Содержание статьи
- Нефункциональные требования, или «хочу, чтобы все работало быстро»
- Определяемся с требованиями к производительности
- Такие разные тесты
- Тесты производительности
- Load testing, или «загрузка завершена на 80%»
- Cтресс-тестирование — даешь максимальную нагрузку!
- Configuration testing — «А давайте уберем debug=True из конфига?»
- Как (не) тестировать?
- Как писать перформанс-тесты?
- Мир Java и JMeter
- Tsung и Erlang
- Locust, или пишем тесты на Python
- CI и тестирование производительности
- Железо vs. виртуальное окружение
- Заключение
Завершая цикл статей (часть 1, часть 2) о вычислении производительности софта, хотелось бы рассказать, как правильно проводить перформанс-тестирование (performance testing). Тема становится все более популярной, но при этом далеко не все понимают, что под этим подразумевается. Ведь прежде чем ответить на вопрос «как», нам нужно разобраться с вопросом «что»: что именно нам нужно тестировать?
Нефункциональные требования, или «хочу, чтобы все работало быстро»
В теории перед тем, как начать программировать, нужно придумать спроектировать архитектуру будущего софта. Но еще раньше надо определиться с требованиями, которые бывают как функциональные (нужна кнопка «Вход» и такие-то страницы), так и нефункциональные (например, использовать PostgreSQL, Ubuntu 14.04). Одним из типов нефункциональных требований и являются требования к производительности.

Определяемся с требованиями к производительности
Требования к производительности могут и даже должны отличаться от проекта к проекту — практически не бывает двух проектов с одинаковыми требованиями. Их можно сгруппировать по типам софта (это описано в разных книгах по методологии тестирования, но я буду полагаться на свой опыт, а книги ты и так сможешь прочитать).
- Desktop-приложения (актуально и для современных мобильных и веб-приложений). В таком софте обычно важны скорость запуска, время отклика на нажатия клавиш (никто не хочет ждать десять секунд после нажатия на пункт меню), время выполнения распространенных операций. Например, в текстовом редакторе при открытии файла можно и подождать секунду-другую, но вот ждать столько же, пока на экране появится набранный символ, — это нонсенс.
- Server-side приложения — всевозможные СУБД, API (REST-, SOAP-, RPC-серверы) и так далее. Тут список требований к скорости работы может быть просто огромный, начиная от времени ответа на запрос для одного клиента и заканчивая временем отклика при условии, что у нас есть одновременно 1k клиентов к REST API и все они что-то делают.
- *aaS, всевозможные облака. Производительность облака может измеряться совсем иначе, чем, например, REST API сервиса. Тут в зависимости от типа облака все может сильно и очень сильно меняться. В случае с perfomance SaaS (software-as-a-service) требования почти такие же, как и к любому высоконагруженному веб-приложению. А вот если ты тестируешь IaaS (infrastructure-as-a-service), то требования могут быть совсем другими, например: запуск X виртуальных инстансов не должен занимать больше Y времени, а вот временем, сколько она будет выключаться, иногда можно и пренебречь.
Тут как и с любыми требованиями — нужно отталкиваться от того, что в итоге должно получиться, и не забывать про здравый смысл. Ведь если твой REST API отправляет ответ за одну секунду, а WEB UI потом десять секунд отображает результат, то оптимизировать бэкенд нужно не в первую очередь. Пользователи будут более благодарны за быстрый UI.
Такие разные тесты
Основных видов перформанс-тестирования не так уж и много: performance testing, load testing (нагрузочное тестирование), stress (стресс-тестирование) и configuration (конфигурационное тестирование, где мы меняем всевозможные параметры софта и железа). Исходя из требований, времени и возможности (см. «треугольник требований»), мы можем выбрать необходимые тесты. Поговорим подробнее о них, прежде чем приступить к написанию тестов.
Тесты производительности
Тут все просто и очевидно. Запускаем тест и смотрим, сколько времени он выполнялся и насколько стабильно работал. В идеальном случае такие тесты должны работать на твоем CI (Continuous Integration), а сравнивать результаты нужно с результатами предыдущей версии продукта.
