


Содержание статьи
Наша компания является российским представительством глобальной группы Yusen Logistics. Как это нередко бывает, достоинства глобальных компаний оборачиваются их же недостатками, так как головные и региональные штаб-квартиры стараются организовать централизованное управление всем, зачастую без учета «поправок на местность». С этим, к сожалению, пришлось столкнуться и нам. С 2008 года YL-RU предоставляет услуги 3PL-оператора на российском рынке. В качестве WMS все это время использовалась система Warehouse Management for IBMi (WMi) производства Manhattan Associates (далее МА).
Серверы расположены в ЦОДах внутреннего ИТ-интегратора в Бельгии и Голландии. Вся инфраструктура и сама WMS обслуживалась и дорабатывалась бельгийской командой. Очевидно, что плюсом такого решения был относительно быстрый запуск с относительно низкими затратами. Компании достаточно было держать в штате двух эникейщиков, способных перевести запрос пользователя на английский и переправить его соответствующей группе поддержки.
Само собой, за такие удобства приходилось платить, и в нашем случае платить в евро. С сентября 2014 года это стало дорого, а с декабря — безумно дорого. Компания начала резать косты, в первую очередь валютные. Любые валютные ценники старались зафиксировать в рублях по приемлемому курсу.
Сработало со всеми, кроме наших бельгийцев. После очень долгих уговоров, финансовых обоснований, сотен страниц презентаций с графиками, отражающими негативный рост наших доходов и конкурентоспособности, RHQ все же разрешили нам внедрить WMS локально в России и задействовать локальных (читай «дешевых») специалистов для ее поддержки и развития.
От редакции
Данная статья не является специальным рекламным проектом. Это просто интересное описание чужого опыта :).
Выбор новой WMS
Нам дали свободу, но свободу на их условиях. Поскольку у группы заключен глобальный контракт в Manhattan Associates, то и выбирать новую WMS можно только из линейки MA, а это:
- WMi;
- SCALE;
- WMOS.
Первая и последняя отпали сразу: даже в «КОРУС Консалтинг», хоть он и локальный геопартнер MA в России (к сожалению, единственный), знали об этих системах достаточно поверхностно и не смогли бы нам оказать качественную поддержку ни при внедрении, ни в дальнейшем использовании. К функциональности самих систем претензий никаких быть не может, они растут и успешно развиваются с девяностых годов и к нашему времени уже успели стать громадными звездолетами среди систем управления складом. Собственно, стоимость внедрения и сопровождения сопоставима со стоимостью какого-нибудь Millennium Falcon.
Остался SCALE. С ним все наоборот. Система относительно молодая, некоторых вещей в ней еще не хватает, но она работает под управлением Windows и полностью базируется на .NET, что дает много возможностей для доработок и кастомизаций. На рынке есть достаточное количество специалистов, хорошо знающих систему снаружи и изнутри, ну и тот самый «КОРУС» съел далеко не одну собаку на внедрении SCALE абсолютно разношерстным клиентам в разных конфигурациях.
Тыл кажется прикрытым. Отлично! Давайте думать о техническом обеспечении фронта!
Оценка требований системы
А на фронте получается следующее:
- Как и многие системы такого рода, SCALE состоит из трех основных элементов:
- сервер БД (MS SQL);
- сервер приложения;
- сервер клиентского доступа (рекомендуется использование RDS для организации доступа клиентов).
- Система относится к классу business-critical, и по внутренним требованиям группы мы должны обеспечить ее отказоустойчивость, высокую доступность и сохранность данных. Опыт подсказывает, что с каждым пунктом требований стоимость локальной инфраструктуры смело умножается на два, а то и на три...
Получается, что для удовлетворения всех требований нам придется построить кластер как минимум на трех нодах, одной СХД (в идеале — двух) и паре оптоволоконных коммутаторов.
