Стек ELK
После установки сервисов логи разбросаны по каталогам и серверам, и максимум, что с ними делают, — это настраивают ротацию (кстати, не всегда). Обращаются к журналам, только когда обнаруживаются видимые сбои. Хотя нередко информация о проблемах появляется чуть раньше, чем падает какой-то сервис. Централизованный сбор и анализ логов позволяет решить сразу несколько проблем. В первую очередь это возможность посмотреть на все одновременно. Ведь сервис часто представляется несколькими подсистемами, которые могут быть расположены на разных узлах, и если проверять журналы по одному, то проблема будет не сразу ясна. Тратится больше времени, и сопоставлять события приходится вручную. Во-вторых, повышаем безопасность, так как не нужно обеспечивать прямой доступ на сервер для просмотра журналов тем, кому он вообще не нужен, и тем более объяснять, что и где искать и куда смотреть. Например, разработчики не будут отвлекать админа, чтобы он нашел нужную информацию. В-третьих, появляется возможность парсить, обрабатывать результат и автоматически отбирать интересующие моменты, да еще и настраивать алерты. Особенно это актуально после ввода сервиса в работу, когда массово всплывают мелкие ошибки и проблемы, которые нужно как можно быстрее устранить. В-четвертых, хранение в отдельном месте позволяет защитить журналы на случай взлома или недоступности сервиса и начать анализ сразу после обнаружения проблемы.
Есть коммерческие и облачные решения для агрегации и анализа журналов — Loggly, Splunk, Logentries и другие. Из open source решений очень популярен стек ELK от Elasticsearch, Logstash, Kibana. В основе ELK лежит построенный на базе библиотеки Apache Lucene поисковый движок Elasticsearch для индексирования и поиска информации в любом типе документов. Для сбора журналов из многочисленных источников и централизованного хранения используется Logstash, который поддерживает множество входных типов данных — это могут быть журналы, метрики разных сервисов и служб. При получении он их структурирует, фильтрует, анализирует, идентифицирует информацию (например, геокоординаты IP-адреса), упрощая тем самым последующий анализ. В дальнейшем нас интересует его работа в связке с Elasticsearch, хотя для Logstash написано большое количество расширений, позволяющих настроить вывод информации практически в любой другой источник.
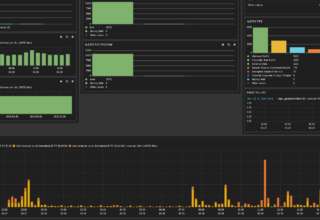
И наконец, Kibana — это веб-интерфейс для вывода индексированных Elasticsearch логов. Результатом может быть не только текстовая информация, но и, что удобно, диаграммы и графики. Он может визуализировать геоданные, строить отчеты, при установке X-Pack становятся доступными алерты. Здесь уже каждый подстраивает интерфейс под свои задачи. Все продукты выпускаются одной компанией, поэтому их развертывание и совместная работа не представляет проблем, нужно только все правильно соединить.
В зависимости от инфраструктуры в ELK могут участвовать и другие приложения. Так, для передачи логов приложений с серверов на Logstash мы будем использовать Filebeat. Кроме этого, также доступны Winlogbeat (события Windows Event Logs), Metricbeat (метрики), Packetbeat (сетевая информация) и Heartbeat (uptime).
Установка Filebeat
Для установки предлагаются apt- и yum-репозитории, deb- и rpm-файлы. Метод установки зависит от задач и версий. Актуальная версия — 5.х. Если все ставится с нуля, то проблем нет. Но бывает, например, что уже используется Elasticsearch ранних версий и обновление до последней нежелательно. Поэтому установку компонентов ELK + Filebeat приходится выполнять персонально, что-то ставя и обновляя из пакетов, что-то при помощи репозитория. Для удобства лучше все шаги занести в плейбук Ansible, тем более что в Сети уже есть готовые решения. Мы же усложнять не будем и рассмотрим самый простой вариант.
Подключаем репозиторий и ставим пакеты:
$ sudo apt-get install apt-transport-https
$ wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
$ echo "deb https://artifacts.elastic.co/packages/5.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-5.x.list
$ sudo apt-get update && sudo apt-get install filebeatВ Ubuntu 16.04 с Systemd периодически всплывает небольшая проблема: некоторые сервисы, помеченные мейнтейнером пакета как enable при старте, на самом деле не включаются и при перезагрузке не стартуют. Вот как раз для продуктов Elasticsearch это актуально.