Load testing, или «загрузка завершена на 80%»
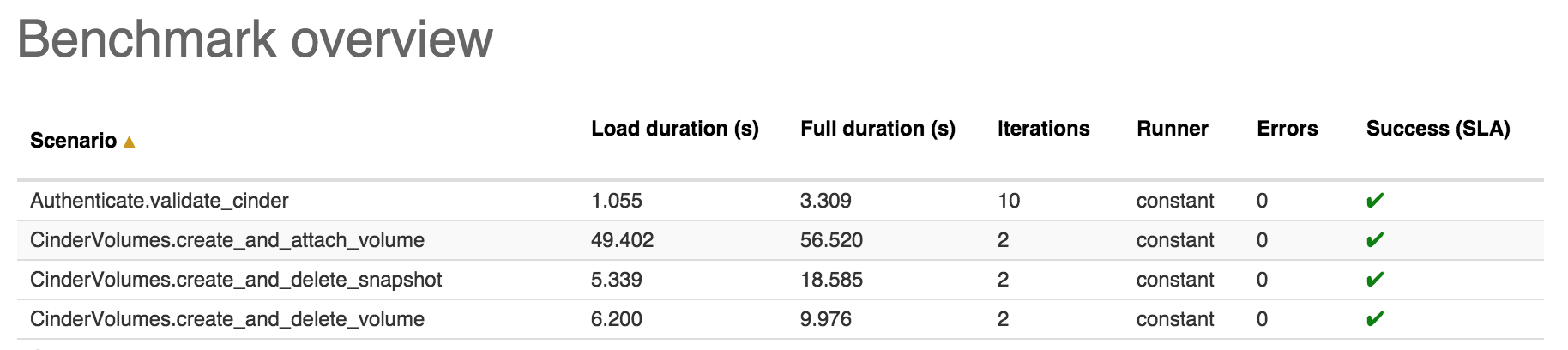
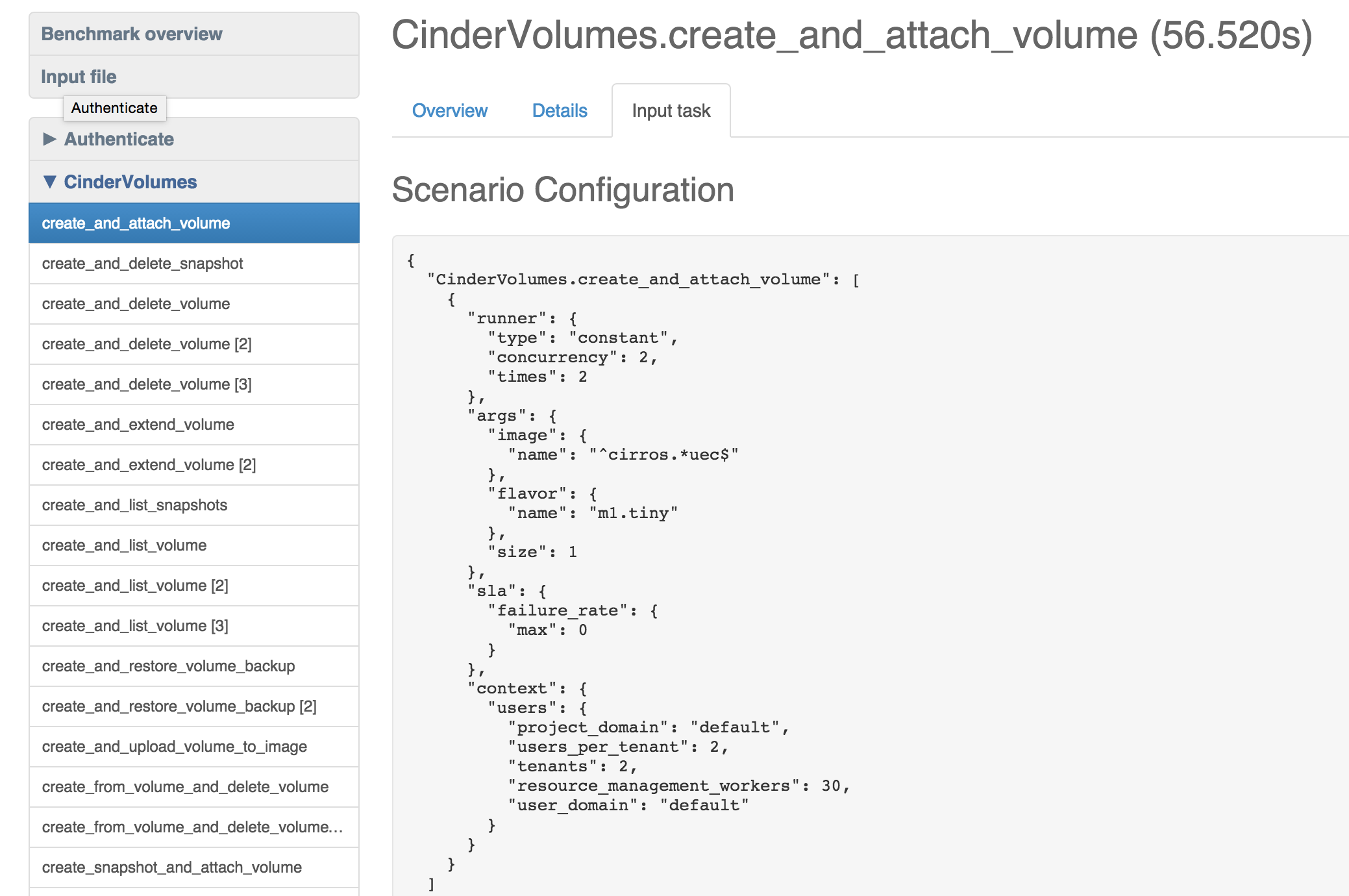
Нагрузочное тестирование — это если не самый простой, то один из самых простых вариантов тестирования производительности. Ведь что может быть легче, чем сделать 100–1000 одновременных запросов к нашему API и посмотреть, что упадет? Цель такого тестирования — не столько определить скорость работы разрабатываемого ПО, сколько оценить его поведение при ожидаемой нагрузке. Помнишь, мы говорили о требованиях? Вот здесь они и пригодятся.
Обычно в первую очередь нагрузочные тесты нацеливают на самые распространенные действия пользователей. Например, для тестирования разных компонентов OpenStack мы пытаемся эмулировать определенные действия пользователей такими сценариями:
- boot and delete VM;
- create and list volumes;
- add and remove user role и так далее.
В случае разработки очередного убийцы конкурента Facebook мы бы проверяли сценарии, относящиеся к загрузке картинок, просмотру профиля и прочему.
Во вторую очередь мы тестируем более редкие и сложные сценарии. Например, наш сайт отлично работает с кешем. Тогда тестируем то, что заведомо в кеш не попало! Результаты могут быть очень интересными :).