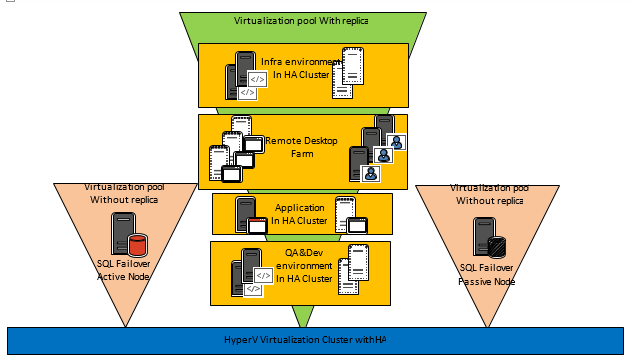

По нашему описанию нагрузки на систему и требованиям к отказоустойчивости в MA любезно составили рекомендации к инфраструктуре (sizing). Точнее, три сайзинга — каждый раз, пребывая, мягко говоря, в шоке от очередного расчета стоимости железа и лицензий, мы пересматривали свой подход и к SLA, и к количеству модулей самого SCALE, которые планировали приобрести.
Самый простой вариант боевой части инфраструктуры по рекомендациям MA представлен на рис. 1–3.

В итоге, после длительных обсуждений сойдясь на том, что часть модулей не даст большого прироста в производительности склада и не окупится в ближайшие пять лет, а сам склад в случае серьезного сбоя сможет продолжать работу без WMS максимум три часа, мы нашли компромисс между «хочу» и «могу» стоимостью в 50 тысяч долларов за оборудование и примерно 10 тысяч долларов за лицензии (только Microsoft).
Чтобы определить стоимость оборудования, мы запрашивали цены у HP, Lenovo и Fujitsu. Отдельная благодарность всем менеджерам за терпение и предоставленные расчеты.
Еще один фактор, который учитывался при расчетах, — это стоимость размещения оборудования в ЦОД уровня не ниже Tier III (требование глобальных политик группы). При ориентировочной стоимости в 30 долларов за unit в месяц на выходе получается сумма в 18 тысяч долларов (10 units на 60 месяцев). Не стоит забывать о приобретении расширенной гарантии на оборудование через три года, а это еще как минимум 5–6 тысяч. В общей сложности 84 тысячи долларов, и это без учета зарплаты сисадминов, утилизации пространства в резервном хранилище и при условии, что часть нашей инфраструктуры уже размещена в ЦОД и там есть сетевое оборудование и резервируемое подключение к интернету.
Кусается... А так как логистика и без того не самая богатая отрасль, то очень кусается.
А может, Azure?
Сразу оговорюсь, широкого практического опыта использования Azure ни у меня, ни у моих ребят в отделе не было. Мы всего лишь поглядывали в эту сторону, следили за обновлениями сервиса, почитывая по диагонали новостные рассылки от Microsoft.
Очевидные достоинства сервиса еще раз описывать бессмысленно, коснемся лишь части Pay as You Go. Именно она заставила нас серьезно рассматривать сервис в качестве альтернативы собственной инфраструктуре.
Рабочий график наших офисов составляет 12 часов в сутки, семь дней в неделю. Добавим по одному часу до и после рабочего дня, и получается, что мы можем использовать Azure около 434 часов в месяц (14 часов * 31 день) вместо 744 и платить только за них. Очень грубая прикидка показывает 40% экономии в месяц. За собственное железо так платить не получится — это факт. Заманчиво, но нечистый, как известно, кроется в деталях.
Наибольшие сомнения вызывали два момента:
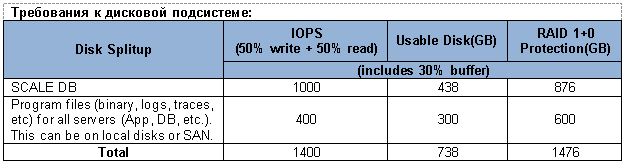
- Согласно рекомендациям MA дисковая подсистема сервера БД должна обеспечивать около 1000 операций ввода/вывода в секунду.
- Azure — это все же Shared Virtual Environment, и наш сервер БД рискует оказаться виртуальным соседом еще одного или, что хуже, нескольких требовательных серверов, используемых другими клиентами Microsoft.
Too cool to be true!
Итак, запрос отправлен менеджеру в MS, ждем. Первая телеконференция с менеджерами Microsoft была организована достаточно скоро и длилась примерно два с половиной часа. Ребята были уверены, что производительность Azure обеспечит наши потребности, а я, сейчас уже можно признаться, очень долго относился к решению с нездоровой долей скептицизма и пытался найти недостатки в Azure, которые помогли бы мне сделать выбор не в их пользу. Серьезно! Это сложно объяснить, но все время не покидало ощущение, что «слишком хорошо, чтобы быть правдой». Простите, господа, так уж воспитала жизнь.