$ sudo systemctl enable filebeatВсе настройки производятся в конфигурационном файле /etc/filebeat/filebeat.yml, после установки уже есть шаблон с минимальными настройками. В этом же каталоге лежит файл filebeat.full.yml, в котором прописаны все возможные установки. Если чего-то не хватает, то можно взять за основу его. Файл filebeat.template.json представляет собой шаблон для вывода, используемый по умолчанию. Его при необходимости можно переопределить или изменить.
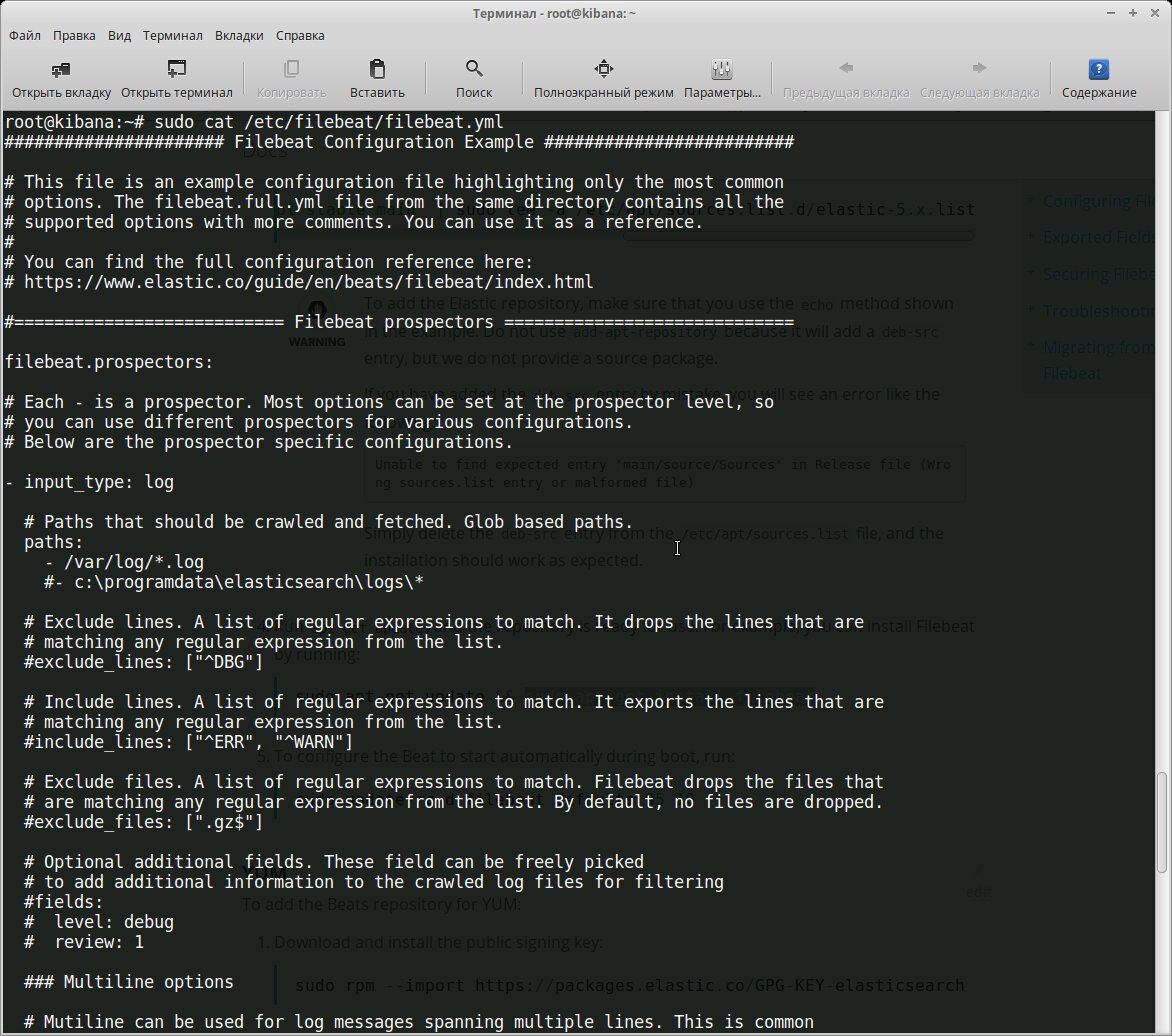

Нам нужно, по сути, выполнить две основные задачи: указать, какие файлы брать и куда отправлять результат. В установках по умолчанию Filebeat собирает все файлы в пути /var/log/*.log, это означает, что Filebeat соберет все файлы в каталоге /var/log/, заканчивающиеся на .log.
