Содержание статьи
Вот уже более пяти лет вместе с друзьями я загружаю простаивающие мощности наших компьютеров заданиями из международных научных проектов. Все они генерируют терабайты экспериментальных данных, которые не могут быть обработаны за приемлемое время на оборудовании самих исследователей. Денег на облачные вычисления у многих нет, как и доступа к суперкомпьютерам, поэтому научное сообщество использует труд добровольцев.
Годами мы считали под общим аккаунтом, постоянно анализировали результаты и делились наблюдениями. Особенно интересно было сравнивать производительность разных видеокарт в реальных расчетах. Как оказалось, с ними связано очень много неявных моментов, а синтетические бенчмарки в основном заточены на игры и слабо отражают ценность видеокарт для неграфических вычислений.
Благодарность
Редакция выражает благодарность компании Inno3D и ее российскому представительству, оперативно предоставившему для тестирования видеокарту Inno3D GeForce GTX 1070 iChill X4.
Собственные тесты
Должен пояснить, что я не сторонник ни «красных», ни «зеленых». Просто для каждой задачи стоит подбирать свой инструмент и не пытаться сравнивать кита со слоном.
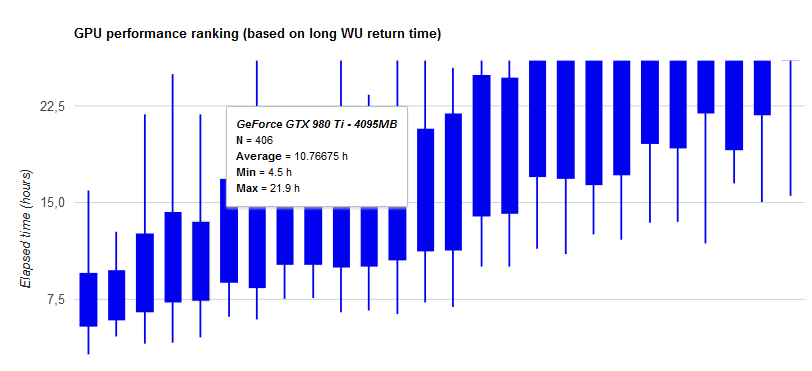
Команда TSC оформила в виде таблицы результаты разных видеокарт в реальных научных расчетах. Если отсортировать их с учетом энергоэффективности и универсальности применения, то всю верхнюю часть рейтинга будут занимать решения Nvidia с архитектурой Pascal, включая GTX 1070. Новейшие Radeon Vega и мощная R9 Fury встречаются в ней на 182-й строке и позже.
Современные ГП производства AMD подходят только для расчетов с поддержкой OpenCL, в то время как ГП Nvidia можно использовать и для OpenCL, и для CUDA-оптимизированных приложений. В отдельных случаях старые AMD выигрывают на операциях двойной точности ценой больших энергозатрат при решении обычных задач.
По сравнению с GTX 980Ti видеокарта на базе GTX 1070 демонстрирует небольшой прирост скорости вычислений — на 2,4%. Однако этот выигрыш наблюдается при существенном снижении потребляемой мощности — на 25% или на 50 Вт. Апгрейд стоит затевать уже ради этого.

Наш тестовый стенд остался прежним, но до GTX 1070 мы успели протестировать в научных расчетах множество других видеокарт и процессоров. В этой статье упоминаются только самые показательные результаты.

По сравнению с флагманами прошлых лет (GTX 680 и максимально близкой к ней GTX 770) у новой GTX 1070 скорость вычислений выросла более чем в четыре раза. Это видно даже на старых OpenCL-приложениях, не имеющих оптимизации для современных ГП Nvidia. Например, в проекте Einstein@Home на GTX 680 одно задание выполняется в среднем за 50 мин, а на GTX1070 — за 11,5 мин.
