

Содержание статьи
Приложение или браузер
Мобильные приложения становятся логичным развитием интернет-сайтов. В целом они эффективней используют ресурсы устройства, да и возможностей по работе с данными тут больше. Часто веб-разработчики сталкиваются с естественными ограничениями мобильных устройств — отсутствием флеша, тормозами страницы из-за перегруженности и другими. И никто не будет спорить, что работать с картами или почтой удобней в нативных программах, а не в браузере.
Использование базы данных поможет сохранить все необходимые пользователю данные, и это очень круто. Все возможности приложения будут доступны, даже если пользователь уедет в тайгу, где интернета никогда и не было. Когда-то давно, целых полтора года назад, наш журнал уже делал обзор способов сохранения данных в Android, но база данных заслуживает отдельной статьи.
Кешируем всё
В Android из коробки база данных присутствует в виде библиотеки SQLite, которую даже не нужно как-то подключать или запрашивать на нее разрешение у пользователя. Чтобы понять, насколько она полезна, напишем полноценное приложение, которое будет загружать данные из интернета и кешировать их, а затем выдавать их в любых условиях: в дождь, мороз и дисконнект.
SQLite — легковесный фреймворк, который, с одной стороны, дает по максимуму использовать возможности SQL, с другой — бережно относится к ресурсам устройства. Его недостатки малокритичны для мобильной разработки: к примеру, нет индексов для LIKE-запросов и есть лимиты на размер базы данных.
Сериализация и JSON
Самое время поговорить о контенте: в принципе, нам абсолютно неважно, что кешировать. Тем не менее хранить в БД все подряд не стоит: если это будут какие-то разовые записи или отметки о состоянии Activity, лучше использовать SharedPreferences. Как и во «взрослых» системах, база данных предназначена для сохранения большого объема структурированной информации: каталога товаров, списка задач, новостных блоков и так далее.
Грамотные люди передаваемые по сети данные сначала сериализуют — то есть конвертируют в некую последовательность байтов. Существует несколько способов сериализации, каждый из которых хорош по-своему. Несколько лет назад был популярен формат XML, но в условиях больших объемов конвертеры XML довольно сильно грузят процессор, что критично для мобильных устройств.
На смену XML пришел формат JSON, который, пожалуй, уже стал стандартом. Он не только прост в парсинге, но и удобен для веб-разработчиков: например, он легко разбирается с помощью JavaScript. Формат JSON довольно прост и легко читается как приложениями, так и просто глазами. Для примера я взял список пользователей с несколькими параметрами — имя, описание, собственный идентификатор и картинка-аватар.


{
"name":"John",
"description":"desc #1",
"id":3137,
"image":"link_to_image.url"
}Такой массив данных довольно легко раскладывается в Java-объект. Создать класс с нужным содержанием можно руками или воспользоваться конвертерами, которые ищутся по запросу json to java. Такой конвертер самостоятельно разберет поля и добавит аннотации с указанием полей.
@SerializedName("id")
@Expose
public Integer id;
@SerializedName("name")
@Expose
public String name;
@SerializedName("description")
@Expose
public String description;
@SerializedName("image")
@Expose
public String urlImage;
...Загрузив JSON в приложение, его нужно будет разложить по полям в подготовленный Java-объект. Для этого тоже есть готовые решения. Мне нравятся библиотека Retrofit и конвертер Gson Converter, о которых мы не раз писали. Если нет каких-то экзотических требований к сетевым запросам — Retrofit тебе однозначно подойдет.
CRUD и DAO
Принцип построения таблиц и связей между ними ничем не отличается от классического SQL. Под созданный JSON я решил выделить две таблицы: в одной будет вся текстовая информация, а в другой набор изображений. Выделять изображения в отдельную таблицу есть смысл для экономии памяти — несколько пользователей могут иметь одинаковые аватарки, тогда их не придется дублировать.
