Содержание статьи
Несмотря на то что XXI век принес в наши дома (не во все, но всё же) гигабитные каналы связи и котиков на YouTube в разрешении 4K и 60 FPS, основой Сети, самой массовой его частью, все еще остаются текстовые данные. Рефераты и курсовые работы, технические драмы на Хабре и Stack Overflow, сидящий занозой в ... Роскомнадзора Луркмор — все это текст, все это слова. А поскольку каталогизация в реальном мире очевидно хромает, то без хорошего полнотекстового поиска никуда.
Основных поисковых брендов на данный момент существует несколько: это Solr, Sphinx, Elasticsearch. Но сегодня мы поговорим только о последнем. Elasticsearch — это на самом деле не вполне самостоятельный поиск. Это, скорее, красивая обертка над библиотекой Apache Lucene (на нем же строится Solr). Но не стоит воспринимать слово «обертка» в негативном ключе. Lucene сам по себе вообще мало на что годен. Это все-таки не полноценный сервис, а просто библиотека для построения поисковых систем. Все, что она может, — только индексировать и искать. А API для ввода данных, для поисковых запросов, кластеризация и прочее — это все отдается на откуп «обертке».
Что нам дает Elasticsearch?
Масштабируемость и отказоустойчивость. Elasticsearch легко масштабируется. К уже имеющейся системе можно на ходу добавлять новые серверы, и поисковый движок сможет сам распределить на них нагрузку. При этом данные будут распределены таким образом, что при отказе какой-то из нод они не будут утеряны и сама поисковая система продолжит работу без сбоев.
На самом деле оно даже работает. В хипстерском стиле «чувак, вот тебе три команды — пользуйся ими и, пожалуйста, не задумывайся, какой ад происходит внутри». И часто это прокатывает. Новые ноды подключаются буквально парой строчек в конфиге, почти как у Redis. Главное, мастеры со слейвами не путать, а то он возьмет и молча потрет все данные :). При выпадении каких-либо серверов из кластера, если правильно были распределены реплики данных, корректно настроенное приложение продолжит поиск, как будто ничего не произошло. После того как сервер поднимется, он сам вернется в кластер и подтянет последние изменения в данных.
Мультиарендность (англ. multitenancy) — возможность организовать несколько различных поисковых систем в рамках одного объекта Elasticsearch. Причем организовать их можно абсолютно динамически. Очень интересная особенность, которая в отдельных случаях становится определяющей при выборе поисковой системы. На первый взгляд может показаться, что необходимости в этой особенности нет. Классические системы поиска типа Sphinx обычно индексируют какую-то одну базу с определенным кругом данных. Это форумы, интернет-магазины, чаты, различные каталоги. Все те места, где поиск для всех посетителей должен быть идентичным. Но на самом деле довольно часто возникают ситуации, когда систем поиска должно быть больше одной. Это либо мультиязычные системы, либо системы, где есть определенное количество пользователей, которым нужно предоставлять возможность поиска по их персональным данным.
В первом случае нам нужно строить отдельные индексы по разным языкам, отдельно настраивать морфологию, стемминг, параметры нечеткого поиска для того, чтобы получить максимально качественные результаты для каждого из языков. Во втором случае в качестве гипотетического примера можно взять какой-нибудь корпоративный аналог Dropbox’а. Приходит клиент, регистрируется, заливает свои документы. Система их анализирует, угадывает язык, парсит, заливает в отдельный индекс поисковой системы, настраивает параметры под нужный язык. И далее клиент может пользоваться поиском по своим документам. Поиск будет работать достаточно быстро, потому что данных в индексе отдельного клиента всегда будет меньше, чем в одном большом общем, будет возможность динамически такие индексы создавать, устанавливать различные поисковые параметры. Ну и данные клиентов будут изолированы друг от друга.
Операционная стабильность — на каждое изменение данных в хранилище ведется логирование сразу на нескольких ячейках кластера для повышения отказоустойчивости и сохранности данных в случае разного рода сбоев.
Отсутствие схемы (schema-free) — Elasticsearch позволяет загружать в него обычный JSON-объект, а далее он уже сам все проиндексирует, добавит в базу поиска. Позволяет не заморачиваться слишком сильно над структурой данных при быстром прототипировании.
