

Содержание статьи
Начну с чистосердечного признания: я — фанат RSS. Я прекрасно знаю, что этот формат уже не в моде и что для многих социальные сети полностью заменили старые добрые новостные агрегаторы. Но таких, как я, пока что достаточно для того, чтобы существовали прекрасные средства для работы с фидами. Об одном из них я и хочу рассказать. Пусть тебя не смутит хардкорность его установки и настройки: возможности, которые ты получишь в итоге, окупят всю мороку.
Задумка
Мысли о том, что хорошо бы как-нибудь настроить фильтрацию RSS, я вынашивал давно — практически все время, что я пользуюсь агрегаторами (то есть примерно со времен появления Google Reader и яндексовской «Ленты»; ныне оба уже не работают). Возможность зафильтровать элементы фида по ключевым словам мне попалась в маковском клиенте ReadKit (подробности — в моем обзоре за 2014 год), но я предпочитаю Reeder, к тому же фильтры должны работать на серверной стороне, иначе клиенты для телефона и планшета останутся в пролете.
Временным решением стал переход с Feedly, который я использовал в качестве бесплатного бэкенда, на Inoreader — замечательный сервис, разработанный крайне мотивированной и душевной польской командой (о нем я, кстати, тоже уже писал). В платной версии Inoreader есть поддержка фильтров (до 30 штук) и другие приятные фичи.
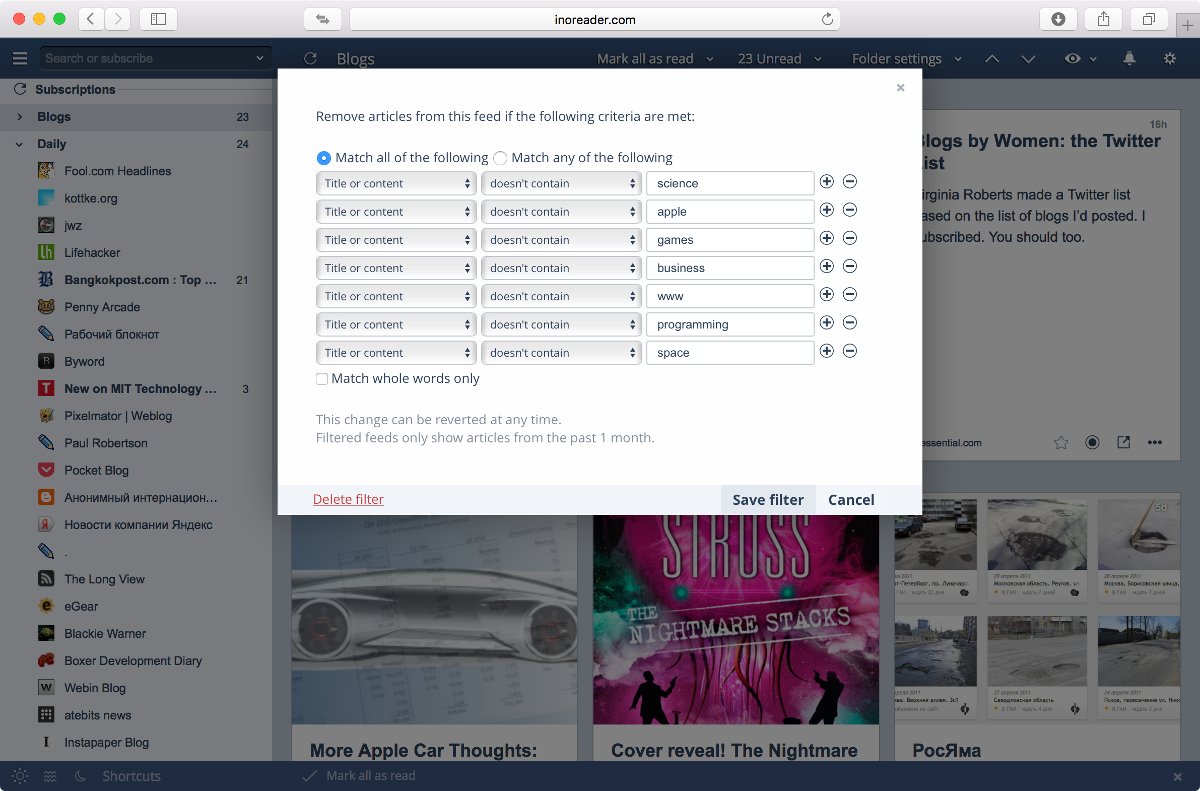

Однако тариф с фильтрами обходится в 30 долларов за год, что сравнимо с ценой недорогого хостинга. А это уже наводит на вполне конкретные мысли: нельзя ли сделать собственный аналог и вместо встроенных фильтров, логика которых ограничена, писать любые скрипты?