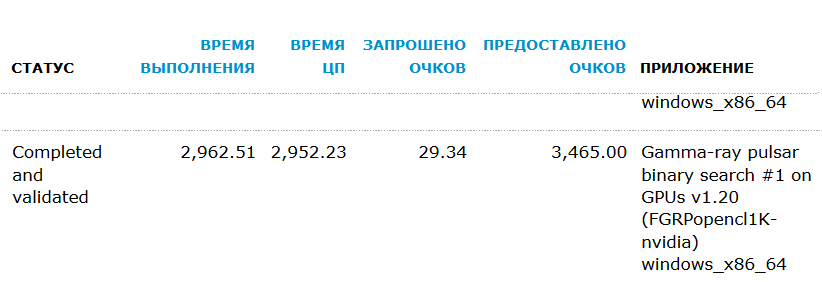

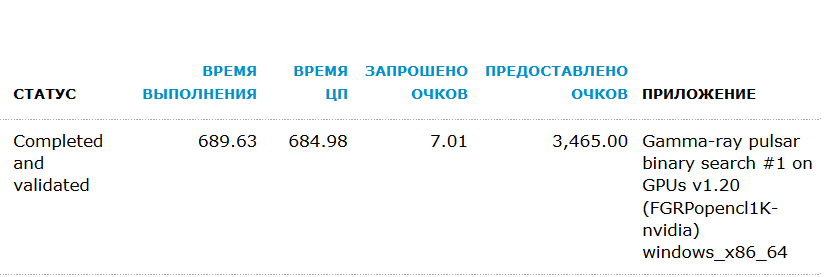
Параллельно видеокарта использовалась для тестов при написании статей про майнинг и брутфорс паролей. Тем не менее за два месяца смешанного тестирования GTX 1070 мы выполнили больший объем научных расчетов, чем до этого почти за пять лет на 20+ процессорах и паре эпизодически работающих старых видеокарт. Разница просто колоссальная.
Длительный период (до конца 2014 года) вычисления выполнялись только на процессорах нескольких компьютеров. Скорость прироста была ничтожной. Затем еще два года мы загружали расчетами старые видеокарты. Они всегда сильно грелись и шумели, а изображение лагало. С этим трудно мириться во время работы, поэтому расчеты выполнялись эпизодически.
В конце прошлого года друзья подарили мне GTX 680 специально для ускорения расчетов. К тому моменту эта карта уже плохо подходила для игр, но вполне справлялась с научными вычислениями. Давно хотелось попробовать ускоритель с архитектурой Kepler, да еще и содержащий 1536 CUDA-ядер!

Из-за мощного трехслотового охлаждения работала GTX 680 довольно тихо, но воздух нагревала прилично — все-таки двести ватт. Зимой это было очень кстати, но вот в жару... Посчитав за три месяца сотни разных заданий с ГП-оптимизацией, я заметил, что в одних проектах загрузка видеокарты заданиями BOINC почти не чувствуется, а в других — делает любую работу крайне некомфортной. Даже при наборе текста иной раз отмечались лаги. Поэтому я собрал комп с Core i7 и подключил монитор к его интегрированному видеоядру, а GTX 680 использовал только для расчетов. В таком варианте ее можно было использовать круглосуточно, и результативность вычислений выросла вдвое.
После GTX 680 настал черед тестировать GTX 980Ti, а затем и GTX 1070. У двух последних видеокарт с подключенным монитором совершенно не было лагов изображения при максимальной загрузке расчетами. Во всяком случае, они не замечались при работе с текстами, веб-серфинге, обработке картинок и просмотре фильмов. Однако для чистоты эксперимента мы все-таки подключали их без монитора. Первый крутой пик на графике соответствует подключению GTX 980Ti, а следующий за ним — заслуга GTX 1070.
Объемы вычислений в BOINC отображаются в очках (cobblestones). Десять очков — это 4,32 триллиона операций с плавающей запятой одинарной точности (FP32). Первый миллион очков мы набирали два года, используя до двадцати четырех процессорных ядер одновременно. Сейчас с одной GTX 1070 мы прибавляем более миллиона очков каждый день. Частота выплат в сети Gridcoin также возросла. Если раньше монетки начислялись один-два раза в месяц, то сейчас — практически ежедневно.