При нагрузочном тестировании очень важно не только собирать результаты, но и правильно их обрабатывать. Линейную зависимость между нагрузкой на систему и скоростью ее работы мы видим редко, но, как правило, это число можно принять как функцию нормального распределения. Таким образом, при большом количестве прогонов подобных тестов с разной нагрузкой в итоге можно посчитать, как софт себя поведет при необходимой нагрузке без прогона тестов. Естественно, такие числа будут неточными, но они помогут приблизительно понять, какую часть нашей системы нужно будет оптимизировать и когда.
Cтресс-тестирование — даешь максимальную нагрузку!
Если нагрузочное тестирование проверяет наш софт на соответствие требованиям производительности, то стресс-тесты дают максимальную (пиковую) нагрузку и позволяют узнать, когда наш сайт (API, база данных) перестанет работать.
Один из популярных сценариев стресс-тестирования — выяснить, будет ли работать сайт под планируемой нагрузкой или нет. Допустим, начальство готовит запуск новой рекламной кампании и вместо десяти тысяч мы ожидаем пятьдесят тысяч пользователей в час. Простое решение: изменяем конфигурацию нагрузочных тестов, увеличив каждый параметр в пять раз. Если тесты успешно пройдены, можно еще увеличить нагрузку, и так несколько раз, пока что-то не поломается. Такой подход называется пропорциональной нагрузкой, и логично предположить, что в противовес каждой пропорциональной нагрузке есть своя диспропорциональная :).
