Ansible
Задача номер один в любой организации — автоматизация развертывания ПО и приложений, настройка серверов. На сегодня доступно более двадцати систем управления конфигурацией, из них самые известные — Chef, CFEngine, Puppet, но Ansible, появившийся позже всех, в 2012 году, пользуется наибольшей популярностью. Причина — низкий порог входа, максимальная простота работы и безопасность. На удаленных системах для управления не используются агенты, все производится через SSH. Для подключения настраивается беспарольная аутентификация при помощи ключей, также поддерживается LDAP и Kerberos.
Возможно выполнение на удаленных узлах одиночной команды, скрипта или любых операций, выполняемых обычно вручную: проверки состояния, установки, удаления пакетов, создания учетных записей и прав, копирования данных, управления системой, сервисами и многих других. Причем большинство функций реализованы с помощью модулей, упрощающих написание кода, при необходимости можно использовать системные команды напрямую, хотя это рекомендуется только для тех случаев, когда это действительно необходимо. Список модулей есть на сайте проекта.
Кроме Linux, работает и под другими ОС, включая и Win. Поддерживаются Cloud-сервисы — Amazon, Azure, Digital Ocean, сетевое оборудование некоторых производителей. Есть отсылка сообщений и многое другое. Задачи могут выполняться как поочередно на каждом узле, так и синхронно.
В Ansible для работы используется два файла. Один содержит список хостов, разбитых по группам (inventory), второй — список задач, которые нужно выполнить (playbook). Проекты обычно располагаются в отдельных каталогах. В качестве inventory по умолчанию используется /etc/ansible/hosts, хотя его можно указать в строке вызова плейбука, поэтому при работе с несколькими проектами inventory располагают внутри каталога проекта и указывают имя в строке запуска при помощи параметра -i. Группировать узлы можно как удобно, по назначению или расположению.
[Web]
192.168.1.1
192.168.1.2
db.example.com
[Mail]
192.168.1.1
mail.example.comЕсть еще два типа не SSH-подключения: local и docker. Поддерживаются группировка групп и переменные, динамическое создание списка узлов при помощи скрипта. Переменные подключения позволяют указать нестандартный порт, специфическую учетную запись для выполнения команд, ключ для входа и тому подобное:
db.example.com ansible_port=1234 ansible_host=192.0.0.5 ansible_user=userВся магия скрыта в плейбуках. В playbook используется формат сериализации данных YAML, который легко читается. Например, установка nginx при помощи модуля apt в Ubuntu/Debian выглядит так:
- name: Install the nginx packages
apt:
name: nginx
state: present
update_cache: yes
when: ansible_os_family == "Debian"Оператор when позволяет добавлять в правило любые проверки.
Задачу быстрого старта упрощает хаб, предоставляющий готовые пользовательские решения буквально для всех задач. Достаточно лишь выбрать подходящий, скопировать вручную с GitHub или при помощи ansible-galaxy, и база для работы уже есть.
ansible-galaxy install username.rolenameКаждая роль содержит список задач (task), шаблоны и файлы для копирования. Переменные в шаблонах позволяют подставлять разные параметры внутрь при копировании на узлы. Задачи выполняются последовательно, очередная начинает выполняться после успешного завершения текущей. В случае ошибки на каком-то узле он исключается из списка, на остальных выполнение продолжается. Это защищает от частичного выполнения playbook, но если задача связанная (например, развертывание кластера), то отсутствующий узел делает дальнейшее выполнение бесполезным. Например, проверим доступность всех узлов, описанных в файле inventory.ini, при помощи модуля ping:
$ ansible all --inventory-file=inventory.ini --module-name pingСмотрим список узлов и проверяем синтаксис плейбука:
$ ansible-playbook -i inventory.ini playbook.yml --list-hosts
$ ansible-playbook -i inventory.ini playbook.yml --syntax-checkЗапускаем:
$ ansible-playbook -i inventory.ini playbook.ymlAnsible позволяет полностью реализовать идею Infrastructure as Code и отдать обычно сложные операции неспециалисту, которому после конфигурирования нужно будет выполнить одну команду. Хотя тому, кто создает playbook, все-таки нужно понимать процессы: установка одной-двух простых ролей обычно проходит без проблем, но, если ролей уже десяток, нужно запускать их в правильном порядке. Например, если сервис в кластере использует GlusterFS, то логично вначале ставить GlusterFS, а потом сервис. К тому же не всегда best practices применимы к некоторым приложениям. Например, перезагрузку сервиса рекомендуют делать не напрямую командой, а через handlers, который перезапускает его, когда логично. Но, например, при развертывании мастер — мастер кластера MariaDB лучше контролировать этот процесс вручную, поскольку handlers, как назло, перезапускает сервисы именно в тот момент, когда они синхронизируются.