Проще всего, наверное, было бы написать пару скриптов, которые бы по расписанию забирали, обрабатывали и выкладывали нуждающиеся в фильтрации фиды на какой-нибудь хостинг, а тот же Feedly их бы оттуда подхватывал. Однако, наткнувшись на проект Coldsweat, я не мог устоять.
Coldsweat — это опенсорсный клон Fever, платного средства синхронизации RSS, которое предназначено для установки на свой сервер. Собственно, существование протокола Fever и делает Coldsweat удобным: поддержка Fever API есть в некоторых продвинутых агрегаторах, в том числе в Reeder. Coldsweat написан на Python, использует базу данных SQLite (по желанию можно настроить PostgreSQL или MySQL), имеет систему плагинов и веб-интерфейс. То, что нужно!
Приготовления
Вот список того, что понадобится для развертывания Coldsweat.
- Дистрибутив Coldsweat. Скачай или клонируй его с GitHub.
- Сервер с UNIX или Linux и как минимум доступом к cron и .htaccess (лучше, конечно, полный шелл).
- Python 2.7, желательно не младше 2.7.9. С Python 3.x Coldsweat не заведется.
- Библиотеки Peewee, Requests, WebOb и Tempita. Все они перечислены в файле requirements.txt, так что можешь просто написать
pip install -r requirements.txt(в системе для этого должны быть командыpipиeasy_installиз пакета python-setuptools). - Библиотека Flup — на сервере она понадобится в том случае, если ты будешь использовать FastCGI (а это рекомендуется); для локального тестирования она не нужна.
Установка
Скачав Coldsweat и установив зависимости, ставим его, как написано в инструкции. Для начала копируем конфиг из файла с примером:
$ cp etc/config-sample etc/configЗабегая вперед, скажу, что у меня Coldsweat со стандартным конфигом не заработал, причем Python падал без объяснения причин. Проблемой, как оказалось, была многопоточность, так что рекомендую для начала выключить ее. Для этого открой etc/config, найди строку ;processes: 4, убери точку с запятой и поменяй 4 на 0. Заодно можешь глянуть на остальные настройки.
Возвращаемся в корень проекта и выполняем команду
$ python sweat.py setupСкрипт попросит данные для учетки, после чего создаст базу данных. Если твоим сервером будет пользоваться кто-то еще, посмотри в инструкции, как регистрировать дополнительных пользователей.
Теперь импортируем файл OPML со списком фидов. Для тестирования автор Coldsweat рекомендует взять subscriptions.xml из каталога coldsweat/tests/markup/, но лучше лишний раз не мусорить в базе и сразу добавлять актуальный список.
$ python sweat.py import путь/к/файлу.xmlПроверяем, забираются ли фиды:
$ python sweat.py fetchЕсли все настроено правильно, то через какое-то время скрипт завершится со словами «Fetch completed. See log file for more information». Если запустить sweat.py с параметром serve, то на порту 8080 у тебя заработает тестовый веб-сервер. Можешь сразу подключить к нему агрегатор, чтобы было удобнее тестировать.
Есть одна проблема
Перейдя с того же Feedly на свой сервер, мы лишились возможности добавлять фиды через агрегатор и перекладывать их из папки в папку перетаскиванием. Reeder, к примеру, поддерживает такие функции для Feedly и Inoreader, но не для Fever. Наводить порядок теперь придется через веб-интерфейс Coldsweat, а добавлять фиды можно будет букмарклетом (когда поставишь Coldsweat на свой сервер, нажми на кнопку + в левой панели веб-интерфейса и перетащи букмарклет оттуда на панель браузера).
