


Содержание статьи
Вот уже десять лет специалисты холдинга DZ Systems занимаются разработкой ПО и созданием информационных систем на самом высоком уровне — за это время их клиентами успели стать такие киты российского бизнеса и мегапроекты государства Российского, как Юлмарт, Яндекс, Мосводоканал, Олимпиада-2014, Mail.Ru Group, Wikimart, Raiffeisen Bank, KFC и BMW.
Офисы группы компаний расположены в пяти городах России: Москве, Санкт-Петербурге, Казани, Ульяновске и Саранске. Поскольку по странному стечению обстоятельств там же обитают наиболее активные читатели нашего журнала :), думаю, тебе будет интересно посмотреть на задачи, которые в DZ Systems ставят перед кандидатами на трудоустройство. Тем более что нигде, кроме нашего журнала, ты их не найдешь.
Как проходит собеседование в DZ Systems
Мы нанимаем человека, основная обязанность которого — писать код. Конечно, надо видеть, как он это делает. Мы предлагаем соискателю показать любой готовый проект или выполненное тестовое задание для какой-нибудь организации (с постановкой задачи от заказчика). Если ему показать нечего, то просим выполнить тестовое задание, которое отправляем по имейлу. Когда программист присылает ответ, ведущие разработчики DZ смотрят на код, на правильность выполнения, аккуратность и, как говорится, на красоту архитектуры. Если выполнение нравится, то приглашаем соискателя на собеседование с HR-специалистами. Они смотрят, насколько человек подойдет к нашей сложившейся команде. Мы выбираем людей не только по знаниям, но и по человеческим качествам, для нас очень важны сохранение хорошего климата, комфортная работа с коллегами. На собеседовании стараемся определить, насколько этот человек «наш». Если у него нет всех необходимых навыков, но видно, что он может научиться, есть потенциал, то рады будем с ним сотрудничать.
Программист, который хорошо написал тестовое задание, после беседы с HR-специалистом проходит техническое собеседование с ведущими разработчиками. Наши офисы находятся в разных городах, поэтому второе собеседование может проводиться по скайпу. Например, мобильные разработчики у нас в Санкт-Петербурге и Казани, а Java-разработчики — в Казани и Ульяновске.
В DZ Systems есть типовые наборы задач и вопросов для технического собеседования, рассчитанного на один час. Такие задачи мы и предлагаем для решения читателям «Хакера». Победители получат возможность бесплатно пройти новый игровой квест от наших друзей из компании «Клаустрофобия» — ограбление банка. В этом квесте ты получишь возможность на час попасть в банковское хранилище и, еще раз проявив логические способности, вынести оттуда ценную реликвию.
Задача 1
При использовании очевидного представления данных для сохранения даты требуется 8 байт (ДДММГГГГ), а имя человека занимает примерно 25 байт (14 на фамилию, 10 на имя и 1 на первую букву отчества). Насколько вы сможете уменьшить эти числа, если перед вами стоит задача экономии памяти?
Задача 2
Написать (на любом языке программирования) функцию вывода n-го числа последовательности Фибоначчи.
![]()
Задача 3
В массиве натуральных чисел [1..1001], содержащем все числа от 1 до 1000 включительно, есть элемент, повторяющийся дважды. Найти его. К каждому элементу можно обращаться только один раз. Язык программирования — любой.
Задача 4
Заданы два числа a, b. Поменять их значения местами без использования промежуточной переменной (то есть использовать можно только a, b и арифметические операции).
Задача 5
Что такое полиморфизм? Приведите примеры.
Задача 6
Четыре человека должны перейти через пропасть по мосту. Одновременно на мосту могут находиться не больше двух человек, держась за руки, и только с фонарем. Одному из пары надо возвращаться назад, чтобы вернуть фонарик. Один из них переходит мост за одну минуту, второй за две, третий за пять, четвертый за десять минут. Необходимо всем перебраться через мост за 17 мин.
Перекидывать фонарик, идти навстречу, переплывать, останавливаться — нельзя. Задача решаема.
