

Содержание статьи
- Что злоумышленник может извлечь из зашифрованного аудиопотока
- Атака на VoIP по обходным каналам
- Несколько слов о DTW-алгоритме
- Принцип действия HMM-автоматов
- Принцип действия PHMM-автоматов
- От теории к практике: распознавание языка, на котором идет разговор
- Прослушивание шифрованного аудиопотока Skype
- А если отключить VBR-режим?
- Заключение
Такие вопросы стали в особенности злободневными после откровений Сноудена, рассказавшего миру о тотальной прослушке, которую правительственные спецслужбы вроде АНБ (Агентство национальной безопасности) и ЦПС (Центр правительственной связи) ведут при помощи шпионского софта PRISM и BULLRUN — этому софту, как оказывается, под силу даже шифрованные переговоры.
Каким же образом PRISM, BULLRUN и другой, им подобный софт извлекает информацию из голосового потока, передаваемого по зашифрованным каналам?
Для того чтобы найти ответ на этот вопрос, нужно сначала разобраться, как в VoIP передается голосовой трафик. Канал передачи данных в VoIP-системах, как правило, реализуется поверх UDP-протокола и наиболее часто работает по протоколу SRTP (Secure Real-time Transport Protocol — протокол защищенной передачи данных в режиме реального времени), который поддерживает упаковку (посредством аудиокодеков) и шифрование аудиопотока. При этом шифрованный поток, который получается на выходе, имеет тот же самый размер, что и входной аудиопоток. Как будет показано ниже, подобные, казалось бы, незначительные утечки информации можно использовать для прослушивания «шифрованных» VoIP-переговоров.
Что злоумышленник может извлечь из зашифрованного аудиопотока
Большинство из тех аудиокодеков, которые применяются в VoIP-системах, основаны на CELP-алгоритме (Code-Excited Linear Prediction — кодовое линейное предсказание), функциональные блоки которого представлены на рисунке ниже. Чтобы добиться более высокого качества звука без увеличения нагрузки на канал передачи данных, VoIP-софт обычно использует аудиокодеки в VBR-режиме (Variable bit-rate — аудиопоток с переменным битрейтом). По такому принципу работает, например, аудиокодек Speex.
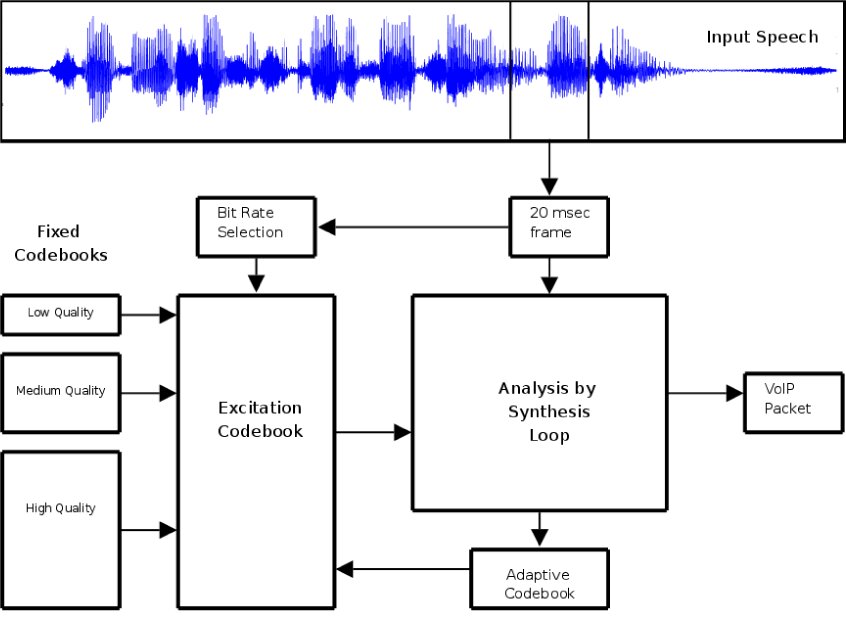
К чему это приводит в плане конфиденциальности? Простой пример. Speex, работая в VBR-режиме, упаковывает шипящие согласные меньшим битрейтом, чем гласные, и более того — даже определенные гласные и согласные звуки упаковывает специфическим для них битрейтом. График на рисунке ниже показывает распределение длин пакетов для фразы, в которой есть шипящие согласные: Speed skaters sprint to the finish. Глубокие впадины графика приходятся именно на шипящие фрагменты этой фразы. На рисунке представлена (источник) динамика входного аудиопотока, битрейта и размера выходных (зашифрованных) пакетов, наложенная на общую шкалу времени; поразительное сходство второго и третьего графиков можно видеть невооруженным взглядом.