Формула тут простая: меньше энергозатрат, больше компенсация и выше результативность.
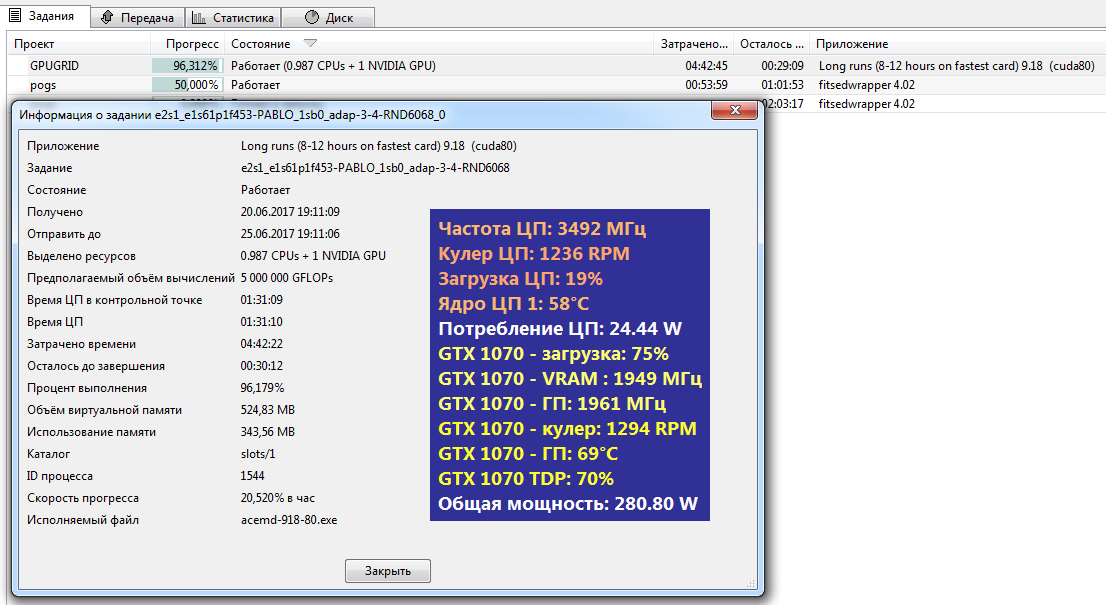
Однако есть тут и маленькая хитрость: некоторые проекты выплачивают дополнительные очки как вознаграждение за скорость выполнения заданий. К примеру, в GPUGrid есть три степени свежести решений: полученные в течение первых суток, двух и пяти дней с момента отправки заданий. За первые начисляют 50% очков, за вторые 25%, а за выполненные в интервале от 48 до 120 ч ничего не добавляют сверх. Расчеты недельной давности становятся неактуальными и не учитываются вовсе.

Большие CUDA-оптимизированные задания GPUGrid обрабатываются на топовых видеокартах за 8–12 ч. GTX 680 на них требовалось около 30 ч. Новая GTX 1070 часто справлялась за шесть часов и успевала обработать за сутки до четырех сложнейших заданий из области расчета третичной структуры белковых молекул и докинга лигандов.
Видеокарты как ускорители
Почему вообще считают на видеокартах? Любой процессор архитектуры x86-64 создавался как универсальный чип. Он умеет выполнять математические операции разных типов и разрядности, но платой за всеядность становится низкая скорость. В повседневной работе этот эффект не слишком заметен, поскольку в пользовательских приложениях преобладают простейшие арифметические операции. В научных же расчетах львиную долю составляют действия с массивами и приблизительными величинами. Центральный процессор обрабатывает их очень медленно, поэтому в профессиональных рабочих станциях и суперкомпьютерах для них используются специализированные платы — векторные ускорители.
WARNING
Научные расчеты длительно создают высокую нагрузку на процессор и видеокарту. Прежде чем запускать их, позаботься о качественном питании и охлаждении. Задать температурные ограничения тоже будет нелишним.