Задача 7
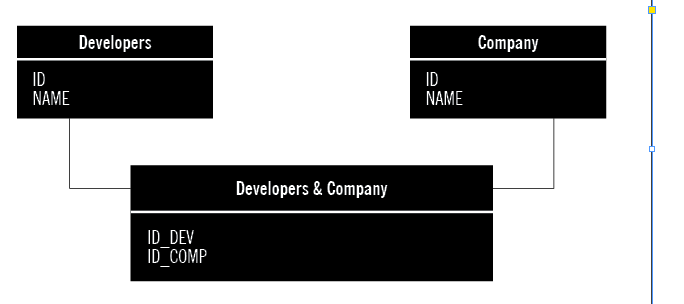
Дана реляционная база данных, которая состоит из трех таблиц (см. картинку).
Написать на SQL программу, которая выведет все компании, где не работает Developer c ID = 3.
Решение задач из школы программистов HeadHunter
Задача 1. Количество разбиений на k слагаемых
Задача является стандартным примером задачи на динамическое программирование. Обозначим интересующее нас количество разбиений через F(n, k). Часть из разбиений содержит единицу в качестве слагаемого. Все такие разбиения можно получить из разбиений числа n – 1 на k – 1 слагаемое добавлением единицы в качестве k-го слагаемого. Те разбиения, которые единицу не содержат, получаются из разбиения числа n – k на k слагаемых прибавлением единицы к каждому из k слагаемых. Таким образом, получается рекуррентная формула: F(n, k) = F(n – 1, k – 1) + F(n – k, k). Объединяя ее с граничными условиями F(n, k) = 1 при n = k либо k = 1 и F(n, k) = 0 при n < k, получаем решение задачи. Пример кода на Java:
public class PartitionNumberCounter {
private int[][] table;
private PartitionNumberCounter(int number, int itemsCount) {
this.table = new int[number][itemsCount];
}
private int countPartitions(int number, int itemsCount) {
if (number == itemsCount || itemsCount == 1) {
return 1;
} else if (itemsCount > number) {
return 0;
}
if (table[number - 1][itemsCount - 1] == 0) {
table[number - 1][itemsCount - 1] = countPartitions(number - 1, itemsCount - 1) + countPartitions(number - itemsCount, itemsCount);
}
return table[number - 1][itemsCount - 1];
}
public static int countNumberOfPartitions(int number, int itemsCount) {
return new PartitionNumberCounter(number, itemsCount).countPartitions(number, itemsCount);
}
}Задача 2. Медиана
В теории вероятностей и математической статистике медианой называется число, которое делит вариационный ряд выборки на две равные части. Для нахождения медианы конечного массива чисел необходимо отсортировать массив от меньших значений к большим и выбрать значение посередине массива.
Для получения медианы массива A = [2, 1, 5, 0, 10] отсортируем массив, получим A_sorted = [0, 1, 2, 5, 10]. Медианой массива является третий элемент массива, то есть 2.
Для нахождения медианы массива с четным числом элементов существуют различные соглашения. Для решения задачи примем следующее соглашение: медианой массива A с четным числом элементов 2N является (A_sorted[N] + A_sorted[N + 1]) / 2.
Самым популярным и при этом самым неоптимальным способом решения этой задачи является конкатенация массивов, сортировка результирующего массива и получение среднего от n и n + 1 элементов. Такой способ решения имеет алгоритмическую сложность O(n log n). Второй по популярности метод решения этой задачи — использование сортировки слиянием (merge sort), в этом случае мы получаем алгоритмическую сложность O(n). Рассмотрим способ решения, использующий парадигму «разделяй и властвуй», сложностью O(log n).
Решение:
Главная идея состоит в том, что для данных массивов a1 и a2 можно проверить, является ли a1[i] медианой за константное время. Предположим, что a1[i] — медиана. Так как массив отсортирован, a1[i] больше i предыдущих значений в массиве a1. Если он является медианой, он также больше, чем j = n – i – 1 элементов массива a2.
Необходимо константное время для проверки, что a2[j] <= a1[i] <= a2[j + 1]. Если a1[i] не является медианой, в зависимости от того, a1[i] больше или меньше, чем a2[j] и a2[j + 1], мы знаем, что a1[i] больше или меньше медианы. Исходя из этого, мы можем найти медиану бинарным поиском за O(log n) в худшем случае.
Для двух массивов a1 и a2 сначала пройдем бинарным поиском по a1. Если мы достигнем конца (левого или правого) первого массива и не найдем медиану, начнем искать ее во втором массиве a2.
Алгоритм
- Получим средний элемент a1. Положим индекс среднего элемента i.
- Посчитаем индекс j массива a2: j = n – i – 1.