RESTful api — Elasticsearch практически полностью управляется по HTTP с помощью запросов в формате JSON.
Краткий словарик начинающего гуманитария
- Стемминг — это нахождение основы слова для заданного исходного слова. Основа необязательно совпадает с морфологическим корнем слова.
- Лемматизация — приведение слова к нормальной (словарной) форме. Для существительных это именительный падеж и единственное число.
- Корпус — в лингвистике корпусом называется совокупность текстов, собранных в соответствии с определенными принципами, размеченных по определенному стандарту и обеспеченных специализированной поисковой системой. Это может быть и разделение по стилям и жанрам, разделение по эпохе написания, по форме написания.
- Параллельный корпус — это один или более текстов на двух языках, сопоставленные между собой парами, когда в каждой паре оба предложения несут один и тот же смысл.
- Стоп-слова, или шумовые слова, — предлоги, суффиксы, междометия, цифры, частицы и подобное. Общие шумовые слова всегда исключаются из поискового запроса (кроме поиска по строгому соответствию поисковой фразы), также они игнорируются при построении инвертированного индекса.
- N-грамма — последовательность из n элементов. С семантической точки зрения это может быть последовательность звуков, слогов, слов или букв.
Установка и использование
Установить Elasticsearch проще простого. Есть готовые репозитории и для RHEL/Centos, и для Debian. Можно отдельно установить из тарбола.
# rpm --import https://packages.elasticsearch.org/GPG-KEY-elasticsearch
# echo '
[elasticsearch-1.5]
name=Elasticsearch repository for 1.5.x packages
baseurl=http://packages.elasticsearch.org/elasticsearch/1.5/centos
gpgcheck=1
gpgkey=http://packages.elasticsearch.org/GPG-KEY-elasticsearch
enabled=1
' > /etc/yum.repos.d/elastic.repo
# yum install elasticsearch
# curl -XGET http://localhost:9200/
{
"status" : 200,
"name" : "Franklin Hall",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "1.5.0",
"build_hash" : "544816042d40151d3ce4ba4f95399d7860dc2e92",
"build_timestamp" : "2015-03-23T14:30:58Z",
"build_snapshot" : false,
"lucene_version" : "4.10.4"
},
"tagline" : "You Know, for Search"
}

И вся дальнейшая работа с ним происходит посредством HTTP-запросов в JSON-формате. Давай, к примеру, создадим новый индекс и забьем в него какие-нибудь тестовые данные. Я взял отсюда англо-русский параллельный корпус, собранный из данных OpenSubtitles.org. Формат TMX достаточно простой, описывать его отдельно не стану. Напишу небольшой парсер на Python, который бы разбирал файл и заливал данные в новый индекс:
#!/usr/bin/env python
#-*- coding: utf-8 -*-
import sys
from elasticsearch import Elasticsearch
import xml.etree.ElementTree as ET
TMX = sys.argv[1]
es = Elasticsearch()
with open(TMX) as source:
context = iter(ET.iterparse(source, events=('start', 'end')))
_, root = next(context)
num = 1
for event, elem in context:
if event == 'end' and elem.tag == 'tu':
doc = {
'eng': elem[0][0].text.encode('utf-8'),
'rus': elem[1][0].text.encode('utf-8')
}
res = es.index(index="demon-index", doc_type='tmx1', id=num, body=doc)
num += 1
elem.clear()
root.clear()На VPS'ке с четырьмя гигами памяти во флопсе заливка четырех с половиной миллионов документов (чуть больше 900 Мб данных в текстовом формате) занимает примерно полтора часа. В целом очень даже неплохо. Теперь накидаем небольшой скриптик для удобного поиска:
#!/usr/bin/env python
#-*- coding: utf-8 -*-
from __future__ import unicode_literals
import sys
from elasticsearch import Elasticsearch
SEARCH_DATA = sys.argv[1]
es = Elasticsearch()
res = es.search(index="demon-index", body={'fields': ['eng', 'rus'], 'query': {'match': {'eng': SEARCH_DATA}}})
for item in res['hits']['hits']:
print "%s - %s - %s" % (item['_score'], item['fields']['eng'][0], item['fields']['rus'][0])И проверяем, что у нас получилось:
# python search.py "What the hell"
4.5126777 - What... what the hell? - Что... что за черт?