Пишем простой плагин
Синхронизация и скачивание фидов работает, а значит, мы уже можем сделать всякие интересные штуки. Coldsweat поддерживает плагины, так что попробуем воспользоваться ими в своих целях. Вот пример совсем простого плагина, который следит за поступлением комиксов Cyanide & Happiness, заходит на страницы по ссылкам и перекладывает комиксы оттуда в сам фид (подразумевается, что необходимый RSS уже добавлен в список).
import urllib2, re
from coldsweat import *
from coldsweat.plugins import *
@event('entry_parsed')
def entry_parsed(entry, parsed_entry):
if entry.feed.title == 'Cyanide & Happiness':
request = urllib2.Request(entry.link)
page = urllib2.urlopen(request).read()
m = re.search(r'<img decoding="async" id="main-comic" src="//(.+)\?', page)
if m is not None:
entry.content = '<img decoding="async" src="' + m.group(1) + '">'Здесь используется декоратор @event, чтобы функция entry_parsed вызывалась каждый раз, когда заканчивается парсинг записи. Еще существуют события fetch_started и fetch_done — они срабатывают, соответственно, когда начинается или заканчивается процесс агрегации фидов. Если при написании плагинов тебе понадобится знать структуру объектов типа Entry или Feed, то можешь подсмотреть их в файле models.py.
Чтобы плагин заработал, сохрани его в папку plugins, к примеру, под именем cyanide.py, а затем найди в etc/config секцию [plugins] и впиши туда строчку load: cyanide. Все последующие плагины будут перечисляться дальше через запятую.
Добавляем Readability
Следующий полезный трюк, который можно провернуть на своем сервере и нельзя было сделать при помощи Inoreader, — это подкачка полнотекстовых записей. Конечно, в том же Reeder ты всегда можешь нажать кнопку Readability и получить текст поста, но включать такую функцию по умолчанию автор агрегатора не стал по этическим причинам. Мы же в частном порядке вполне можем позволить себе это маленькое удобство.
К сожалению, сервис Readability вот-вот закроется и возможность получать новые ключи к API уже убрали. Разработчики рекомендуют переходить на Mercury — аналог, который разрабатывает другая команда. Что ж, послушаем их совета.
Чтобы использовать Mercury, понадобится зайти на сайт сервиса и зарегистрироваться. После регистрации тебе выдадут ключ, при помощи которого ты сможешь обращаться к API из своих скриптов. Услуга пока что бесплатная, без видимых ограничений.
Создадим теперь конфигурационный файл со списком фидов, содержимое записей в которых мы будем получать через Mercury. Я, к примеру, создал файл mercury-feeds.json и положил его в папку etc внутри проекта.
[
{"title": "The Verge", "image": "yes"},
{"title": "AppleInsider", "image": "no"},
{"title": "Kotaku", "image": "no"}
]В поле title вносится подстрока, которая должна присутствовать в названии фида, поле image нужно, чтобы скрипт определял, вставлять или не вставлять в начало поста титульную картинку (к примеру, в фидах Kotaku и AppleInsider она уже включена, а на Verge — нет).
А вот, собственно, сам плагин.
import urllib2, json
from coldsweat import *
from coldsweat.plugins import *
headers = {'x-api-key': 'твой-ключ-от-Mercury'}
@event('entry_parsed')
def entry_parsed(entry, parsed_entry):
feeds = json.loads(open('etc/mercury-feeds.json').read())
for feed in feeds:
if feed['title'] in entry.feed.title:
url = entry.link
request = urllib2.Request('https://mercury.postlight.com/parser?url=' + url, headers=headers)
mercury = json.loads(urllib2.urlopen(request).read())
if 'lead_image_url' in mercury and mercury['lead_image_url'] is not None and feed['image'] == 'yes':
image = '<img decoding="async" src="' + mercury['lead_image_url'] + '">'
else:
image = ''
if 'content' in mercury:
entry.content = image + mercury['content']
else:
entry.content = imageНе забудь вставить свой ключ в словарь headers в начале, сохрани файл (к примеру, под именем mercury.py), кинь в plugins и пропиши в etc/config. Теперь можно наслаждаться полнотекстовыми фидами!
Делаем систему фильтров
Мы добрались до того, ради чего я затевал все это дело, — фильтрации фидов по ключевым словам. К сожалению, при помощи системы плагинов сделать полноценные фильтры мне с наскока не удалось, и пришлось грубо хакнуть сам Coldsweat.
Проблема в том, что ивент entry_parsed вызывается после того, как запись получена, но до того, как она сохраняется в базе. Соответственно, стереть ее из базы плагин не может. Наверное, правильнее было бы обрабатывать событие fetch_done и проходиться по базе в поисках неугодных нам записей, но я выбрал самый короткий путь и добавил кастомную проверку.