filebeat.prospectors:
- input_type: log
paths:
- /var/log/*.log
document_type: logУчитывая, что большинство демонов хранят логи в своих подкаталогах, их тоже следует прописать индивидуально или используя общий шаблон:
- /var/log/*/*.logИсточники с одинаковым input_type, log_type и document_type можно указывать по одному в строке. Если они отличаются, то создается отдельная запись.
- paths:
- /var/log/mysql/mysql-error.log
fields:
log_type: mysql-error
- paths:
- /var/log/mysql/mysql-slow.log
fields:
log_type: mysql-slow
...
- paths:
- /var/log/nginx/access.log
document_type: nginx-access
- paths:
- /var/log/nginx/error.log
document_type: nginx-errorПоддерживаются все типы, о которых знает Elasticsearch.
Дополнительные опции позволяют отобрать только определенные файлы и события. Например, нам не нужно смотреть архивы внутри каталогов:
exclude_files: [".gz$"]По умолчанию экспортируются все строки. Но при помощи регулярных выражений можно включить и исключить вывод определенных данных в Filebeat. Их можно указывать для каждого paths.
include_lines: ['^ERR', '^WARN']
exclude_lines: ['^DBG']Если определены оба варианта, Filebeat сначала выполняет include_lines, а затем exclude_lines. Порядок, в котором они прописаны, значения не имеет. Кроме этого, в описании можно использовать теги, поля, кодировку и так далее.
Теперь переходим к разделу Outputs. Прописываем, куда будем отдавать данные. В шаблоне уже есть установки для Elasticsearch и Logstash. Нам нужен второй.
output.logstash:
hosts: ["localhost:5044"]Здесь самый простой случай. Если отдаем на другой узел, то желательно использовать авторизацию по ключу. В файле есть шаблон.
Чтобы посмотреть результат, можно выводить его в файл:
output:
...
file:
path: /tmp/filebeatНелишними будут настройки ротации:
shipper:
logging:
files:
rotateeverybytes: 10485760 # = 10MBЭто минимум. На самом деле параметров можно указать больше. Все они есть в full-файле. Проверяем настройки:
$ filebeat.sh -configtest -e
....
Config OKПрименяем:
$ sudo systemctl start filebeat
$ sudo systemctl status filebeatСервис может работать, но это не значит, что все правильно. Лучше посмотреть в журнал /var/log/filebeat/filebeat и убедиться, что там нет ошибок. Проверим:
$ curl -XPUT 'http://localhost:9200/_template/filebeat' -d@/etc/filebeat/filebeat.template.json
{"acknowledged":true}Еще важный момент. Не всегда журналы по умолчанию содержат нужную информацию, поэтому, вероятно, следует пересмотреть и изменить формат, если есть такая возможность. В анализе работы nginx неплохо помогает статистика по времени запроса.
$ sudo nano /etc/nginx/nginx.conf
log_format logstash '$remote_addr - [$time_local] $host "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" $request_time '
'$upstream_response_time $request_uuid';
access_log /var/log/nginx/access.log logstash;Ставим Logstash
Для Logstash нужна Java 8. Девятая версия не поддерживается. Это может быть официальная Java SE или OpenJDK, имеющийся в репозиториях дистрибутивов Linux.
