доступна администраторам MS SQL.
Если DDМ позволяла контролировать вывод, то Row-Level Security (RLS, безопасность на уровне строк) предоставляет возможность создавать политики безопасности, ограничивающие доступ пользователям к конкретной информации в БД на основе логина, членства в группе, сессии и других параметров (даты, например). С RLS информация, не разрешенная к выдаче текущему пользователю, просто не попадает в результаты.
Реализация в самом движке исключает возможность обхода. Политика доступа настраивается на основе предикатов в CREATE SECURITY POLICY. Поддерживаются два типа предикатов безопасности: FILTER PREDICATE (контролирует вывод) и BLOCK PREDICATE (блокируются операции изменения). Есть и ограничения. Например, RLS несовместима с Filestream и PolyBase, отфильтрованные строки показываются в статистике DBCC SHOW_STATISTICS.
Полезные функции
В любой организации постепенно накапливается приличный объем данных, часть из которых нужна лишь изредка, отправить в архив их нельзя, и большее время они просто занимают ресурсы. Технология Stretch Database позволяет динамически размещать локальные базы данных на Azure. То есть мы можем у себя оставить таблицы, к которым обращаются часто, а «холодные» переместить в облако, приложения по-прежнему будут иметь к ним доступ как к локальным. В итоге увеличится производительность локального сервера и сократится время резервного копирования, поскольку оно касается только «горячих» данных. Если поместить «холодные» данные в отдельную таблицу, можно перенести всю таблицу, иначе используется фильтр, позволяющий отобрать нужные записи. При необходимости миграцию можно остановить или ограничить. Функция не требует изменений локального приложения.
Перед включением следует запустить Stretch Database Advisor, который поможет определить потенциальные таблицы и выявить проблемы. Включить Stretch Database можно при помощи Transact-SQL или в SSMS, выбрав Tasks -> Stretch -> Enable, после чего запустится специальный визард. Не поддерживаются некоторые типы столбцов (filestream, sql_variant, timestamp, xml) и функций (вычисляемые столбцы, XML-индексы, полнотекстовые индексы).
Источники данных сегодня самые разнообразные, и организациям приходится иметь дело с несколькими типами данных, анализ которых становится проблемой. PolyBase — новый движок, дающий возможность управлять реляционными и нереляционными данными, хранящимися в Hadoop/HDFS или Azure Blob Storage, при помощи обычных T-SQL-запросов. До сих пор был частью SQL Server Parallel Data Warehouse, появившегося для SQL 2008 R2, но теперь встроен в основную функциональность. Внешне обращение к HDFS выглядит так, как будто информация находится на локальном SQL-сервере, используется тот же синтаксис. Все остальное PolyBase берет на себя. Кроме собственно запросов, возможен экспорт и импорт данных. Для работы требует JRE 7.
Новое в T-SQL
Язык T-SQL также получил несколько новых функций, как больших, так и мелких. Рассмотрим лишь некоторые из них.
JSON — популярный формат текстовых данных для хранения неструктурированных данных и для обмена информацией в REST веб-службах. Некоторые сервисы Azure также используют JSON. До версии 2016 все задачи обработки JSON ложились на плечи разработчика, теперь разбор и хранение, импорт и экспорт данных, преобразование и форматирование запросов обеспечивает сам движок. Приложения и инструменты не видят разницы между значениями, взятыми из скалярных столбцов таблицы, и значениями, взятыми из столбцов в формате JSON.
Можно использовать значения из JSON-текста в любой части T-SQL-запроса (включая пункты WHERE, ORDER BY, GROUP BY). Отдельного типа данных не предусмотрено, для хранения используются стандартные varchar или nvarchar. Для работы с JSON реализовано несколько новых функций:
- ISJSON — проверка, является ли строка JSON;
- JSON_VALUE — извлечение скалярного значения;
- JSON_QUERY — извлечение объекта или массива;
- JSON_MODIFY — изменение части JSON-текста.
Функция OPENJSON преобразует массив JSON-объектов в таблицу, пригодную для импорта JSON-данных в SQL Server, в которой каждый объект представлен в виде одной строки, а пара ключ/значение возвращается в виде ячеек. Чтобы из реляционных данных сгенерировать JSON, следует использовать функцию FOR JSON, поддерживающую два варианта форматирования FOR JSON AUTO и FOR JSON PATH. Дополнительная опция WITHOUT_ARRAY_WRAPPER создает JSON без квадратных скобок. По умолчанию параметры, имеющие значение NULL, не будут включены в вывод. Если они нужны, следует в вызове FOR JSON использовать параметр INCLUDE_NULL_VALUES.
При тестировании, да и в работе очень часто приходится многократно удалять и создавать объекты в базе данных. Чтобы скрипт отработал нормально, приходится проверять наличие/отсутствие объекта. До SQL 2016 эта процедура была полностью на разработчике:
IF OBJECT_ID(N'dbo.tbl', 'U') IS NOT NULL DROP TABLE dbo.tbl;Новая функция IF EXISTS теперь позволяет очень просто проверить наличие объекта и упрощает написание кода:
DROP TABLE IF EXISTS dbo.tblIF EXISTS поддерживается практически для всех объектов (баз данных, процедур, таблиц, индексов).
Две функции COMPRESS и DECOMPRESS обеспечивают встроенную поддержку Gzip. На входе они могут принимать несколько типов данных, на выходе varbinary(max).
В TRUNCATE TABLE добавили возможность работы с отдельными секциями, а не только над всей таблицей. В FORMATMESSAGE можно использовать произвольную маску. Новая опция WITH (ONLINE = ON | OFF) для ALTER TABLE ... ALTER COLUMN позволит добавлять и удалять столбцы в режиме онлайн. При этом данные останутся доступны для чтения, а блокировка будет в конце операции. Процедура sp_execute_external_script позволяет выполнять сценарии в SQL Server на другом языке. В настоящее время поддерживается только R.
Заключение
Это далеко не все возможности, появившиеся в MS SQL 2016. Кроме описанного, есть еще Temporal Tables, улучшения в In-Memory, Query Store, встроенная аналитика, интегрируемая с ПО на базе языка R, и многое другое. Но для этой статьи, пожалуй, достаточно.












