

Содержание статьи
OpenStack — очень модное слово в современном айтишном медиапространстве. Слышал о нем практически каждый, но в деле видели не очень многие. А попробовать его всерьез отважились вообще единицы. Мы у себя рискнули-таки, и сегодня я расскажу, чем это для нас обернулось и почему мода зачастую бежит впереди рассудительности и стабильности.
Мы уже как-то писали краткий обзор «карманной облачной инфраструктуры» в одном из предыдущих номеров, но было это давно и неправда (подумать только, уже почти три года прошло!). Так что на всякий случай вот краткая выжимка: OpenStack — это открытая (Apache License 2.0) платформа, позволяющая малыми силами организовать на любом количестве железных серверов облачную инфраструктуру а-ля Amazon Web Services. Тут вам и масштабирование виртуалок, и живые миграции, и балансировка нагрузки по нодам, и устойчивость к выходу из строя некоторого процента узлов. В числе основных разработчиков — небезызвестная NASA и Rackspace, Red Hat, Canonical, IBM, AT&T и некоторые другие конторы. В целом затея благая и очень дельная — такой инструмент, в теории, был бы полезен при разработке различных новых систем и сервисов, позволяя на ходу жонглировать инфраструктурой, экспериментировать с архитектурой. Но это все в теории и официальном описании. А что в жизни?

История первая
В жизни все сильно сложнее. OpenStack — это как беременность в шестнадцать. Завести его себе обычно оказывается сильно проще, чем потом с ним адекватно сосуществовать. Через день, неделю, если повезет, то через месяц придет Осознание. К примеру, в один не очень прекрасный момент по какой-то причине виртуалки просто перестанут создаваться. Все хорошо, все есть — и место на дисках, и свободные вычислительные мощности, и IP-адреса в сети. Но нет. Висит себе в состоянии Creating Instance, и все. Полчаса, час, два, пять. Ничего не происходит. В логах тишина. Еще несколько часов, проведенных в гугле, наудачу перезагружаем «кролика», и оп — все внезапно заработало. Виртуалки создаются, поднимаются, все снова хорошо. Вопрос «И что это было?» повисает в воздухе.
История вторая
Еще через месяц, к примеру, Hetzner, в котором стоят серверы с твоим OpenStack’ом, вдруг решает провести техработы по части электропитания. И оказывается, что Compute-нода как раз под эти техработы попадает. Ты заблаговременно останавливаешь на ней все сервисы, сам руками выключаешь сервер. Ждешь положенные пару часов, нода после технических работ поднимается. Вот только ничего не работает. Ни одна виртуалка не доступна. Заходишь в панель — на первый взгляд, все выглядит прилично и как должно. Опять непонятно. Идешь руками на сервер по SSH, virsh list. Виртуалки на месте, поднялись, virsh -c qemu+ssh://username@host/system — оп! No route to host. Как так? ifconfig && iptables-save, сетевых интерфейсов нет. Логи, гугл, логи, гугл, логи, логи, гугл. С мертвой точки дело не сдвигается. По старой виндузявой привычке наудачу решаешь перезагрузить сервер еще раз. Так, на всякий случай. Сервер выходит из ребута, все поднимается и работает. Стараясь не делать резких движений, выходишь из панели стака и с сервера и решаешь по возможности больше никогда к нему не подходить.
Злоключение
Как уже успели на себе прочувствовать те немногие, кто решился использовать OpenStack в относительном продакшене, он еще «не готов для десктопа». Пока, к сожалению, он не дает удовольствия ограничить общение с собой исключительно нажиманием кнопочек в веб-интерфейсе для создания новых виртуалок и распределением доступов к ним. Шаг вправо, шаг влево — и можно наткнуться на что-то такое, про что еще даже в гугле не написали. И на отладку может уйти не только не один день, но даже не одна неделя. Ребята в одной из самых известных компаний — поставщиков готовых решений на базе OpenStack сравнивают этот процесс с постройкой дома:
«При упоминании OpenStack хороша аналогия с домом. OpenStack опирается на множество сложных открытых проектов, слепленных друг с другом через различные API, которые зачастую ставят в тупик даже самых прожженных инженеров. С точки зрения бизнеса попытка самостоятельно во всем этом разобраться может пагубно сказаться на сроках сдачи проекта и достижении поставленных целей. Подход „сделай сам“ пока еще очень популярен в среде OpenStack-новичков и часто не приводит их к сколько-нибудь удовлетворительному результату, отчего мнение о всей системе остается не очень лестное.
Главной целью поставщика готовых решений в данном случае является помощь в проектировании и развертывании надежной площадки для проектов клиента. И ключевой момент в данном вопросе — правильный выбор опытного поставщика, который сможет собрать все необходимые части системы, корректно их связать и в дальнейшем поддерживать то, что получилось. Пожалуйста, доверьте поддержку OpenStack проверенному поставщику».
В чем-то с ними даже можно согласиться. Далеко не каждый может позволить себе тратить такое количество админо-часов на даже банальное поддержание текущей работоспособности системы, не говоря уже о каком-то дальнейшем развитии.
О новинках
Но если капризы работоспособности OpenStack’а — это уже в некоторой степени стабильный вопрос, немало обшученный, то новинкам проекта, думаю, стоит уделить внимание.
Heat
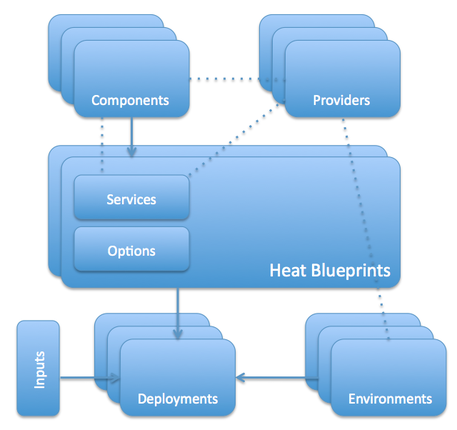
Heat — это основной инструмент оркестровки, используемый в мире OpenStack. Он позволяет запускать готовые облачные архитектуры из темплейтов, описанных текстом, своего рода подобием программного кода. Формат темплейтов у Heat свой собственный, но помимо него поддерживается совместимость с форматом AWS CloudFormation. Таким образом, многие уже готовые темплейты CloudFormation вполне можно будет запускать и под OpenStack’ом. У Heat есть возможность общаться с внешним миром как через родной ReST API OpenStack’а, так и через совместимый API запросов CloudFormation’а.