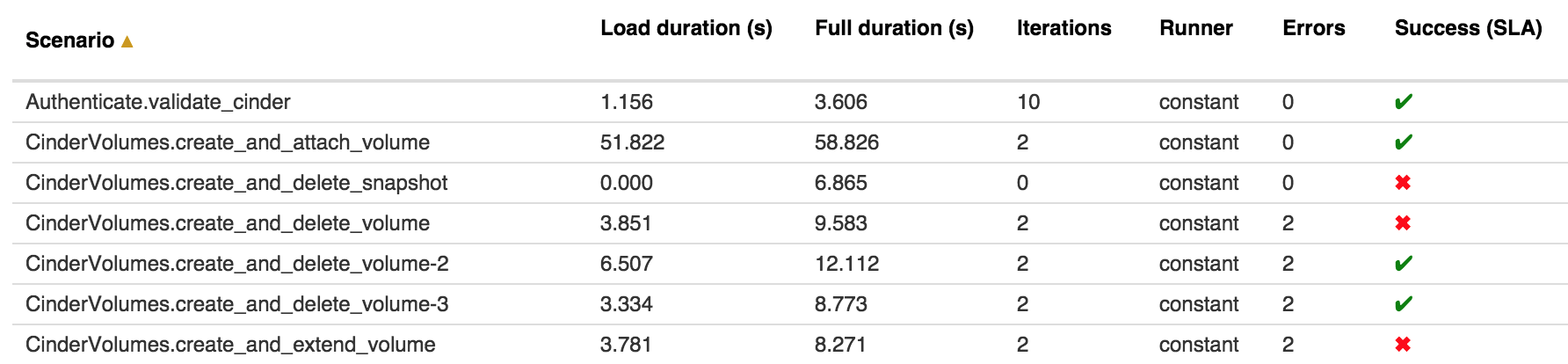
Она подразумевает неравномерную нагрузку на разные компоненты системы: например, немного на backend, много — на базу данных (или не на саму БД, а на сеть между базой данных и софтом, который ее использует, — так можно проверить, как поведет себя ПО при плохом и/или очень медленном подключении к БД).
Если даже при очень большой нагрузке все работает без видимых изменений в скорости, то, скорее всего, что-то не так с тестами. Ведь чтобы заDDoS’ить любую систему, нужно просто увеличить количество хостов, которые этот DDoS проводят. В случае стресс-тестов все может быть аналогично, хотя иногда тормозят сами тесты или недостаточно пропускной способности сети. Такое бывает, если, к примеру, ты запускаешь тесты у себя на ноутбуке, а тестовое окружение развернуто где-то на Amazon EC2.
Такие тесты очень часто падают, что может вызвать панику у менеджера или заказчика. Но упавшие тесты не всегда означают, что все плохо, — ведь мы тестируем свой продукт на каких-то граничных условиях, которых пользователи могут никогда и не достигнуть. Тест не пройден? Отлично, будем знать, какой предел у нашего приложения :). Этот вид тестов также иногда называют capacity tests или «тесты на пропускную способность железа или ПО».
Configuration testing — «А давайте уберем debug=True из конфига?»
Конфиг приложения может очень сильно влиять на производительность. От банального включения/выключения кеша и забытого флага debug=True до тонкой настройки СУБД и nginx. Бывают случаи, когда сложно предположить, как повлияет та или иная опция конфига на общую скорость работы. Поэтому такие изменения необходимо тщательно тестировать в паре с нагрузочными тестами.
Как (не) тестировать?
Универсальных советов по тестированию производительности нет и быть не может, поскольку каждый продукт индивидуален. Есть общие принципы, которые применимы к определенным типам тестов или программных продуктов. Руководствоваться ими или нет — решать тебе, я лишь поделюсь своими наблюдениями по этому поводу.
Многие крупные производители как софта, так и железа предлагают рекомендации по тестированию производительности своих продуктов. Следуя им, можно получить значения, очень похожие на те, что заявлены в рекламных буклетах. Вот только в реальной жизни от таких тестов пользы мало.
Тестирование производительности без автотестов и рабочего CI процесса — скорее исключение, чем правило. Создать руками нагрузку, которую делают десять пользователей, мягко говоря, очень сложно. А без CI трудно понять, когда и какие тесты были запущены и каков их результат. Красивые графики и диаграммы будет интересно и полезно посмотреть всем.
Тестировать производительность нужно регулярно, а результаты — тщательно анализировать, при необходимости узкие места должны быть исправлены, после чего тот же набор тестов следует запустить еще раз. Важно повторить все тесты, а не только те, которые показали низкую производительность проверяемого софта. Если после предыдущего теста остались хоть какие-то артефакты (например, созданный временный файл, запись в базу данных), то результаты следующих тестов могут быть искажены.
При написании перформанс-тестов необходимо прежде всего понимать, что и зачем будет тестироваться. Правило Парето работает и тут: если большинство использует только 20% продукта, то в первую очередь эти 20% и нужно тестировать, даже если тесты на другие функции написать быстро и легко. Тестировать производительность надо только в том случае, если это действительно нужно.