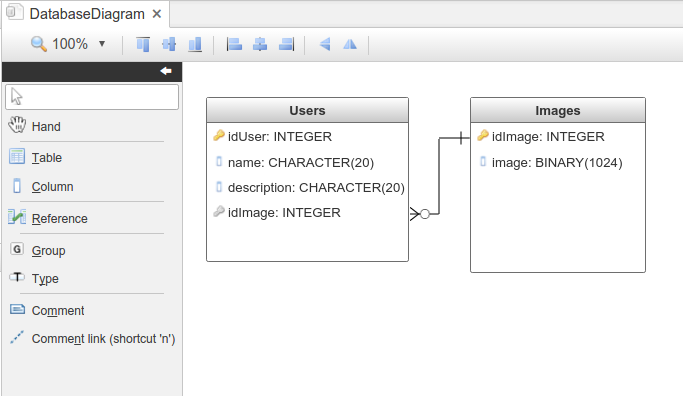
При работе с БД удобно пользоваться несколькими паттернами, которые помогают не изобретать велосипеды и при этом реализовать всё, что нужно. Базовый набор запросов содержится в акрониме CRUD — create, read, update и delete. А еще в ООП есть свои шаблоны кода, которые тоже придуманы не зря. Все CRUD-запросы рекомендуется реализовать через паттерн DAO — data access object. Он подразумевает под собой создание интерфейса, в котором будут обозначены необходимые методы.
public interface DAO {
void insertPerson(ContactJson json);
ContactJson selectPerson(int id);
void updatePerson(ContactJson json, int id);
void deletePerson(int id);
}Конечно, сейчас в нашей программе этот интерфейс выглядит излишним, но в будущем может выручить: абстрактные классы и интерфейсы помогают не забыть, какая именно функциональность требуется в проекте.
SQLiteOpenHelper
Язык SQL-запросов ближе к процедурному программированию, чем к ООП, поэтому для работы с БД в Android создан отдельный класс SQLiteOpenHelper. Он позволяет общаться с базой данных на привычном для Java-разработчика языке методов и классов. Как обычно, создаем свой объект, дополняя его необходимыми данными — названием и версией БД.
public class DummySQLite extends SQLiteOpenHelper {
public DummySQLite(Context context, ...) {
super(context, DATABASE_NAME, null, DATABASE_VERSION);
}При генерации SQL-запросов нужно будет постоянно указывать названия таблиц и полей. Чтобы свести к минимуму вероятность опечаток, удобно использовать строковые константы, превратив названия полей в переменные.
private static final int DATABASE_VERSION=1;
private static final String DATABASE_NAME="DummyDB";
private static final String TABLE_USERS="users";
private static final String USER_ID="idUser";
private static final String USER_NAME="name";
...И хотя принципы работы с БД максимально приближены к логике ООП-разработки, от синтаксиса SQL никуда не денешься. Если у тебя есть пробелы в знаниях — почитай какой-нибудь мануал для начинающих. В большинстве случаев базовых знаний будет достаточно.
Класс SQLiteOpenHelper требует обязательного переопределения методов, используемых при инициализации, — методов создания, открытия и обновления базы данных. В onCreate необходимо задать команды для создания таблиц внутри базы данных, он будет вызван системой самостоятельно при первоначальной инициализации базы данных.
@Override
public void onCreate(SQLiteDatabase sqLiteDatabase) {
String CREATE_USERS_TABLE = "CREATE TABLE " + TABLE_USERS + " (" +
USER_ID + " INTEGER PRIMARY KEY," + USER_NAME + " TEXT," +
USER_DESCR + " TEXT, " + sqLiteDatabase.execSQL(CREATE_USERS_TABLE);
...
}Поскольку структура базы может меняться, нужно реализовать метод onUpgrade, который будет стирать созданное ранее.
@Override
public void onUpgrade(SQLiteDatabase sqLiteDatabase, int i, int i1) {
sqLiteDatabase.execSQL("DROP TABLE IF EXISTS " + TABLE_IMAGES);
...
}Построение запросов
Как ты уже обратил внимание, все запросы строились через явный SQL-синтаксис, обрабатываемый методом execSQL. Он позволяет выполнить любую SQL-команду, кроме тех, что возвращают какие-либо значения. Но на практике этот метод используется только для базовой инициализации БД, для остальных случаев есть вызовы удобнее. Самый популярный способ получить данные — воспользоваться методом rawQuery. Он позволяет напрямую обратиться к базе данных, забив в аргумент классический SQL-запрос.