По итогам конференций и переписок решено было протестировать три конфигурации среды:
- Эконом-вариант:
- 1xA0 Basic (DC, Print Server)
- 2xA3 Basic (SQL Server / Application Server + RDS / Client Access Server)
- Performance:
- 1xA0 Basic (DC, Print Server)
- 1xA3 Basic (RDS / Client Access Server)
- 1xD3_v2 (SQL Server / Application Server)
- Performance+:
- 1xA0 Basic (DC, Print Server)
- 1xA3 Basic (RDS / Client Access Server)
- 1xDS3_v3 + 2xP20 (SQL Server / Application Server)
Забегая вперед, скажу, что до тестирования третьей конфигурации дело не дошло. Причина чуть ниже. Но теоретически производительности дисков хватило бы с лихвой:
- два диска по 2300 IOPS в RAID 1 (пожертвуем рекомендованным RAID 1+0) при распределении R/W 50% на 50% дадут около 3450 IOPS;
- RAW IOPS = 2300 * 2 = 4600;
- Functional IOPS = (4600 0,5)/2 + 4600 0,5 = 3450.
IOPS — что это такое и как его считать.
Нагрузочное тестирование
Можно было остановиться и на теоретических расчетах, подкрепленных результатами тестов, полученными с помощью IOmeter, но, поскольку триальная подписка в Azure еще жива, а сомнения все еще терзают, решено было провести нагрузочное тестирование — эмулировать самый нагруженный день в работе склада.
Долго и мучительно искать ПО для этих целей не пришлось. В одной из бесед наш менеджер в MA обмолвился, что для нагрузочного тестирования они используют HP LoadRunner и еще какой-то сугубо внутренний продукт, который не предназначен для распространения. К слову, HP LR доступен и в Azure, но нам удобнее было установить его на несколько машин на земле, чтобы распараллелить задачи и сократить время на запись и оттачивание скриптов и потом перенести их в облако непосредственно перед тестированием.
Во время тестирования предполагалось пошагово эмулировать весь цикл жизни товара на складе, от его поступления и до отгрузки конечному заказчику:
- поступление товара (выгрузка из машины);
- размещение в стеллажи;
- подбор товара в заказы;
- отгрузка и закрытие заказа.
Все эти шаги выполняются с использованием мобильного терминала сбора данных, у нас это Motorola MC9000 и MC9100 под управлением Windows CE 5.0 и 6.0.
Виртуальные пользователи
— «Да не дерзнет никто создавать машину по образу и подобию человеческого разума», — процитировал Поль.
— Правильно. (...) Но на самом деле в Оранжевой Книге должно быть сказано: «Да не дерзнет никто создавать машину, ПОДМЕНЯЮЩУЮ человеческий разум».Фрэнк Герберт. Дюна
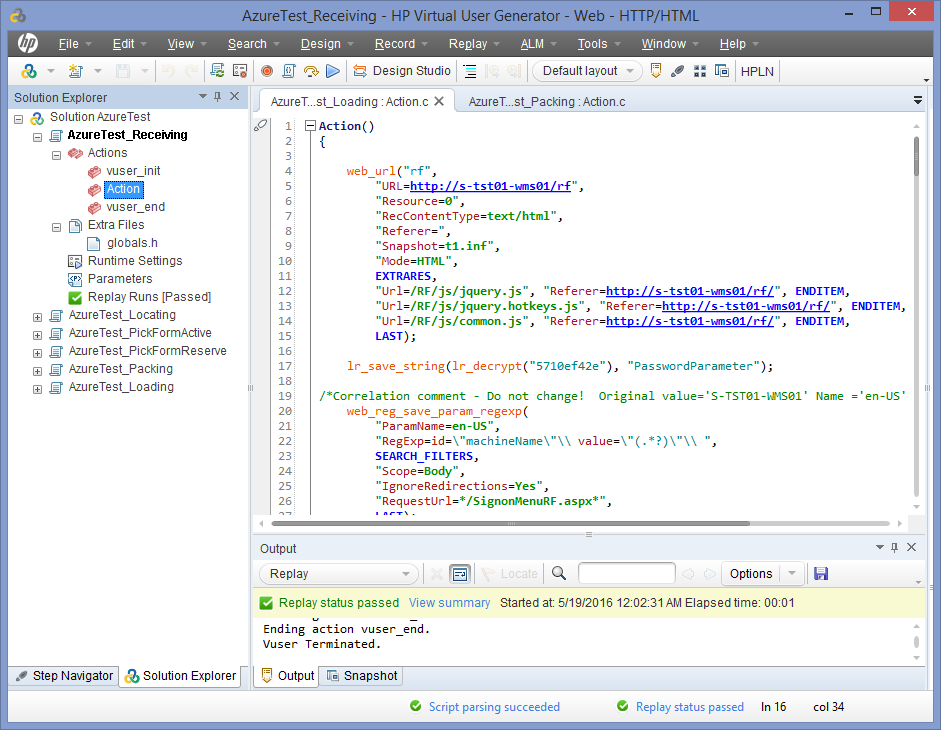
Мы решили создать виртуальных пользователей (ботов), которые бы имитировали действия живых людей через веб-оболочку SCALE, где и будут работать конечные пользователи. В пакете HP LoadRunner есть утилита Virtual User Generator (VUGEN), предназначенная для записи пользовательских скриптов и генерации виртуальных пользователей, которых потом можно использовать в необходимых количествах для нагрузочного теста. В VUGEN поддерживается масса протоколов, которые можно использовать как по отдельности, так и вместе (например, Citrix ICA, FTP, LDAP, ODBC, SAP GUI и множество других), но нас в первую очередь интересовал протокол Web HTTP/HTML, позволяющий записывать действия пользователя в браузере Internet Explorer.