Открываем файл fetcher.py и ищем строки
trigger_event('entry_parsed', entry, entry_dict)
entry.save()Оборачиваем их в условие if(check.check_entry(entry)): (не забудь отступы, а то Python тебе этого не простит) и добавляем в начало файла строку import check. Остается в той же папке создать файл check.py с описанием функции check_entry. Вот его содержимое.
import json
def check_entry(entry):
rules = json.loads(open('etc/rules.json').read())
flag = True
for rule in rules:
Filter = True if rule['filter'] == 'this' else False
if entry.feed.title.find(rule['feed']) > -1:
if 'title' in rule:
Keywords = any(x in entry.title for x in rule['title'])
if (Keywords and Filter) or (not Keywords and not Filter):
flag = False
if 'author' in rule:
if (entry.author.find(rule['author']) > -1 and Filter) or (entry.author.find(rule['author']) == -1 and not Filter):
flag = False
return flagЗдесь есть проверки полей title и author, остальные (к примеру, 'link') можешь дописать сам по аналогии, если понадобится. А вот выдержка из моего файла etc/rules.json:
[
{
"feed": "asymco", "filter": "this", "title":
["Asymcar",
"Critical Path",
"Significant Digits",
"Sponsor:"]
},
{
"feed": "Charlie's Diary", "filter": "this", "title":
["guest blogger"]
},
{
"feed": "Charlie's Diary", "filter": "other", "author":
"Charlie Stross"
},
{
"feed": "O'Reilly Radar", "filter": "other", "title":
["Four short links"]
}
]В поле feed содержится подстрока, которая должна быть в названии фильтруемого фида (регистр учитывается), filter — режим фильтрации (слово this будет означать фильтрацию записи с перечисленными далее словами, other — записей, которые, наоборот, таких слов не содержат). Поле author используется, чтобы проверять имя автора.
Например, в блоге писателя Чарли Стросса я хочу видеть только его собственные записи, а не приглашенных авторов, заодно скрываются и посты, где он этих авторов представляет (они имеют пометку guest blogger). В блоге Asymco меня не интересуют спонсорские посты и анонсы подкастов, из которых фид состоит более чем наполовину. А в блоге O’Reilly Radar я читаю только рубрику Four short links. Думаю, идея ясна.
Ставим Coldsweat на свой сервер
Если на локальной машине все работает как положено, то можно переходить к следующему этапу — установке Coldsweat на свой сервер. Там для этого уже должен стоять Apache или nginx. Скажу сразу, подружить Coldsweat с nginx у меня не вышло — я поправил конфиги, как описано в руководстве, но по причинам, так и оставшимся неизвестными, из этого ничего не получилось. Возможно, помогло бы поставить прослойку в виде uWSGI или Gunicorn, но настраивать еще и один из них желания не было. Так что я выбрал Apache и FastCGI, и все с легкостью завелось.
Если ты уже залил Coldsweat на сервер, то осталась всего пара шагов. Первый — настройка Apache. Пример его конфига ты можешь найти в справке к Coldsweat (обрати внимание, для FastCGI он слегка другой). Сохрани его в файл и положи в /etc/apache2/sites-enabled. Заодно замени пути к папке static и к файлу dispatch.fcgi и не забудь дать ему права на исполнение. Еще понадобится создать пользователя www-data, если его нет, и дать ему права на каталог с Coldsweat.
Теперь можешь зайти через браузер, и если все настроил правильно, то увидишь веб-интерфейс Coldsweat. Чтобы читать фиды через агрегатор, добавь себе аккаунт Fever, а в поле адреса укажи URL своего сервера с припиской /dispatch.fcgi/fever/.
Теперь нам нужно сделать так, чтобы база обновлялась через определенные интервалы времени. Это легко — достаточно прописать скрипт sweat.py fetch в crontab. Поскольку Coldsweat работает с локальными путями, можешь добавить его каталог в PATH или сделать вот такую обертку:
#!/usr/bin/env bash
cd путь-к-coldsweat/
python sweat.py fetchНазови ее, к примеру, cs.sh, дай права на исполнение и добавляй в crontab строку
*/10 * * * * /путь/cs.shЭто задаст интервал проверки раз в десять минут.
Что дальше
Мы прошлись по самым простым доработкам к Coldsweat и создали систему фильтрации, которую ты можешь пополнять и совершенствовать в соответствии с возникающими потребностями. Это уже само по себе неплохое подспорье для любителя RSS. А еще ты теперь знаешь, как дописать к Coldsweat все, что тебе вздумается: можешь как угодно модифицировать записи, запрашивать дополнительные страницы, создавать свои фиды или, например, подключить нейросеть, которая будет генерировать фид на основе личных предпочтений. Возможности, как говорится, безграничны.
Если хочешь поделиться своим опытом, наработками или ценными идеями, отписывайся в комментариях!