Для запуска таких тестов, как правило, не требуется много ресурсов. Я не беру случаи, когда нужно эмулировать действительно большие нагрузки. Под такие задачи выпускаются даже специальные девайсы для генерации сетевого трафика в десятки тысяч долларов стоимостью. Подобный девайс легко положит не только среднестатистический сайт, но и всю локалку, если железо в ней не будет рассчитано на соответствующую нагрузку.
Как писать перформанс-тесты?
Ответ зависит от того, кому мы зададим этот вопрос.
Разработчики с радостью напишут свой новый фреймворк на том языке, который они считают более подходящим.
DevOps-команда напишет bash-скрипт, который потом будет очень сложно поддерживать.
Тестировщики, как правило, отвечают на этот вопрос просто: «Мы будем использовать JMeter».
Самое время поговорить о распространенных фреймворках для тестирования производительности.
INFO
Как правило, перформанс-тесты полностью или частично автоматические, так как сделать необходимую нагрузку руками практически невозможно. Простой bash-скрипт, который выполняет curl — уже почти автотест.
Мир Java и JMeter
JMeter можно считать стандартом де-факто в мире тестирования производительности и Java. С его помощью можно тестировать любые веб-приложения, но сценарии придется писать на Java. Простые сценарии можно составлять без написания кода — достаточно настроек и нажатия кнопок в GUI. Главное, на мой взгляд, достоинство JMeter представляют его отчеты. После запуска и выполнения тестов он не только покажет время их работы, но и расскажет, сколько ушло на сами тесты и сколько потребовалось веб-серверу, чтобы вернуть ответ.
В Сети существует множество плагинов практически на любой случай. Всевозможные графики и диаграммы, интеграция с jUnit и Jenkins. Все это можно установить в несколько кликов мышкой и сразу же запустить тесты.
Tsung и Erlang
Про Tsung мы уже писали в «Хакере» # 164 (сентябрь 2013-го), поэтому подробно описывать его не буду. Tsung написан на Erlang и поддерживает множество протоколов от HTTP до LDAP и PostgreSQL. Его распределенная архитектура и скорость работы без труда устроит настоящее перформанс-тестирование любого сервиса, потребовав при этом минимум усилий и ресурсов.
Бояться Erlang не стоит, так как все конфигурационные файлы представляют собой понятный XML и писать код на Erlang придется только в очень специфических случаях.
Бояться Erlang не стоит, так как все конфигурационные файлы представляют собой понятный XML и писать код на Erlang придется только в очень специфических случаях.
Locust, или пишем тесты на Python
Locust — это библиотека на Python, предназначенная для разработки нагрузочных тестов (угадай, на каком языке :)). Создавать сами тесты настолько просто, что с этой задачей может справиться практически любой, кто в состоянии написать «Hello, world».
Locust может работать как локально, так и распределенно, для большей нагрузки. Фреймворк предназначен в первую очередь для тестирования веб-приложений, но ты легко можешь написать плагин для работы с нужным протоколом. В качестве примера в документации есть реализация клиента для тестирования XML RPC сервиса.
Из недостатков этого решения можно выделить то, что для его запуска необходимо открыть его Web UI, написанный на Flask, и отсутствие поддержки получения отчетов в формате xUnit.
Это доставляет массу неудобств при использовании его в CI.
CI и тестирование производительности
Про то, что любые тесты необходимо запускать на CI, говорят все. Тесты производительности в этом случае не исключение. Общие требования к CI такие же, как и для любых тестов (некоторые нюансы, конечно, есть). Так как цели перформанс-тестирования могут отличаться, то и результаты тестов нужно обрабатывать по-разному.
Например, если ты запускаешь нагрузочные тесты, которые проверяют, что приложение работает не медленнее, чем написано в техническом задании или спецификации, то каждый упавший тест необходимо обязательно анализировать и исправлять дефект. В случае же стресс-тестирования «красный» тест необязательно может означать, что есть какие-то проблемы. Возможно, просто наше приложение не рассчитано на такую нагрузку. И в продакшене подобной нагрузки никогда не будет. Следовательно, бросать все и чинить прямо сейчас не надо. Главное — объяснить менеджеру или заказчику, что это нормально (что бывает самой трудной задачей).