Особой сложности в записи самих ботов в нашем случае не было — мы последовательно записали все пользовательские действия по приемке и отгрузке товара, его перемещению на складе и так далее. Поскольку предполагалось запускать одновременно до сорока ботов, то при каждом сеансе записи очередных пользователей мы не забывали закрывать все старые вкладки в браузере (чтобы избежать генерации кусков кода, не имеющих отношения к задаче) и разлогиниваться из веб-системы SCALE (это важный момент, потому что в дальнейшем каждый новый бот должен был заново авторизоваться в системе под уникальным логином, так что соответствующий код надо было иметь). В результате система генерировала код (язык, кстати, можно выбирать; мы выбрали С, и это, возможно, было не самым правильным решением, потому что в нем очень тяжело работать со строковыми переменными), который выглядит примерно так:
Action()
{
[...]
web_url("RF",
"URL=http://s-tst01-wms01/RF",
[...]
);
lr_save_string(lr_decrypt("5729fd2fe"), "PasswordParameter");
/* Correlation comment - Do not change! Original value='ru-RU' Name ='Defaultaabf6698-37ae-45ee' Type ='ResponseBased' */
web_reg_save_param_regexp(
"ParamName=Defaultaabf6698-37ae-45ee",
"RegExp=id=\"cultureName\"\\ value=\"(.*?)\"\\ ",
[...]
);
lr_think_time(15);
web_submit_form("ReceivingRF.aspx_3",
"Snapshot=t5.inf",
ITEMDATA,
"Name=RECID", "Value=AZURE_ASN16", ENDITEM,
LAST
);
lr_think_time(15);
web_submit_form("ReceivingRF.aspx_4",
"Snapshot=t6.inf",
ITEMDATA,
"Name=xRefItem", "Value=AZURE_TEST161", ENDITEM,
LAST
);
[...]
}
Получается некая болванка, которую надо тщательно допиливать, чтобы она заработала правильно. Что важно помнить: если работа с кодом ботов ведется в рамках одного проекта в VUGEN (он там называется Solution), то для каждого бота надо создавать отдельный новый скрипт (они добавляются там примерно как вкладки в браузере, вкладки можно переименовывать, если нужно).
Поскольку код довольно тяжеловесный (суммарное количество строк кода для сорока ботов получилось почти 80 000 — да, восемьдесят тысяч), то некоторые моменты не получается заметить сразу. Например, первое время боты выполняли только первый шаг итерации; при разборе полетов выяснилось, что в веб-приложении SCALE используется сквозная последовательная нумерация пользовательских форм. А это значит, что даже при возврате в основное меню форма ReceivingRF.aspx_3 получает имя ReceivingRF.aspx_13 (для примера взята форма из бота, который занимался приемкой товара, он выполняет это действие в десять шагов) и так далее, то есть нельзя просто копировать нужные участки кода, надо следить за корректной нумерацией. Задания для ботов были подготовлены заранее в самой среде SCALE, а каждому боту выдан свой собственный участок работы, что было жестко зашито в коде.