Хакер #191. Анализ безопасности паркоматов
Как это вообще работает?
- Темплейты облачной инфраструктуры — это обычные умеренно человеко-понятные plain-text документы, их можно хранить в системах контроля версий, удобно сравнивать, делать патчи и прочее.
- Список элементов инфраструктуры, доступных для описания в темплейтах: серверы, IP-адреса, тома, группы безопасности, пользователи, ключи и так далее.
- Heat предоставляет возможность организации автоматического масштабирования под нагрузкой при интеграции с Ceilometer (о нем чуть дальше).
- Естественно, в темплейтах также описываются не только отдельные ресурсы, но и их взаимоотношения — привязка томов и адресов к конкретным серверам, определение конкретных серверов в конкретные группы безопасности, распределение доступов к серверам между пользователями и многое другое. Это позволяет максимально полно автоматизировать разворачивание необходимой инфраструктуры через API OpenStack’а, избегая дополнительного ручного вмешательства.
- Heat контролирует и изменения в инфраструктуре. Когда тебе надо что-то поменять, просто вносишь нужные правки в соответствующий темплейт и обновляешь конфигурацию Heat, и он уже там сам разбирается и приводит все к эталону.

Ничего знакомого в этом всем не заметил? Правильно, схожие идеи мы уже видели в таких проектах, как Chef и Puppet. Использовать или нет — это уже на твой вкус. Говорят, у Heat’а даже есть какое-то подобие интеграции с ними, но мы пока не пробовали, так что детальнее рассказать, к сожалению, не смогу.
Ceilometer
Ceilometer — это инструмент для сбора различных статистических данных в облаке OpenStack. Основной целью проекта является мониторинг нагрузки и измерения потребления ресурсов клиентами, но возможности фреймворка могут быть расширены и для других нужд. Доступ к метрикам можно получать через отдельно реализованный REST API.
Архитектура Ceilometer
Центральный агент (Central Agent) опрашивает данные по утилизации ресурсов, которые не связаны с виртуальными машинами или вычислительными узлами (Compute Nodes). В каждой системе Ceilometer может быть запущен только один центральный агент.
Вычислительный агент (Compute Agent) собирает данные измерений и статистику с вычислительных узлов (в основном гипервизора). Вычислительный агент должен быть запущен на каждом вычислительном узле, состояние которого необходимо отслеживать.
Коллектор (Collector) отслеживает очереди сообщений (на предмет уведомлений, которые присылает инфраструктура, и на предмет результатов измерений от агентов). Уведомления обрабатываются, преобразовываются в измерительные данные, затем подписываются и возвращаются на шину передачи сообщений в соответствующую тему. Коллектор может работать на одном или нескольких серверах управления.
Хранилище данных (Data Store) — это база данных, которая может обрабатывать одновременные запись (с одного или нескольких коллекторов) и чтение данных (с API-сервера). Коллектор, центральный агент и API могут работать на любом узле.
Эти службы сообщаются с помощью стандартной шины передачи сообщений OpenStack. Только коллектор и API-сервер имеют доступ к хранилищу данных. Поддерживаются SQL базы данных, совместимые с SQLAlchemy, а также MongoDB и HBase. Однако разработчики Ceilometer рекомендуют именно MongoDB, в связи с более эффективной обработкой одновременных операций чтения/записи данных. Кроме того, только конфигурация Ceilometer с MongoDB прошла тщательное тестирование и развертывание в коммерческих средах. Для базы данных Ceilometer рекомендуется использовать выделенный узел, так как инфраструктура может создавать изрядную нагрузку на БД. Согласно оценкам разработчиков, измерение инфраструктуры на коммерческом уровне предполагает до 386 записей в секунду и 33 360 480 событий в день, что потребует до 239 Гб для хранения статистики за месяц.