Документация очень подробная и содержит множество примеров.

Prometheus + Grafana
Без системы мониторинга любое приложение — это черный ящик. Очень сложно сказать, что там происходит внутри при увеличении нагрузки. Сами приложения уже давно не монолитны, части взаимодействуют между собой по API, а их работу обеспечивает не только LAMP, но и другие сервисы (Elasticsearch, RabbitMQ...). Метрики позволяют посмотреть работу компонентов в динамике и понять, где узкое место.
Одно из наиболее подходящих решений сбора метрик и мониторинга в современной динамической сети — связка Prometheus и Grafana. В Prometheus используется децентрализованная архитектура, позволяющая легко добавлять сервисы и серверы. На удаленные хосты устанавливаются агенты, которые при помощи заранее подготовленных установок обнаруживают автоматически запущенные на узле приложения, в том числе знают и про виртуализацию. Это все очень упрощает администрирование. Поддерживается оповещение и простые графики для визуального представления собранных данных. В настоящее время доступны агенты для узла (node_exporter), MySQL, Memcached, HAProxy, Consul, Blackbox, SNMP и другие. Также Prometheus может принимать метрики от клиентов сторонних разработчиков. Самый популярный — Telegraf, поддерживающий около 80 плагинов для получения метрик с Apache, nginx, Varnish, СУБД, Docker, Kubernetes, logparser и так далее.
Пакет Prometheus есть в репозиториях основных дистрибутивов, но там далеко не последняя версия, поэтому лучше брать бинарные сборки с сайта проекта. Все источники данных затем прописываются в /etc/prometheus/prometheus.yml, в форме:
scrape_configs:
- job_name: 'node'
static_configs:
- targets: ['localhost:9090']
labels: {'host': 'prometheus'}В job_name прописываются хосты с одинаковыми настройками, labels позволяют отбирать затем метрики по дополнительным параметрам.
После конфигурирования проверяем отсутствие ошибок при помощи утилиты promtool.
$ promtool check-config /etc/prometheus/prometheus.ymlИ запускаем первый раз в консоли, чтобы видеть вывод:
$ prometheus -config.file /etc/prometheus/prometheus.ymlПодключившись браузером на localhost:9090, можем увидеть информацию о работе Prometheus, просмотреть собранные метрики в виде данных или графиков, узнать статус агентов.
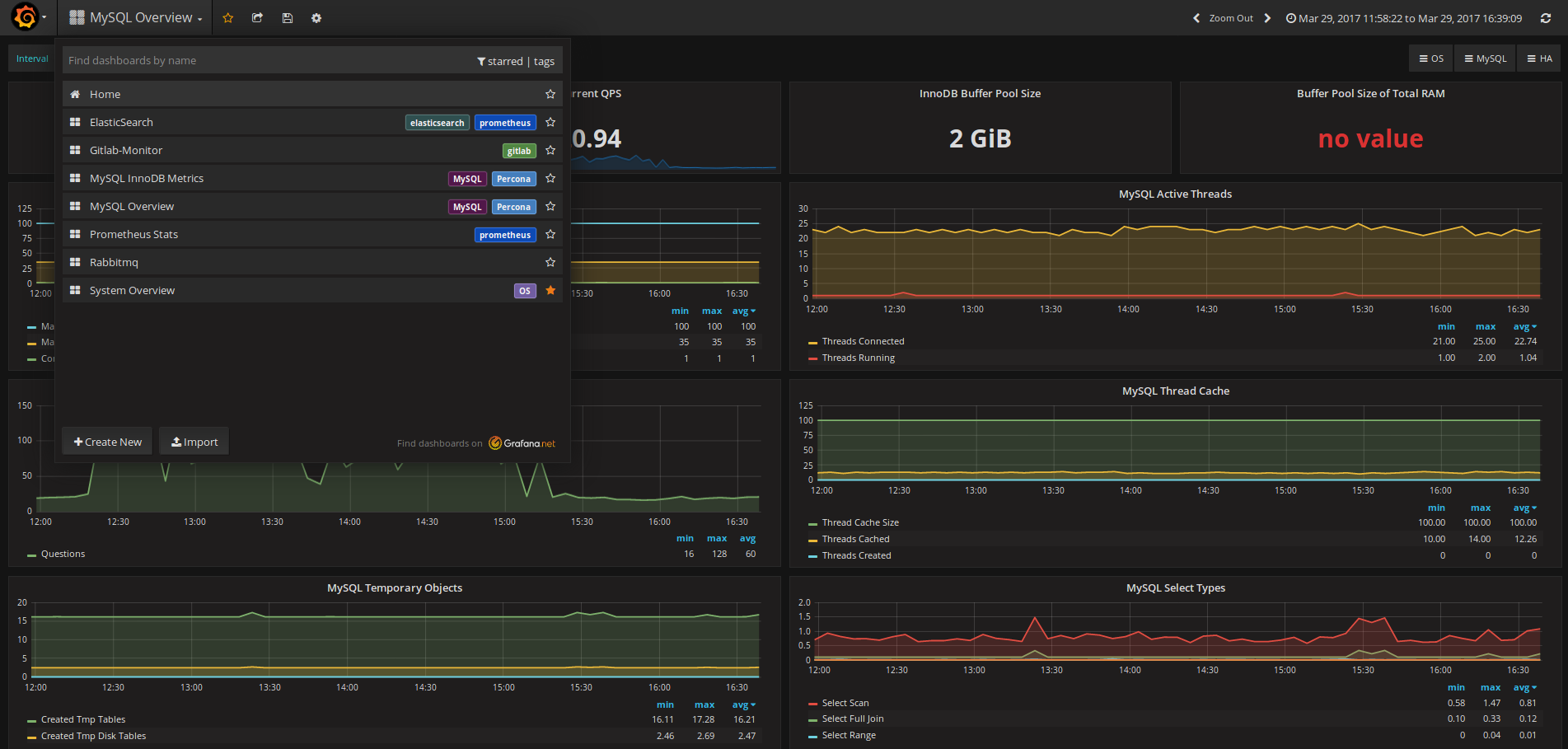
Метрик Prometheus собирает много, а штатный интерфейс по их визуализации сильно ограничен. Здесь на помощь приходит Grafana, умеющий из коробки выводить метрики, предоставляемые Prometheus, Graphite, InfluxDB, Elasticsearch, AWS и, при помощи плагинов, многими другими. После выбора источников (Data Sources) настраиваются дашборды. Поддерживается несколько вариантов графиков, а встроенный язык запросов позволяет получать любые данные. Причем на сайте проекта уже есть готовые dashboard (в формате JSON), которые легко импортируются и при необходимости редактируются. Для выбора правильных метрик можно воспользоваться поиском Metric lookup, расположенным правее строки Query. Но главное — поддерживаются шаблоны (Manage Dashboard → Templating). Так, указав переменную host (например, $host = label_values(host)), можно затем ее использовать в метриках вместо имени узла или IP:
cpu_usage_system{host="$host"}После чего нужный узел надо просто выбрать в дашборде. Доступны алерты с возможностью отсылать сообщения по электронной почте, HipChat, Slack, Telegram и некоторых других. Для этого потребуется установить критическое значение метрики, введя значение вручную или перемещая сердечко справа от графика, и включить метод отправки предупреждений в Alerting → Notification List. Но в текущей версии 4.2 алерты не поддерживают дашборды с шаблонами. Поэтому необходимо под них создавать отдельный dashboard без шаблонов, в котором прописать только те параметры предупреждения, которые мы хотим получать. Обычно для этого просто копируют готовый график, убирая переменные.
Проект предоставляет исходный код и сборки для Linux, Windows, macOS и контейнер Docker. Для Ubuntu есть готовый пакет и репозиторий, поэтому установка сложностей не представляет. По умолчанию для сохранения настроек и данных используется SQLite. При большом количестве узлов имеет смысл использовать MySQL или PostgreSQL.