Как инструмент VUGEN довольно гибок: например, понравилась возможность в один клик превращать часть параметров из статичных в переменные (скажем, идентификатор сессии бота), есть цветовое выделение синтаксиса кода, удобные инструменты для работы с текстом, которые работают не только с текущим кодом, но и со всем проектом сразу. После первичной фазы тестирования «на земле», когда работа ботов была отлажена (на это ушла почти неделя), был сгенерирован поведенческий сценарий (для этого предназначена утилита HP Controller), с указанием количества ботов и задержкой их запуска (чтобы не все скопом пытались лезть на сервер). Он был протестирован и отработал практически без эксцессов (на самом деле в консоли в живом режиме было видно, что боты генерируют огромное количество ошибок, но все они никак не влияли на выполнение их задачи, потому что в основном были связаны с ошибками исполнения Java-скриптов веб-оболочки).
Сам по себе Controller поразил жутким интерфейсом добавления ботов (плохо работает с ботами, расположенными в разных папках, каждого бота приходится добавлять руками вместо пакетной обработки, нельзя создать сорок уникальных ботов в один клик, приходилось каждому вручную назначать соответствующий скрипт), но зато он на выходе дает очень подробную и удобную статистику, которую можно экспортировать не только во встроенный анализатор, но и в Excel и в XML для изучения.
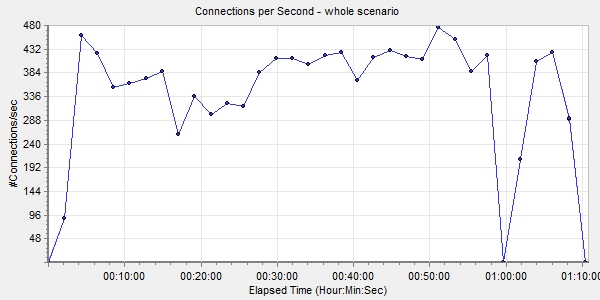
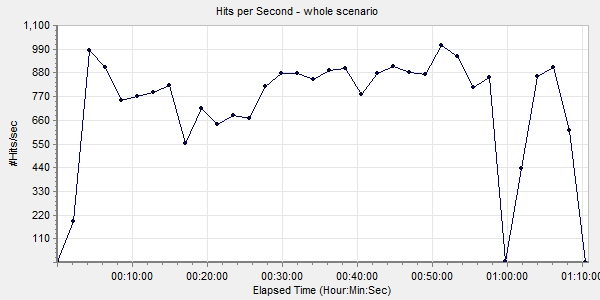
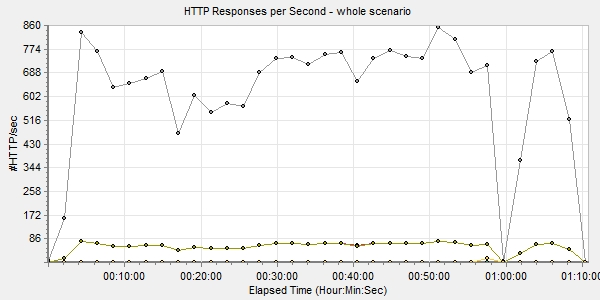
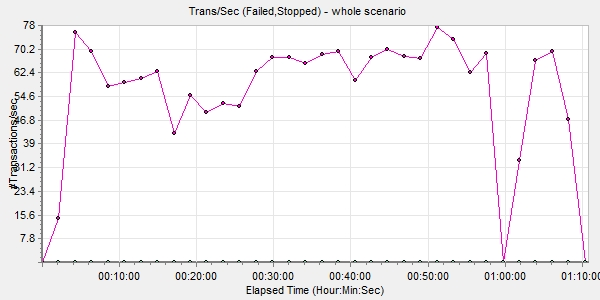
После отработки сценария в тестовой среде файлы сценария и скрипты ботов были перенесены в Azure, где уже был развернут LoadRunner. На что мы рекомендовали бы обращать внимание при записи скриптов для тестирования сценариев Web HTTP/HTML — это на параметр Think Time. Это время, в течение которого живой посетитель странички читает ее содержимое, прежде чем нажать следующую кнопку или ссылку. Без этого параметра боты бездумно щелкают ссылку за ссылкой, не дожидаясь загрузки следующей станицы, пытаются кликнуть ссылки на ней, естественно, не находят нужный элемент и отваливаются с ошибкой. Плюс web-сервер, естественно, воспринимает такое поведение как флуд и блокирует подключение.