4.368808 - What the hell? What the hell? - Махнем не глядя?
4.149931 - What the hell Mae! - Что за спешка, Мэй?
4.149931 - What the hell? - It.... - Что за черт? - Это...
4.149931 - What the hell happened? - Давай вернемся назад.
# python search.py "God for our right"
3.0920234 - (several) For our God. - (некоторые) Для нашего Бога.
3.0859475 - For our God. - Для нашего Бога.
2.7642622 - Proceed, troops, trusting God for our right, for the Romanian Independence. - Идите вперед, ибо Господь на нашей стороне, во имя независимости Румынии. Карл.
2.654899 - Our fathers were our models for God. - Заткнись.
2.4985123 - God, he liveS right in our neighborhood. - Ничего себе, он живет прямо в нашем районе.Первая колонка — вес полученного значения, остальные две — найденные результаты. А теперь ищем по-русски:
# python ./search.py "Ой все"
4.835098 - - Oh, come on. - - Ой, все, хватит.
4.835098 - Oops, it’s okay. - Ой, все в порядке.
4.8212147 - Oh, that’s okay. - Ой, все в порядке.
4.8188415 - - I’m a bit rusty. - - Ой, как все запущено.
4.8188415 - Oh, it’s over? [sighs] - Ой, уже все закончилось?
# python ./search.py "Чот приуныл"
4.629143 - The whole sad act. - Приуныл.
2.3740823 - Choate, then yale, - Чот, потом Йель,
2.3145716 - Hey, why so glum, William? - Эй, чего приуныл, Уильям.
1.8609953 - Now that the Booroos are missing, he has lost track of life, you see? - Когда Бурусы не пришли, он совсем приуныл.
1.573388 - (Shivers) (Leah) Erm, that’s a good look, Andy. - Ээ... что-то он у тебя приуныл, Энди.Как видишь, неплохо ищет уже прямо из коробки, для какого-нибудь блога или небольшого форума вполне подойдет. А если качество выдачи покажется недостаточно высоким (а к такой мысли рано или поздно приходят почти все), то Elasticsearch предоставляет большое количество возможностей для дальнейшего тюнинга анализаторов и поисковых алгоритмов.
Анализаторы
Выбор правильного анализатора для обработки своих данных — это что-то почти на грани искусства. Изнутри каждый анализатор представляет собой своеобразный конвейер, состоящий из нескольких обработчиков:
- символьной фильтрации;
- токенизации;
- фильтрации полученных токенов.
Главная цель любого анализатора — из длинного предложения, перегруженного ненужными деталями, выжать основную суть и получить список токенов, которые бы ее отражали.

Примерную схему работы конвейера можно увидеть на картинке поблизости. Анализ начинается с опциональных символьных фильтров. Это, к примеру, перевод текста в нижний регистр или подстановка слов. Полученный результат передается токенизатору, главному и единственному обязательному элементу анализатора. Здесь предложение очищается от знаков препинания, разбивается на отдельные слова-токены, которые могут либо сохранять имеющуюся форму, либо обрезаться только до основы слова, либо обрабатываться еще каким-либо образом в зависимости от токенизатора. После токенизатора полученные данные отправляются на дальнейшую фильтрацию, если уже проделанных манипуляций будет недостаточно.
Elasticsearch из коробки предоставляет сразу несколько различных анализаторов. Если их будет мало, то нестандартные анализаторы можно будет добавить с помощью специального API. Вот базовый пример нестандартного анализатора:
PUT /demon-index/_settings
{
"index": {
"analysis": {
"analyzer": {
"customHTMLSnowball": {
"type": "custom",
"char_filter": [
"html_strip"
],
"tokenizer": "standard",
"filter": [
"lowercase",
"stop",
"snowball"
]
}}}}}Что делает этот анализатор:
- Убирает HTML-теги из исходного текста с помощью символьного фильтра html_strip.
- Делит текст на слова и убирает пунктуацию с помощью токенизатора standart.
- Переводит все токены в нижний регистр.
- Убирает токены, находящиеся в списке стоп-слов.