$ sudo apt install logstash
$ sudo systemctl enable logstashКонвейер Logstash имеет два обязательных элемента: input и output. И необязательный — filter. Плагины ввода берут данные из источника, выходные — записывают по назначению, фильтры изменяют данные по указанному шаблону. Флаг -e позволяет указать конфигурацию непосредственно в командной строке, что можно использовать для тестирования. Запустим самый простой конвейер:
$ /usr/share/logstash/bin/logstash -e 'input { stdin { } } output { stdout {} }'Он ничего умного не делает, просто выводит то, что пришло на stdin. Вводим любое сообщение, и Logstash его продублирует, добавив метку времени.

Все конфигурационные файлы находятся в /etc/logstash. Настройки в /etc/logstash/startup.options, jvm.options определяют параметры запуска, в logstash.yml параметры работы самого сервиса. Конвейеры описываются в файлах в /etc/logstash/conf.d. Здесь пока нет ничего. Как располагать фильтры, каждый решает сам. Можно подключения к сервисам описывать в одном файле, разделять файлы по назначению — input, output и filter. Как кому удобно.
Подключаемся к Filebeat.
$ sudo nano /etc/logstash/conf.d/01-input.conf
input {
beats {
port => 5044
}
}Здесь же при необходимости указываются сертификаты, которые требуются для аутентификации и защиты соединения. Logstash самостоятельно может брать информацию с локального узла.
input {
file {
path => "/var/log/nginx/*access*"
}
}В примере beats и file — это названия соответствующих плагинов. Полный их список для inputs, outputs и filter и поддерживаемые параметры доступны на сайте.
После установки в систему уже есть некоторые плагины. Их список проще получить при помощи специальной команды:
$ /usr/share/logstash/bin/logstash-plugin list
$ /usr/share/logstash/bin/logstash-plugin list --group outputСверяем список с сайтом, обновляем имеющиеся и ставим нужный:
$ /usr/share/logstash/bin/logstash-plugin update
$ /usr/share/logstash/bin/logstash-plugin install logstash-output-geoip --no-verifyЕсли систем много, то можно использовать logstash-plugin prepare-offline-pack для создания пакета и распространения на другие системы.
Отдаем данные на Elasticsearch.
$ sudo nano /etc/logstash/conf.d/02-output.conf
output {
elasticsearch {
hosts => ["localhost:9200"]
}
}И самое интересное — фильтры. Создаем файл, который будет обрабатывать данные с типом nginx-access.
$ sudo nano /etc/logstash/conf.d/03-nginx-filter.conf
filter {
if [type] == "nginx-access" {
grok {
match => { "message" => "%{NGINXACCESS}" }
overwrite => [ "message" ]
}
date {
locale => "en"
match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ]
}
}
}Для анализа данных в Logstash может использоваться несколько фильтров. Grok, наверное, лучший вариант, позволяющий отобрать любые неструктурированные данные во что-то структурированное и запрашиваемое. По умолчанию Logstash содержит приблизительно 120 шаблонов. Просмотреть их можно в github.com. Если их не хватает, легко добавить свои правила, указав прямо в строке match, что очень неудобно, или прописав все в отдельном файле, задав уникальное имя правилу и сказав Logstash, где их искать (если не установлена переменная patterns_dir):
patterns_dir => ["./patterns"] Для проверки корректности правил можно использовать сайт grokdebug или grokconstructor, там же есть еще готовые паттерны для разных приложений.
Создадим фильтр для отбора события NGINXACCESS для nginx. Формат простой — имя шаблона и соответствующее ему регулярное выражение.
$ mkdir /etc/logstash/patterns
$ cat /etc/logstash/patterns/nginx
NGUSERNAME [a-zA-Z.@-+_%]+
NGUSER %{NGUSERNAME}
NGINXACCESS %{IPORHOST:http_host} %{IPORHOST:clientip} [% {HTTPDATE:timestamp}] "(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" %{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS:referrer} %{QS:agent} %{NUMBER:request_time:float} ( %{UUID:request_id})Перезапускаем:
$ sudo service logstash restartУбеждаемся в журналах, что все работает.