Ускорители для высокопроизводительных вычислений (HPC) часто построены на тех же чипах, что и топовые видеокарты, но имеют свои архитектурные особенности. Отдельные инженерные решения призваны повысить объем одновременно обрабатываемых данных и надежность круглосуточной работы с максимальной нагрузкой. Сами по себе они незначительно удорожают производство, однако себестоимость ускорителя определяется еще и малым объемом выпуска.
Любительские кластеры как альтернатива HPC
В целом есть два принципиально разных подхода к обработке научных данных: использовать высоконадежные специализированные HPC-системы с профессиональными ускорителями либо создавать сеть распределенных вычислений из непостоянных узлов с процессорами и видеокартами разной архитектуры. Первый подход обычен в прикладных сферах, тесно связанных с коммерческими разработками и не испытывающих недостатка в финансировании. Второй популярен у тех, кто выполняет некоммерческие и фундаментальные исследования. Их ценность сложно объяснить спонсорам, поэтому остается только привлекать волонтеров. Надежность обработки данных в такой гетерогенной сети обеспечивается за счет избыточности.
За последние десять лет обычные видеокарты научились выполнять микропрограммы общего назначения. Они могут быстро обработать одномерные массивы и выполнить серию расчетов с плавающей запятой, если ЦП сперва сформулирует эту часть задания в понятном для ГП формате.
Начиная с 2006 года вместо отдельных шейдерных процессоров трех разных типов, вычислявших движения частиц и прочие графические эффекты, у видеокарт появились универсальные потоковые процессоры. Это значительно упростило задачу описания ресурсоемких вычислений на понятном для ГП языке. Тогда возникла концепция GPGPU (General-purpose computing for graphics processing units) — использование ГП для ускорения неграфических вычислений.
Если очень упростить сравнение ЦП и ГП, то ключевое отличие можно сформулировать так: центральный процессор обрабатывает числа последовательно, а ГП — параллельно. Когда надо сложить одну сотню чисел с другой, ЦП выполнит сто последовательных операций сложения. ГП запишет их как два одномерных массива (вектора) и сложит все за одну операцию. В современных процессорах уже есть отдельные инструкции для ускорения векторных операций, но по скорости работы они все равно серьезно уступают ГП.
При использовании видеокарты скорость отдельных вычислений возрастает в десятки раз. Просто потому, что у ГП куча исполнительных блоков, способных работать одновременно. Это не четыре ядра у Core i5 и не двенадцать ядер у Xeon. Речь о тысячах универсальных процессоров с частотой 1–2 ГГц и собственной памятью с огромной пропускной способностью. О целом кластере в формате платы расширения.
AMD vs Nvidia + Intel
Использование видеокарт для неграфических вычислений требует определять их в системе как сопроцессоры и использовать через соответствующие API средствами драйвера. Это интерфейсы прикладного программирования OpenCL, CUDA и DirectCompute. По сути — три варианта написания кода для программ с поддержкой GPGPU.
Все эти годы концепция GPGPU активно развивалась в основном за счет открытого API OpenCL и проприетарной технологии Nvidia CUDA. За редким исключением все драйверы для графических решений AMD, Nvidia и Intel поддерживают OpenCL, но часто уровень этой поддержки оставляет желать лучшего. Например, заявление о поддержке OpenCL 2.0 на деле может означать, что в текущем драйвере и конкретном ГП поддерживаются лишь некоторые возможности версии 2.0.
Продолжение доступно только участникам
Вариант 1. Присоединись к сообществу «Xakep.ru», чтобы читать все материалы на сайте
Членство в сообществе в течение указанного срока откроет тебе доступ ко ВСЕМ материалам «Хакера», позволит скачивать выпуски в PDF, отключит рекламу на сайте и увеличит личную накопительную скидку! Подробнее
Вариант 2. Открой один материал
Заинтересовала статья, но нет возможности стать членом клуба «Xakep.ru»? Тогда этот вариант для тебя! Обрати внимание: этот способ подходит только для статей, опубликованных более двух месяцев назад.
Я уже участник «Xakep.ru»