- Проводит стемминг оставшихся токенов с помощью фильтра snowball.
И смотри, как это выглядит на живом примере. Возьмем предложение «Мама мыла раму, пока собака доедала сосиску» и разберем его по пунктам (рис. «Мама мыла-мыла...»).
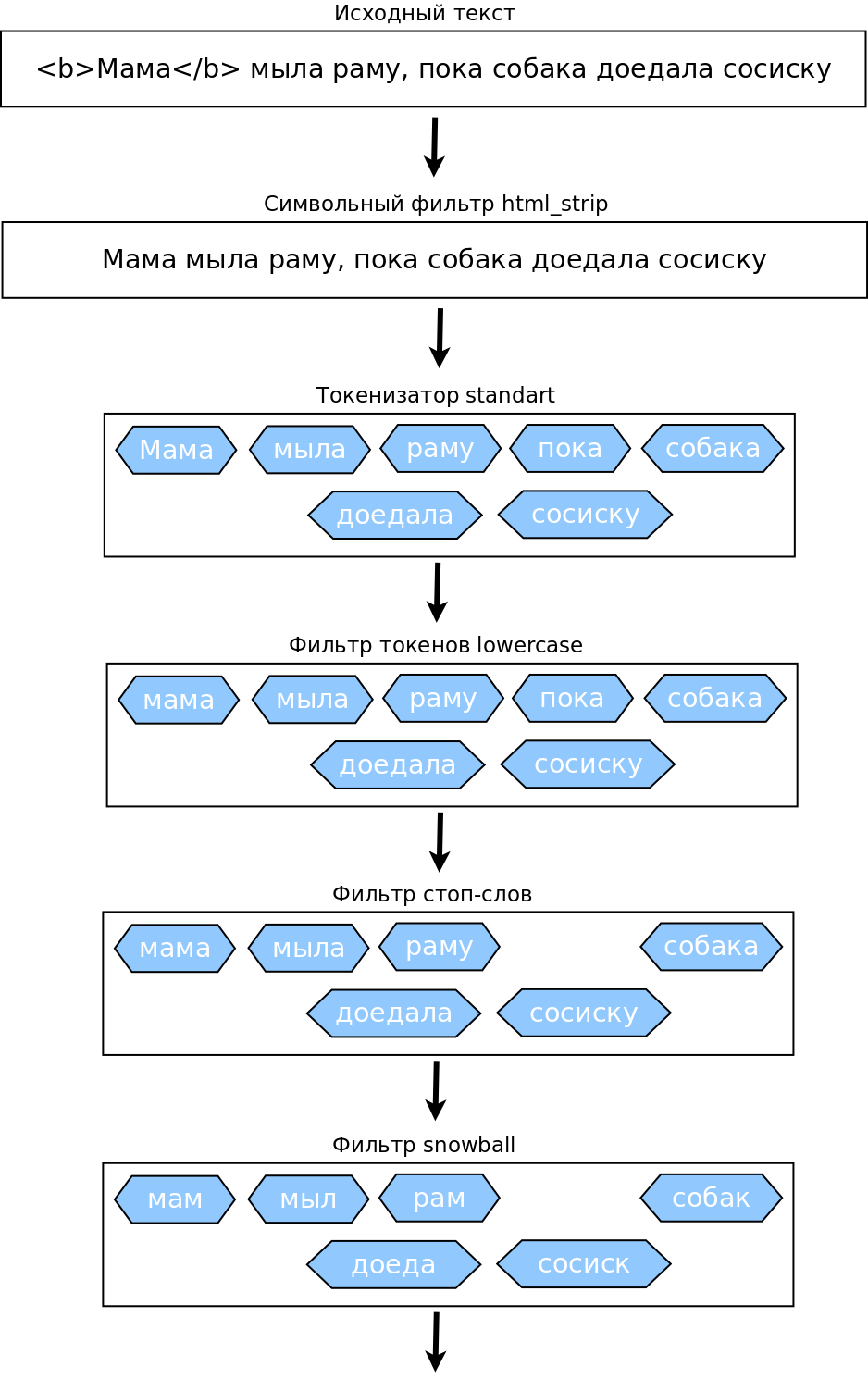
Детальнее о предоставляемых вместе с Elasticsearch анализаторах и фильтрах можно прочитать в официальной документации. Здесь описывать не возьмусь, так как деталей там очень много.