- Если a1[i] >= a2[j] и a1[i] <= a2[j + 1], то a1[i] и a2[j] — средние элементы. Искомая медиана (a1[i] + a2[j]) / 2.
- Если a1[i] больше, чем a2[j] и a2[j + 1], то ищем в левой части массива.
- Если a1[i] меньше, чем a2[j] и a2[j + 1], то ищем в правой части массива.
- Если мы достигли конца списка a1, то осуществляем бинарный поиск в массиве a2.
Пример
a1 = [1, 5, 7, 10, 13]
a2 = [11, 15, 23, 30, 45]Средний элемент a1 — 7. Сравним 7 с 23 и 30, исходя из того, что 7 меньше, чем 23 и 30, сдвинемся вправо по a1. Продолжая бинарный поиск в [10, 13], на этом шаге возьмем 10. Сравним 10 с 15 и 23. Так как 10 меньше 15 и 23, снова сдвинемся вправо. 13 больше, чем 11, и меньше, чем 15, заканчиваем работу. Искомая медиана — 12 (среднее от 11 и 13).
Имплементация
def get_median(a1, a2, left, right, n):
if left > right:
return get_median(a2, a1, 0, n-1, n)
i = (left + right) / 2
j = n - i - 1
if a1[i] > a2[j] and (j == n - 1 or a1[i] <= a2[j+1]):
if i == 0 or a2[j] > a1[i-1]:
return (a1[i] + a2[j])/2
else:
return (a1[i] + a1[i-1])/2
elif a1[i] > a2[j] and j != n-1 and a1[i] > a2[j+1]:
return get_median(a1, a2, left, i - 1, n)
else:
return get_median(a1, a2, i + 1, right, n)
if __name__ == "__main__":
a1 = [1.0, 10.0, 17.0, 26.0]
a2 = [2.0, 13.0, 15.0, 30.0]
n = len(a1)
print get_median(a1, a2, 0, n - 1, n)Задача 3. Пересекающиеся прямоугольники
Одно из возможных решений этой задачи — алгоритм sweep line. Отсортировав левые и правые x-координаты прямоугольников, мы получаем массив, каждый элемент в котором можно представить как событие добавления прямоугольника в рассматриваемый в данный момент набор либо удаления прямоугольника. Так как между событиями высота пересечения прямоугольников из набора не меняется, на каждом шаге мы вычисляем часть искомой площади.
Оставшаяся задача — посчитать длину пересечения множества отрезков. Для этого, итерируясь по отсортированному по левой координате массиву, объединяем отрезки до тех пор, пока начало следующего отрезка не будет больше конца предыдущего — это значит, что можно посчитать длину найденного объединения и начать искать следующее.
Имплементация
def compute_length(segments):
length, left, right = 0, 0, 0
segments.sort(key=lambda v: v[0])
for l, r in segments:
if l > right:
length += right - left
left, right = l, r
elif r > right:
right = r
return length + (right - left)
def compute_area(rectangles):
queue = []
area = 0
for x1, y1, x2, y2 in rectangles:
queue.append((x1, True, (y1, y2)))
queue.append((x2, False, (y1, y2)))
queue.sort(key=lambda v: v[0])
segments = []
last = queue[0][0]
for x, status, size in queue:
area += (x - last) * compute_length(segments)
last = x
if status:
segments.append(size)
else:
segments.remove(size)
return areaСтруктура DZ Systems
Digital Zone специализируется на создании масштабируемых web-систем, рассчитанных на проекты федерального масштаба. Компания на 14-м месте в рейтинге ведущих веб-разработчиков страны за 2014 год. E-Legion — разработчик мобильных приложений, в 2014 году компания вышла на первое место в рейтинге Рунета по мобильной разработке.
IT-компании, шлите нам свои задачки!
Миссия этой мини-рубрики — образовательная, поэтому мы бесплатно публикуем качественные задачки, которые различные компании предлагают соискателям. Вы шлете задачки на lozovsky@glc.ru — мы их публикуем. Никаких актов, договоров, экспертиз и отчетностей. Читателям — задачки, решателям — подарки, вам — респект от нашей многосоттысячной аудитории, пиарщикам — строчки отчетности по публикациям в топовом компьютерном журнале.
Читатели, шлите ваши ответы!
Правильные ответы принимает Анна Новомлинская (anna.novomlinskaya@dz.ru). Она же распределяет призы — билеты на офлайн-квест. Не теряйся!