Concourse CI
Автоматическая сборка проектов (Continuous Integration) после обновления кода экономит кучу времени, поскольку дает возможность сразу увидеть результат — есть ли прогресс и есть ли ошибки. Docker еще больше упростил задачу: протестировать можно сразу в разных средах. Приложений, позволяющих внедрить CI в процесс, сегодня много, но часто они не бесплатны и достаточно сложны, так что требуют привлечения специалиста. Concourse CI позволяет реализовать непрерывную интеграцию в короткие сроки, он прост в развертывании и не требует длительного изучения. Как строить Docker-образы при изменении кода в Git, можно разобраться буквально за пару часов. Также поддерживается интеграция с AWS S3, отправка уведомлений по email и HipChat, выполнение команд и многое другое.
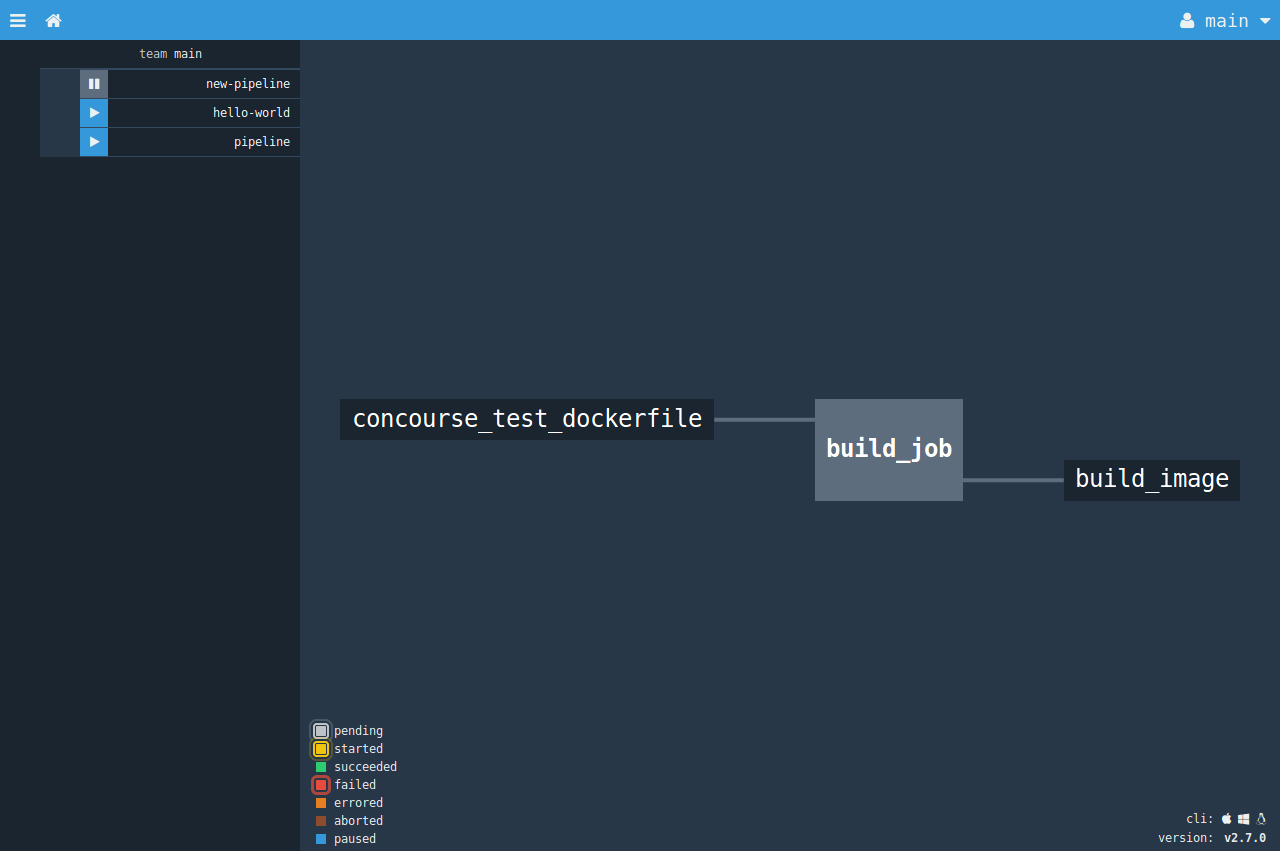
Базируется Concourse CI на трех понятиях: задачи (tasks), ресурсы (resources) и задания (jobs). Задача в общем случае — это любая команда, используемая при сборке контейнера. Ресурс — это любой объект, состояние и версию которого можно отследить. То есть это именно то, что позволяет все запускать автоматически. Изначально подразумевается Git, хотя это может быть и просто таймер. Полный список официальных и неофициальных ресурсов доступен на сайте. Задание описывает действия, которые будут запущены при изменении отслеживаемых ресурсов или вручную. Сами действия описываются в плане сборки — тесты, выполнение команд и сборка контейнера Docker. Для выполнения нужного действия ресурсы и задания между собой связываются при помощи конвейера (pipelines). Данные о pipelines и журналы работы сохраняются в PostgreSQL, поэтому всегда можно сказать, кто что делал.