Нечеткий поиск
Обработка естественных языков — это работа с постоянными неточностями. По большей части поисковые движки пытаются анализировать грамматические структуры различных языков, осваивать определенные паттерны, характерные для того или иного языка. Но поисковая система постоянно сталкивается с запросами, выходящими за рамки устоявшихся правил орфографии и морфологии. Чаще всего это либо опечатки, либо банальная безграмотность. Самый простой пример нечеткого поиска — это знаменитое «Возможно, Вы имели в виду...» в Гугле. Когда человек ищет «пгода вИ кутске», а ему показывают погоду в Иркутске.
Основой нечеткого поиска является расстояние Дамерау — Левенштейна — количество операций вставки/удаления/замены/транспозиции для того, чтобы одна строка совпала с другой. Например, для превращения «пгода вИ кутске» в «погода в Иркутске» такое расстояние было бы равно трем — две вставки и одна замена.
Расстояние Дамерау — Левенштейна — это модификация классической формулы Левенштейна, в которой изначально отсутствовала операция транспозиции (перестановки двух соседних символов). Elasticsearch поддерживает возможность использования в нечетком поиске обоих вариантов, по умолчанию включено использование расстояния Дамерау — Левенштейна.
При работе с нечетким поиском также не стоит забывать и о том, как Elasticsearch (да и любой другой поисковый движок в принципе) работает изнутри. Все данные, загружаемые в индекс, сперва проходят обработку анализатором, лемматизацию, стемминг. В индекс уже складываются только «обрывки» исходных данных, содержащие максимум смысла при минимуме знакового объема. И уже по этим самым обрывкам впоследствии проводится поиск, что при использовании нечеткого поиска может давать довольно курьезные результаты.
Например, при использовании анализатора snowball во время нечеткого поиска по слову running оно после прохода через стемминг превратится в run, но при этом по нему не найдется слово runninga, так как для совпадения с ним нужно больше двух правок. Поэтому для повышения качества работы нечеткого поиска лучше использовать самый простой стеммер и отказаться от поиска по синонимам.
Elasticsearch поддерживает несколько различных способов нечеткого поиска:
- match query + fuzziness option. Добавление параметра нечеткости к обычному запросу на совпадение. Анализирует текст запроса перед поиском;
- fuzzy query. Нечеткий запрос. Лучше избегать его использования. Больше похож на поиск по стеммам. Анализ текста запроса перед поиском не производится;
- fuzzy_like_this/fuzzy_like_this_field. Запрос, аналогичный запросу more_like_this, но поддерживающий нечеткость. Также поддерживает возможность анализа весов для лучшего ранжирования результатов поиска;
- suggesters. Предположения — это не совсем тип запроса, скорее другая операция, работающая изнутри на нечетких запросах. Может использоваться как совместно с обычными запросами, так и самостоятельно.
CJK
CJK — это три буквы боли западных систем полнотекстового поиска и людей, которые хотят ими воспользоваться. CJK — это сокращение для Chinese, Japanese, Korean. Три основных восточных языка, составляющих совокупно почти 10% современного интернета. Они отличаются от привычных западных языков практически всем — и письменностью, и морфологией, и синтаксисом. Все это, понятно, вызывает некоторые проблемы при разработке различных систем обработки естественных языков, в том числе и поисковых систем.
У Elasticsearch в этой области дела тоже обстоят неплохо. Есть встроенный анализатор CJK со стеммингом, есть возможность использовать нечеткий поиск. Вот только если по текстам на корейском и японском языках еще хоть как-то можно искать «по классическим правилам» (то есть делим на слова, отбрасываем союзы/предлоги, оставшиеся слова токенизируем и загоняем в индекс), то вот с китайским, в котором слова в предложении не принято разделять пробелами, все куда сложнее.