$ tail -f /var/log/logstash/logstash-plain.log
[INFO ][logstash.inputs.beats ] Beats inputs: Starting input listener {:address=>"localhost:5044"}
[INFO ][logstash.pipeline ] Pipeline main started
[INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}Ставим Elasticsearch и Kibana
Самое время поставить Elasticsearch:
$ sudo apt install elasticsearch
$ sudo systemctl enable elasticsearchПо умолчанию Elasticsearch слушает локальный 9200-й порт. В большинстве случаев лучше так и оставить, чтобы посторонний не мог получить доступ. Если сервис находится внутри сети или доступен по VPN, то можно указать внешний IP и изменить порт, если он уже занят.
$ sudo nano /etc/elasticsearch/elasticsearch.yml
#network.host: 192.168.0.1
#http.port: 9200Также стоит помнить, что Elasticsearch любит ОЗУ (по умолчанию запускается с -Xms2g -Xmx2g): возможно, придется поиграть значением, уменьшая или увеличивая его в файле /etc/elasticsearch/jvm.options не выше 50% ОЗУ.
С Kibana то же самое:
$ sudo apt-get install kibana
$ sudo systemctl enable kibana
$ sudo systemctl start kibanaПо умолчанию Kibana стартует на localhost:5601. В тестовой среде можно разрешить подключаться удаленно, изменив в файле /etc/kibana/kibana.yml параметр server.host. Но так как какой-то аутентификации не предусмотрено, лучше в качестве фронта использовать nginx, настроив обычный proxy_pass и доступ с htaccess.
Первым делом нужно сказать Kibana об индексах Elasticsearch, которые нас интересуют, настроив один или несколько шаблонов. Если Kibana не найдет в базе шаблона, то и не даст его активировать при вводе. Самый простой шаблон * позволяет увидеть все данные и сориентироваться. Для filebeat пишем filebeat-* и в поле Time-feald name — @timestamp.
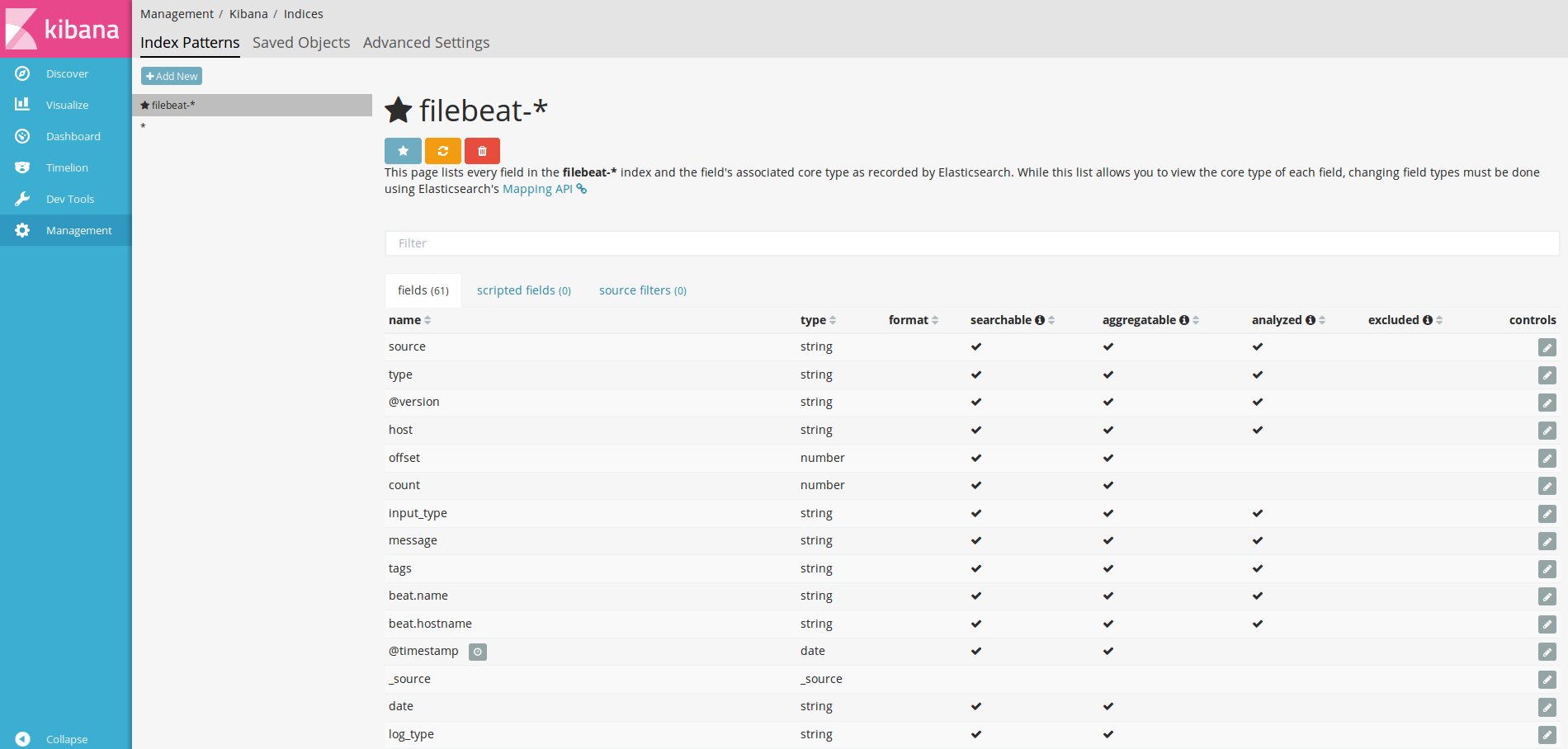
После этого, если агенты подключены нормально, в секции Discover начнут появляться логи.
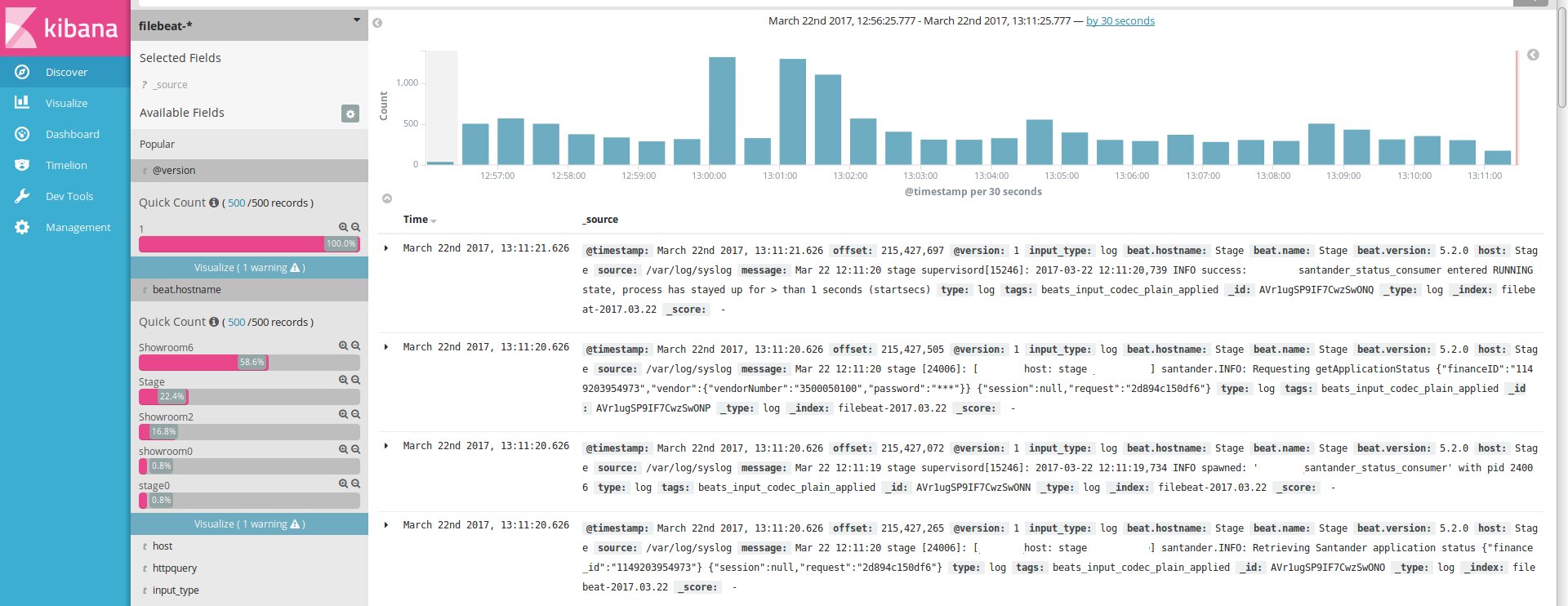
Далее последовательно переходим по вкладкам, настраиваем графики и Dashboard.