Сursor cursor=db.rawQuery("Select *" + " FROM "+ TABLE_USERS + " WHERE " + USER_ID + " = "+number, null);На выходе будет выборка в формате Cursor, который создан специально для работы с базой данных. Это своеобразный массив, данные из которого можно читать разными способами, мне нравится вариант с организацией цикла.
while (cursor.moveToNext()) {
result.setId(cursor.getInt(0));
result.setName(cursor.getString(1));
result.setDescription(cursor.getString(2));
}Официальная документация рекомендует не забывать освобождать ресурсы после прочтения всех необходимых данных, иначе будет утекать память. С другой стороны, если данные могут потребоваться еще раз, есть смысл Cursor не трогать — легче прочитать данные из памяти, чем сделать запрос в базу данных.
cursor.close();Как видишь, получить данные из базы несложно, но сначала их нужно как-то туда занести. Для добавления в базу данных существует специальный метод. Он работает как SQL-вызов UPDATE, который ничего не проверяет, а просто заносит в таблицу новые данные.
db.insert(TABLE_USERS, null,getUsersData(contactJson));Перед добавлением данные нужно подготовить — указать, в какие именно поля вставлять значения. Это будет связка «имя поля — значение», доступная в виде класса ContentValues.
ContentValues values = new ContentValues();
values.put(USER_ID, json.getId());
values.put(USER_NAME, json.getName());
...Тебе не нужно указывать значения полей при вызове метода, что, несомненно, упрощает построение запроса.
Вставка изображений
Файлы в Android можно хранить по-разному, если они не слишком большие, то даже внутри SQLite. Тип поля Blob позволяет внести в него массив байтов, для этого воспользуемся классом ByteArrayOutputStream как промежуточным звеном.
ByteArrayOutputStream bmpStream = new ByteArrayOutputStream();
Bitmap bmp = null;
try {
URL url = new URL(contactJson.getUrlImage());
bmp = BitmapFactory.decodeStream(url.openConnection().getInputStream());
bmp.compress(Bitmap.CompressFormat.PNG, 100, bmpStream);
}В Android есть встроенные методы для загрузки данных из сети, Retrofit можно и не привлекать.
Через BitmapFactory можно загрузить данные из сети, получив Bitmap-изображение, а дальше уже массив байтов можно отправлять в базу данных, используя уже знакомый ContentValues.
ContentValues values = new ContentValues();
values.put(IMAGE, bmpStream.toByteArray());Безопасный Select
Все запросы, которые мы только что строили, идут напрямую в базу, без какой-либо предварительной валидации. Это прекрасная возможность для SQL-инъекции — злоумышленник легко может подставить нужные параметры и выполнить совершенно другой запрос. Это популярная атака, и немало материалов по ней ты найдешь в нашем журнале. Конечно, можно самому написать парсер, который будет выискивать «неправильные» символы и по максимуму фильтровать запросы. Но это очень спорный костыль, который и не факт, что поможет.
К счастью, это проблему можно решить с помощью штатных способов. В Android есть билдер SQLiteQueryBuilder, который самостоятельно сгенерирует запрос, валидируя поступающие параметры.
SQLiteQueryBuilder builder = new SQLiteQueryBuilder();С его помощью легко строить как простые запросы из одной таблицы, так и более сложные, с фильтрацией и объединением. Такой случай и разберем — в базе две таблицы, и, чтобы получить все данные по пользователю, нужно их сначала скомпоновать. Для этого подойдет способ LEFT OUTER JOIN, который позволяет объединять таблицы, выбирая данные по совпадающим полям.
Билдер принимает данные порционно, что позволяет системе проверять их на корректность. Метод setTables задает набор таблиц, из которых будет построена выборка, — это может быть как одна таблица, так и объединение нескольких.
builder.setTables(TABLE_USERS+ " LEFT OUTER JOIN " +
TABLE_IMAGES + " ON ( " + TABLE_IMAGES + "."+ IMAGE_ID +
" = " + TABLE_IMAGES + "."+ IMAGE_ID + ")");Сам запрос строится с помощью buildQuery — ему указываются параметры выборки, а конструктор уже самостоятельно строит SELECT-запрос. Использование таких параметризированных запросов существенно снижает возможность SQL-инъекции.
builder.buildQuery(new String[]{USER_NAME, USER_DESCR, IMAGE}, USER_ID + " = "+id,null,null,null,null);Готовность к любым запросам — еще один плюс такого подхода. Конструктор позволяет на лету подставлять любые критерии, формируя выборку по желанию пользователя. Такого очень сложно добиться, используя rawQuery.
Robolectric
Скажу честно, правильные SQL-запросы получаются у меня не всегда с первого раза. Конечно, если каждый день работаешь с крупными базами данных, подобных проблем не будет, но такие люди редко пишут Android-приложения. Наверняка ты уже задался вопросом, как же проверять корректность всех этих SELECT, UPDATE и сложных объединений таблиц. Если ты никогда раньше не писал тесты, то сейчас поймешь, насколько это может быть удобно: они позволяют сверить ожидаемый результат с тем, что получилось в результате SQL-запроса.