В проекте Ceilometer реализованы три типа измерений:
- Cumulative (кумулятивные): их еще можно назвать инкрементальными — значения, которые все время растут (к примеру, аптайм виртуальной машины);
- Gauge (индикатор): отдельные события и значения (например, IP-адреса, привязанные к тому или иному серверу, или данные по вводу-выводу дисковой подсистемы);
- Delta (дельта): изменение со временем (например, пропускная способность сети).
Каждый измеритель собирает данные с одного или нескольких образцов (собираемых из очереди сообщений или агентами), которые представлены счетчиками. Каждый счетчик имеет следующие поля:
- counter_name. Строка названия счетчика. По общепринятому соглашению точка используется как разделитель при переходе от наименее конкретного слова к наиболее конкретному (например, disk.ephemeral.size);
- counter_type. Тип счетчика (кумулятивный, индикатор, дельта, см. выше);
- counter_volume. Объем измеряемых данных (такты ЦП, число байтов, переданных по сети, время развертывания виртуальной машины и так далее). Это поле несущественно для счетчиков типа индикатор; в этом случае ему должно быть присвоено значение по умолчанию (обычно 1);
- counter_unit. Описание единицы измерения счетчика. Для обозначения используются единицы измерения системы СИ и их утвержденные сокращения. Количество информации должно выражаться в битах (б) или байтах (Б). Когда измерение представляет собой не количество данных, описание всегда должно содержать точную информацию, что измеряется (виртуальные машины, дисковые тома, IP-адреса и так далее);
- resource_id. Идентификатор измеряемого ресурса (UUID виртуальной машины, сеть, образ);
- project_id. Идентификатор проекта, которому принадлежит ресурс;
- user_id. Идентификатор пользователя, которому принадлежит ресурс;
- resource_metadata. Некоторые дополнительные метаданные для информационного наполнения сообщения об измерении.
Полный список доступных на данный момент измерений можно найти в документации Ceilometer (https://wiki.openstack.org/wiki/Ceilometer).
Ceilometer — это довольно перспективный проект, ставящий своей целью унификацию возможностей по сбору информации обо всех аспектах жизни облачной инфраструктуры. Использование Ceilometer позволяет поставить «карманное облако» на достаточно крепкие коммерческие рельсы.
Зе енд
Как видно, не все так просто в Датском королевстве. Есть там место и бедам и приключениям. OpenStack развивается очень активно, но все еще не готов к быстрому и простому использованию в производстве, как некоторые продукты коммерческой виртуализации прошлого поколения.
Если виртуализация — это одно из основных направлений твоей деятельности, то, без сомнения, уже пора начинать в нем разбираться. Если нет, но все равно интересно, то, пожалуйста, пробуй, но в производство без крайней нужды пускать не советую. На данный момент лучше будет пользоваться классическими системами виртуализации всем, у кого нет особых против того противопоказаний. Сбережете много нервов и денег. Мы же у себя подумываем в некотором не очень отдаленном будущем тоже открывать направление поддержки OpenStack-решений. Кажется, это будет довольно интересно :).