Плюс, если на рисунок посмотреть через призму математического аппарата цифровой обработки сигналов (который используется в задачах распознавания речи), вроде PHMM-автомата (Profile Hidden Markov Models — расширенный вариант скрытой марковской модели), то можно будет увидеть намного больше, чем просто отличие гласных звуков от согласных. В том числе идентифицировать пол, возраст, язык и эмоции говорящего.
Атака на VoIP по обходным каналам
PHMM-автомат очень хорошо справляется с обработкой числовых цепочек, с их сравнением между собой и нахождением закономерностей между ними. Именно поэтому PHMM-автомат широко используется в решении задач распознавания речи.
Кроме того, PHMM-автомат оказывается полезным и для прослушивания зашифрованного аудиопотока. Но не напрямую, а по обходным каналам. Иначе говоря, PHMM-автомат не может прямо ответить на вопрос: «Какая фраза содержится в этой цепочке шифрованных аудиопакетов?», но может с большой точностью ответить на вопрос: «Содержится ли такая-то фраза в таком-то месте такого-то зашифрованного аудиопотока?»
Таким образом, PHMM-автомат может распознавать только те фразы, на которые его изначально натренировали. Однако современные технологии глубокого обучения настолько могущественны, что способны натренировать PHMM-автомат до такой степени, что для него фактически стирается грань между двумя озвученными чуть выше вопросами. Чтобы оценить всю мощь данного подхода, нужно слегка погрузиться в матчасть.
Несколько слов о DTW-алгоритме
DTW-алгоритм (Dynamic Time Warping — динамическая трансформация временной шкалы) до недавнего времени широко использовался при решении задач идентификации говорящего и распознавания речи. Он способен находить сходства между двумя числовыми цепочками, сгенерированными по одному и тому же закону, — даже когда эти цепочки генерируются с разной скоростью и располагаются в разных местах шкалы времени. Это именно то, что происходит при оцифровке аудиопотока. Например, говорящий может произнести одну и ту же фразу с одним и тем же акцентом, но при этом быстрее или медленнее, с разным фоновым шумом. Это не помешает DTW-алгоритму найти сходства между первым и вторым вариантом. Чтобы проиллюстрировать на примере, рассмотрим две целочисленные цепочки:
0 0 0 4 7 14 26 23 8 3 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 5 6 13 25 24 9 4 2 0 0 0 0 0
Если сравнивать эти две цепочки «в лоб», то они, очевидно, сильно отличаются друг от друга. Однако если мы сравним их характеристики, то увидим, что цепочки определенно имеют некоторое сходство: обе они состоят из восьми целых чисел, обе имеют схожее пиковое значение (25–26). «Лобовое» сравнение, начинающееся от их точек входа, игнорирует эти важные характеристики. Но DTW-алгоритм, сравнивая две цепочки, учитывает их и другие показатели. Однако мы не будем сильно акцентироваться на DTW-алгоритме, поскольку на сегодняшний день есть более эффективная альтернатива — PHMM-автоматы.
Экспериментально было установлено, что PHMM-автоматы «опознают» фразы из зашифрованного аудиопотока с 90%-й точностью, тогда как DTW-алгоритм дает только 80%-ю гарантию. Поэтому DTW-алгоритм (который в годы своего расцвета был популярным инструментом в решении задач распознавания речи) упоминаем лишь для того, чтобы показать, насколько лучше в сравнении с ним PHMM-автоматы (в частности, при распознавании шифрованного аудиопотока). Конечно, DTW-алгоритм обучается значительно быстрее, чем PHMM-автоматы. Это его преимущество неоспоримо. Однако при современных вычислительных мощностях оно не будет принципиальным.
Продолжение доступно только участникам
Вариант 1. Присоединись к сообществу «Xakep.ru», чтобы читать все материалы на сайте
Членство в сообществе в течение указанного срока откроет тебе доступ ко ВСЕМ материалам «Хакера», позволит скачивать выпуски в PDF, отключит рекламу на сайте и увеличит личную накопительную скидку! Подробнее
Вариант 2. Открой один материал
Заинтересовала статья, но нет возможности стать членом клуба «Xakep.ru»? Тогда этот вариант для тебя! Обрати внимание: этот способ подходит только для статей, опубликованных более двух месяцев назад.
Я уже участник «Xakep.ru»