В мире Android очень много инструментов для тестирования Java-кода. Сейчас мы воспользуемся фреймворком Robolectric — он позволяет прогонять код прямо на рабочей станции без использования эмуляторов и реальных устройств. Эта библиотека подключается, как и любая другая, через Gradle.
testCompile 'org.robolectric:robolectric:3.1.4'Все тесты должны лежать в папке src/test, каких-то дополнительных ограничений нет. Для проверки базы данных я создал отдельный файл с именем DBTesting. Системе нужно указать, чем именно запускается тест, делается это с помощью аннотаций.
@RunWith(RobolectricTestRunner.class)
@Config(constants = BuildConfig.class)
public class DBTesting { ... }Как правило, перед запуском теста нужно подготовить входные данные и объявить зависимые блоки кода. Делается это в методе setUp со специальной аннотацией Before.
DummySQLite sqLite;
ContactJson json;
...
@Before
public void setUp() { ... }Тестирование начинается с инициализации объектов — в частности, класс DummySQLite создает экземпляр базы данных. Дефолтный конструктор требует контекст приложения, которого по факту не будет — приложение запустится только частично, и контекст нужно эмулировать. Для этого в Robolectric есть класс ShadowApplication.
ShadowApplication context = Shadows.shadowOf(RuntimeEnvironment.application);
sqLite = new DummySQLite(context.getApplicationContext(), "",null, 0);Еще в методе setUp можно подготовить экземпляр класса ContactJson, который будет загружаться в базу данных. Поскольку Retrofit мы тестировать не будем, инициализируем объект самостоятельно.
json = new ContactJson();
json.setId(1);
json.setDescription("description #1");
json.setName("first");
...Набор данных готов, теперь можно писать и сами тесты. Для начала неплохо бы проверить, что база принимает на вход данные. Каждый тест — это обычный метод, но со специальной аннотацией Test.
@Test
public void createItem() {
sqLite.insertPerson(json);
}Метод, добавляющий данные, ничего не возвращает, а значит, выполнится с ошибкой, только если будут ошибки в синтаксисе SQL. Такой тест малоинформативен, интереснее проверять методы, использующие SELECT-запрос.
ContactJson json = sqLite.selectPerson(1);Наверняка ты уже писал свои тесты, только результаты приходилось проверять глазами, сравнивая выдаваемый результат с желаемым. Здесь такое повышенное внимание не нужно — есть класс Assert, созданный для сравнительного анализа результатов вычислений.
Assert.assertEquals("first", json.getName());Типов сравнений более чем достаточно. К примеру, мы знаем, что изображение должно быть, но размер в точности до байта нам неизвестен. Тогда будет достаточно проверить, что выгружаемое изображение больше эталонного значения.
Assert.assertTrue(json.getImage().length>1);Внутри каждого теста может быть несколько таких проверок, ограничений нет. Результат их работы вполне нагляден: если тест пройден полностью, он будет подсвечен зеленым, пройден частично — оранжевым. Красный цвет означает ошибку, выскочившую в коде проверяемых методов.
Часто разработчики пользуются лог-сообщениями, которые в обычной ситуации выводит Logcat. Здесь они по умолчанию не выводятся, но их можно перехватить с помощью ShadowLog.
ShadowLog.stream = System.out;Покрывать созданные методы тестами полезно для выявления косяков, которые могут выскочить уже на стадии релиза. Некоторые разработчики даже сначала пишут тесты, а только потом исходный код проверяемых методов — этот модный прием называется TDD, Test-driven development. А при работе с базами данных они вообще незаменимы: все тесты логически изолированы, можно вносить данные без каких-либо опасений, они никогда не попадут в «настоящие» таблицы.
Outro
Каждый из нас сталкивался с программами, которые пренебрегают кешированием, вновь и вновь подгружая данные из сети. Уверен, ты такие писать теперь не будешь :). Мне осталось только добавить, что работать с базой лучше в отдельном потоке, в этом поможет RxJava или просто AsyncTask. Созданный сегодня проект можно нагрузить чем угодно, используя этот код как шаблон для своих проектов. Чтобы лучше понять логику работы с SQLite, скачай с нашего сайта полные исходники используемых классов и тестов Robolectric. Если останутся какие-то вопросы, пиши в комментарии — постараюсь ответить. Удачи!