Результаты тестирования
— Итак, покупаем ее?
— Нет, мне нужна другая машина.
— Какая же?
— Электронный калькулятор — он будет работать за троих бухгалтеров и в три раза быстрее.
Укрощение строптивого (Il Bisbetico domato)
Как говорилось выше, одно из сомнений в производительности Windows Azure основывалось на том, что среда shared и можно было оказаться соседом какой-нибудь прожорливой виртуальной машины другого клиента MS. Вдобавок в зависимости от времени дня нагрузка на системы так или иначе возрастает: люди просыпаются, приходят на работу, окунаются в рутину повседневности, наполненную графиками, таблицами, отчетами и презентациями для начальства, электронными письмами, звонками и чатами в Skype for Business. Для них это «отчет медленно строится», а для нас — «серверу не хватает ресурсов»...
Для чистоты эксперимента было решено запустить тесты несколько раз в день в разное, предположительно пиковое время (10:00–12:00) для различных европейских часовых поясов. Параллельно в Azure была включена запись базовых, сетевых, SQL-метрик и журнал IIS. Первое, что хочу отметить по итогам тестов: большого разброса в показателях не было. То есть с одними и теми же операциями в разное время дня виртуалки справлялись примерно одинаково.
День первый
Инфраструктура «Эконом-вариант»:
- 1xA0 Basic (DC, Print Server)
- 2xA3 Basic (SQL Server / Application Server + RDS / Client Access Server)
На RDS-сервере ничего особо интересного не происходило, 40 VUser’ов поделили между собой примерно 6 Гбайт оперативной памяти и примерно 80% производительности CPU. Основной подопытный у нас был SQL/App-сервер.
Вкратце — за каждый запуск теста было выполнено следующее:
- Принято 15 поставок товара примерно на 270 позиций в общей сложности.
- Создано и завершено порядка 540 заданий на размещение товара (это когда палету пересчитывают, обматывают стретч-пленкой и ставят в стеллаж для хранения, при этом в систему вносится информация о товаре на каждой конкретной палете и точном адресе ее расположения на складе).
- Создано 140 заказов по 10 линий.
- Создано и завершено 190 заданий на подбор товара.
- Упаковано (пересчитано и подготовлено к отгрузке) и отгружено 190 заказов.
Среднее время завершения теста — 1 час 15 минут.
Графики производительности можно увидеть на соответствующих изображениях.
Процессор:
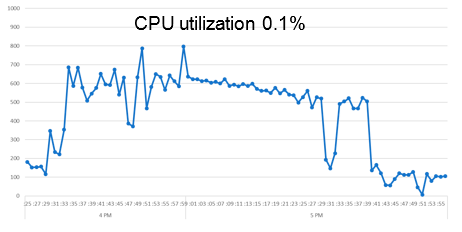
Основные скачки нагрузки наблюдались на операциях приемки и размещения товара, так как прежде, чем сказать, куда размещать каждую конкретную палету, система анализирует размерно-весовые характеристики и количество товара на ней, сроки годности, правила отгрузки и еще несколько условий. Это один из самых сложных процессов с точки зрения как логики, так и настройки и обработки.
RAM:
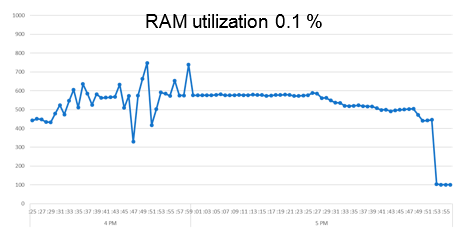
Наблюдаются примерно такие же скачки.