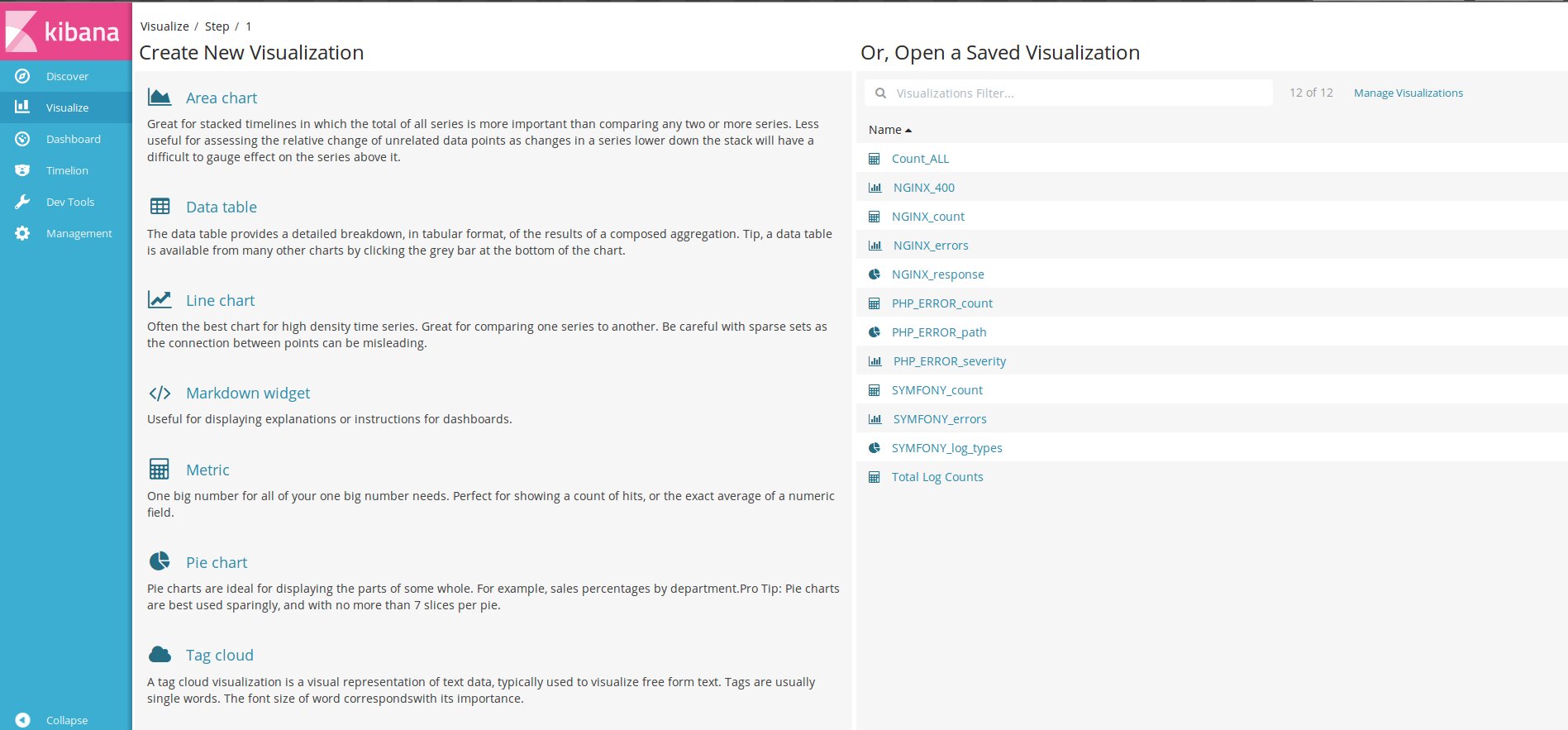
Готовые установки Dashboard можно найти в Сети и импортировать в Kibana.