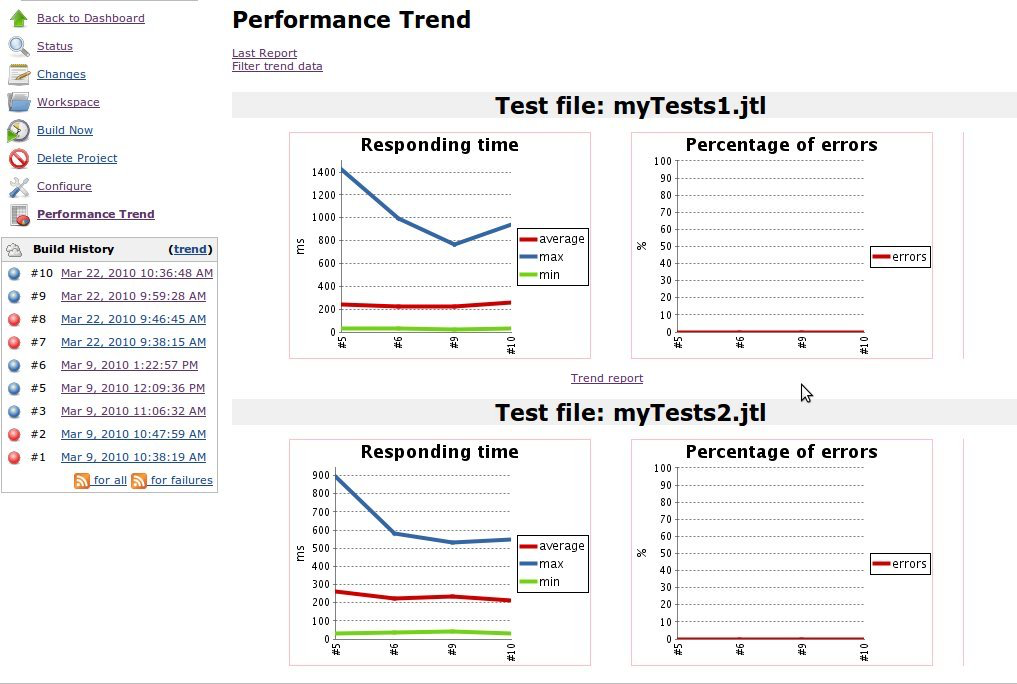
Иногда не только полезно, но и необходимо сравнивать результаты тестирования с предыдущей попыткой запуска. Для этого существует достаточно много плагинов к Jenkins. Некоторые из них сопоставляют результаты из лога в формате xUnit. Тебе необходимо только выбрать тот, который нужен.
Железо vs. виртуальное окружение
В современном мире все чаще и чаще приходится работать не с железными серверами, а с виртуальными. В большинстве случаев для тестирования производительности маленьких и средних систем виртуальных машин вполне хватает. Тем более если в продакшене тоже все на виртуалках. Но иногда проблемы, связанные с высокими нагрузками, находятся только на железе. Например, я в свое время столкнулся с багом пакета lvm2 на Ubuntu. Такой же баг был и в Debian. Внутри виртуалок у меня так и не получилось его воспроизвести, в то время как на железном сервере простой bash-скрипт на пятнадцать строчек с этим справился. Кроме того, очень тяжело находить проблемы, связанные с производительностью и высокой нагрузкой дисковых подсистем, гипервизоров и ядра на виртуальных окружениях.
Заключение
Если после тестирования производительности у тебя ничего не поломалось, значит, что-то сделано не так. Можно попробовать добавить больше нагрузки, и тогда наверняка какой-то из компонентов выйдет из строя. И это может быть не только приложение или база данных. Ядро Linux, многие приложения, которые, казалось бы, оттестированы годами, при большой нагрузке могут внезапно отказать.
Наткнуться на проблему с ядром или багом в пакете lvm2 легко. Исправить это гораздо сложнее. И я еще не говорю о выходе из строя железа и проблемах с пропускной способностью локальной сети при тестировании распределенных систем. Тестирование производительности — интересный и полезный этап разработки высоконагруженных систем. А после тестирования все только начинается...
WWW
Performance Testing Guidance for Web Applications от Microsoft были написаны еще в 2007 году, но не утратили своей актуальности.
Apache JMeter] — Java-приложение, предназначенное для нагрузочного тестирования веб-приложений.
Performance Testing Best Practicies] — webcast на тему тестирования производительности веб-приложений от Стива Миллер-Джонса (Steve Miller-Jones).