HDD:
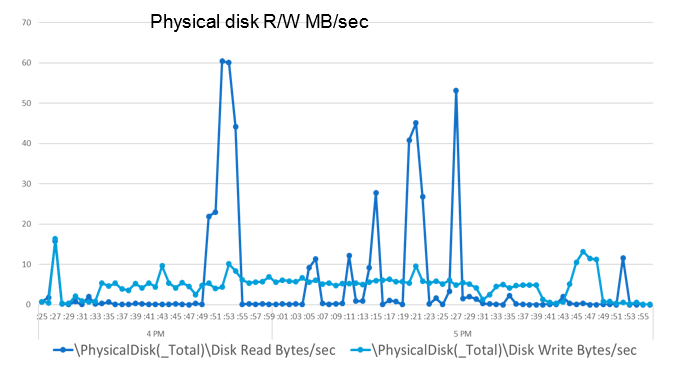
Ну и гвоздь программы, то, ради чего все это затеялось, — встречайте: ДИСК! Возможно, из-за того, что система в целом не спешила читать и писать данные, запись на диск колебалась в районе 5–10 Мбайт/с. При этом никаких проблем на стороне SQL не наблюдалось абсолютно. Ни тебе ошибок блокировки записей, ни тебе большой очереди. Ровным счетом ничего, обычная плавная работа.
Касательно скачков при чтении: первый, самый сильный и самый продолжительный, происходил в момент так называемого запуска волны — процесса, при котором система анализирует поступившие заказы на отгрузку и генерирует задания на подбор, содержащие инструкции для операторов склада о том, какой товар, где, сколько и в какой последовательности брать. Дальше сами процессы подбора, упаковки и закрытия заказов тоже ознаменованы характерными скачками объемов считываемой информации, но вызвано это только тем, что все боты выполняли эти задачи практически одновременно. В реальной жизни такие ситуации почти невозможны.
День второй
Инфраструктура Performance:
- 1xA0 Basic (DC, Print Server)
- 1xA3 Basic (RDS / Client Access Server)
- 1xD3_v2 (SQL Server / Application Server)
Сказать по правде, после первого прохода теста мы подумали, что «что-то пошло не так». Боты перестали работать через 35 минут после запуска. Стали искать ошибку, пошли по каждому шагу — ан нет, все выполнено. Последующие пять запусков показали примерно такие же результаты. Графики производительности можно увидеть на соответствующих изображениях.
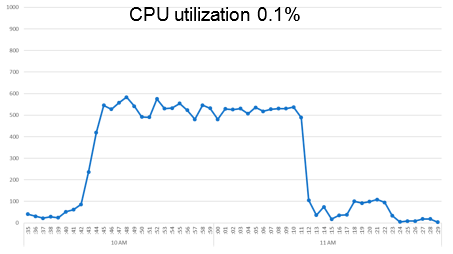
Процессор:
Все спокойно и без критических всплесков.
RAM:
Эта «мадам» была крайне невозмутима, ей вообще было все равно. Практически никаких эмоций.
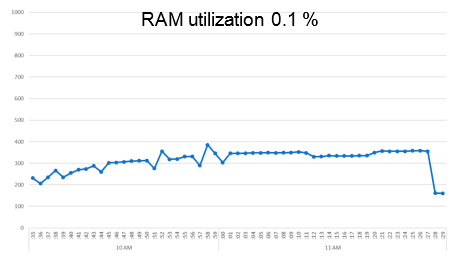
HDD:
А вот диск понервничал. Вот тут для меня остается загадкой, почему при запуске волны скачок был только до 10 Мбайт/с, а запись только в редких случаях спустилась ниже 10.
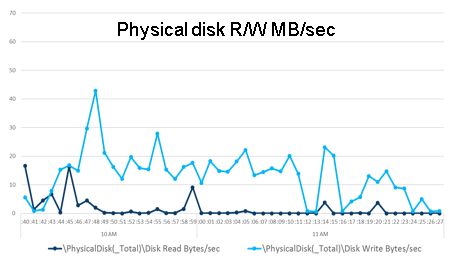
Как бы то ни было, результаты двух дней тестов нас более чем удовлетворили. Для понимания: один прогон виртуальных пользователей эмулировал объем работы нашего склада примерно за два дня в средний сезон. В этот момент мы жалели только о том, что коробки физически остаются на месте :).