$ curl -L -O http://download.elastic.co/beats/dashboards/beats-dashboards-1.3.1.zip
$ unzip beats-dashboards-1.3.1.zip
$ cd beats-dashboards-1.3.1/
$ ./load.shПосле импорта переходим в Dashboard, нажимаем Add и выбираем из списка нужный.
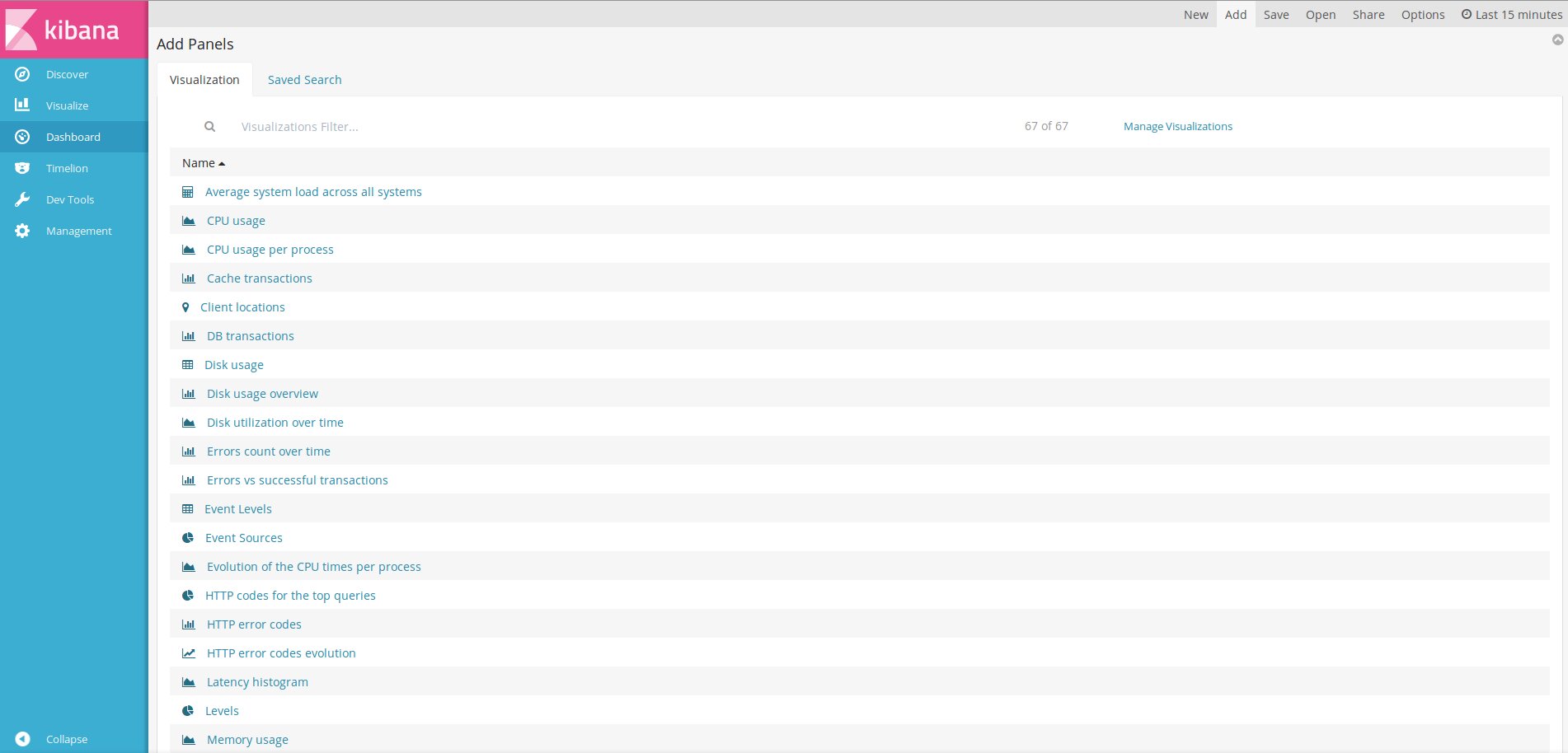
Вывод
Готово! Минимум у нас уже есть. Дальше Kibana легко подстраивается индивидуально под потребности конкретной сети.