Параметры можно задавать как непосредственно в командной строке, так и в конфигурационном файле YAML. На сайте есть множество примеров, позволяющих разобраться в процессе. Для управления и ручного запуска заданий используется утилита Fly, просматривать результаты и запускать задания также можно через веб-интерфейс.
Проект предоставляет бинарники для Linux, macOS и Windows, готовые образы Docker и Vagrant.

Функциональное тестирование
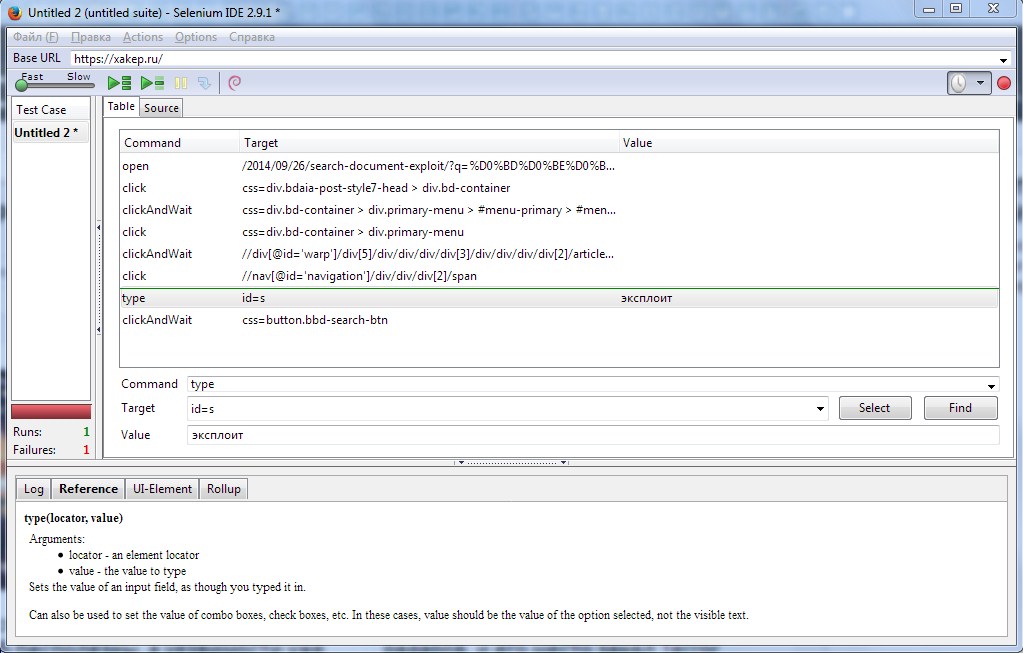
Деплой проекта — это лишь полдела, и без проверки работоспособности приложения он практически бесполезен. Поэтому любой мало-мальски дельный проект включает в себя QA-тестировщика, выполняющего пакет тестов и фиксирующего результат. Если приложение одно, то, наверное, вполне реально на промежуточных сборках провести некоторые базовые действия вручную. Если же результатом должен быть десяток образов для самых разных конфигураций, то без хотя бы простейшей автоматизации здесь не обойтись. Среди решений для тестирования веб-приложений особой популярностью пользуется Selenium, фактически ставший стандартом в этой области. Основой служит библиотека управления браузерами Selenium (ранее Selenium WebDriver), состоящая из клиентских библиотек на разных языках и драйверов браузеров. На сегодня разработаны драйверы для FF, Chrome, IE, Opera, Safari и ряда мобильных устройств. Они находятся на разных этапах разработки и, соответственно, требуют разного внимания. Также проект предоставляет Selenium IDE в виде расширения к FF, которое позволяет записывать, сохранять и воспроизводить сценарии тестирования любых приложений, доступных через браузер. Записанные сценарии сохраняются в формате HTML в виде таблицы, которую можно редактировать. Возможен экспорт в формат, понимаемый другими фреймворками для проведения тестов — NUnit, TestNG, JUnit, хотя, признаться, специалисты редко используют сгенерированные тесты в других средах, а все пишут сами.
Принцип работы прост. После установки Selenium IDE ярлык для запуска находится в меню «Инструменты» (Ctrl + Alt + S). Открываем в браузере сайт и начинаем запись. Затем последовательно выполняем все нужные действия. После записи можем запускать сценарий как вручную, так и по расписанию. Есть возможность устанавливать брейк-пойнты и регулировать скорость выполнения и прочее.
Для небольших проектов этого вполне достаточно, хотя это не вся автоматизация Selenium. Еще один элемент, разрабатываемый проектом, — Selenium Server, который позволяет выполнять в браузере команды, полученные из сценария, запущенного с локальной или удаленной машины. Хотя здесь, конечно, желательно уже познакомиться с фреймворком тестирования Behat, без которого точно не обойтись. Несколько серверов Selenium могут образовывать распределенную сеть (Selenium Grid), позволяющую легко масштабировать стенд автоматизации, запуская параллельно разные тесты на разных удаленных машинах, в итоге время тестирования сокращается. Плюс в этом случае — можно запустить Selenium Server с разными параметрами, а нужный узел будет выбран для теста автоматически. Основные вопросы освещены в документации проекта.
Supervisor
На сервере, особенно используемом при разработке, приходится запускать много всяких программ, установленных не при помощи системного менеджера пакетов, которые должны работать постоянно, перезапускаться в случае ошибки и рестарта сервера. Например, приложения Node.js, Selenium, самописные скрипты. В принципе, можно написать init/systemd-скрипты, но обычно это требует больше времени, и не всегда получается нужный контроль. Выходом из ситуации может быть менеджер процессов Supervisor, предлагающий простой и надежный способ управления работой таких приложений. Демон supervisord запускает процессы как дочерние, а поэтому может отслеживать и при необходимости их автоматически перезапускать. Для мониторинга работы и управления настройками на лету используется консольная утилита supervisorctl и веб-интерфейс (включается при помощи inet_http_server). Нужный пакет уже есть в репозиториях дистрибутивов, поэтому с установкой проблем не возникнет:
$ sudo apt install supervisorКонфигурационные файлы располагаются в /etc/supervisor/conf.d, файл должен иметь расширение conf. Традиционно настройки каждого сервиса производятся в одном файле. Хотя, если нужно запустить несколько копий с разными установками, можно для удобства прописывать в одном. Для примера настроим запуск Selenium через Supervisor.
$ sudo nano /etc/supervisor/conf.d/selenium.conf
[program:selenium]
command=java -Dwebdriver.chrome.driver=/usr/local/bin/chromedriver -jar /opt/selenium/selenium-server-standalone.jar -port %(ENV_SELENIUM_PORT)s
priority=10
user=selenium
directory=/home/selenium
environment=HOME="/home/selenium"
autostart=true
autorestart=trueПараметры очевидны. В program:selenium указывается имя, под которым сервис будет доступен в supervisorctl. В command указывается строка запуска программы со всеми параметрами, user — учетная запись, от имени которой будет выполнена программа. Далее каталог, в котором она будет запущена (он должен быть создан). Параметры autostart и autorestart определяют запуск программы при загрузке ОС и перезапуск в случае остановки. При true программа после остановки будет перезапускаться всегда, даже если она нормально отработает свой цикл. Если перезапуск нужен только в случае сбоя, следует использовать параметр unexpected. В документации можно найти еще много параметров на самые разные ситуации. Перечитываем конфигурацию:
$ sudo supervisorctl rereadЕсли ошибок нет, применяем настройки:
$ sudo supervisorctl updateЕсли нужно отключить какой-то сервис, то лучше это сделать, используя интерактивный режим:
$ sudo supervisorctlПоявится приглашение, все команды можно узнать, введя help:
supervisor> helpПерезапустим selenium
supervisor> restart selenium
supervisor> status selenium
supervisor> quitВывод
Это то, что нужно обязательно знать. Но это только верхушка айсберга: DevOps за восемь лет оброс многочисленными инструментами и технологиями, а требования к специалисту разные. Поэтому учиться придется постоянно.