Для поисковой системы все предложение на китайском остается одной целой единицей, по которым проводится поиск. Например, предложение «Мэри и я гуляем по Пекину» выглядит вот так:
玛丽和我走北京周边.Девять символов без пробелов, 18 байт в UTF-8. В нормальной вселенной это прокатило бы за одно слово, но не тут. Если стратегически расставить пробелы в нужных местах, то предложение станет выглядеть вот так:
玛丽 和 我 走 北京 周边.Шесть слов. С этим уже можно было бы работать. Вот только пробелы в китайском никто не использует. Можно пытаться разделять предложения на слова в автоматическом режиме (уже даже существует пара готовых решений), но и тут тебя будут ожидать неприятности. Некоторые слоги, стоящие в предложении рядом, могут, в зависимости от того, как их разделить пробелами, складываться в разные слова и резко менять смысл предложения. Возьмем для примера предложение 我想到纽约:
我 想 到 纽约 — Я хочу поехать в Нью-Йорк.
我 想到 纽约 — Я вспомнил про Нью-Йорк.Как видишь, на автоматизированное членение лучше не полагаться. Как тогда быть? Тут нам поможет поиск по N-граммам. Предложение делится на куски по два-три знака:
玛丽和我走北京周边 = 玛丽 – 丽和 – 和我 – 我走 – 走北 – 北京 – 京周 – 周边И уже по ним далее идет поиск. К этому можно добавить нечеткий поиск с расстоянием в одну-две замены, и уже получится более-менее сносный поиск.
Безопасность
У Elasticsearch нет никакой встроенной системы авторизации и ограничения прав доступа. После установки он по умолчанию вешается на порт 9200 на все доступные интерфейсы, что делает возможным не только полностью увести у тебя все, что находится в поисковой базе, но и, чисто теоретически, через обнаруженную дыру залезть в систему и там начудить. До версии 1.2 такая возможность была доступна прямо из коробки (см. CVE-2014-3120) и напрягаться не было вообще никакой нужды. В 1.2 по умолчанию выполнение скриптов в поисковых запросах отключено, но пока что и это не спасает.
Совсем недавно мы наблюдали ботнет на эластиках версий в том числе и 1.4 и выше. Судя по всему, использовалась уязвимость CVE-2015-1427. В версии 1.4.3 ее вроде как закрыли, но, сам понимаешь, полагаться на удачу в таких делах не вариант (на самом деле да, пока писалась эта статья, свежепоставленный эластик версии 1.5.0 на тестовых виртуалках у меня успели поломать уже на второй день :)). Вешай сервис только на локальные IP, все необходимые подключения извне ограничивай только доверенными адресами, фильтруй поисковые запросы, своевременно обновляйся. Спасение утопающих — дело рук самих утопающих.
К теме сохранности данных также стоит упомянуть про бэкапы. Возможности резервного копирования и восстановления встроены в сам Elasticsearch, причем довольно интересно. Перед началом создания резервных копий нужно эластику сообщить, куда они будут складываться. В местных терминах это называется «создать репозиторий»:
$ curl -XPUT 'http://localhost:9200/_snapshot/my_backup' -d '{
"type": "fs",
"settings": {
"location": "/es-backup",
"compress": true
}
}'Здесь
- type — тип хранилища, куда они будут складываться. Из коробки есть только файловая система. С помощью дополнительных плагинов можно реализовать заливку на AWS S3, HDFS и Azure Cloud;
- location — куда сохранять новые бэкапы;
- compress — сжимать ли бэкапы. Толку не очень много, так как по факту сжимает только метаинформацию, а файлы данных остаются несжатыми. По умолчанию включено.
После того как создан репозиторий, можно начать бэкапиться:
$ curl -XPUT "localhost:9200/_snapshot/my_backup/snapshot_1?wait_for_completion=true"Такой запрос создает бэкап с названием snapshot_1 в репозитории my_backup.
Восстановить данные можно следующим образом:
$ curl -XPOST "localhost:9200/_snapshot/my_backup/snapshot_1/_restore"Причем снимки состояния делаются инкрементальные. То есть в первый раз создается полный бэкап, а далее при последующих бэкапах фиксируется только разница состояния между текущим моментом и моментом предыдущего бэкапа. Если у тебя кластер с несколькими мастерами, то хранилище репозитория должно шариться между всеми мастерами (то есть, при хранении на файловой системе, это должен быть какого-либо рода сетевой диск, доступный всем мастерам). Файлы репозитория я бы тоже с диска куда-нибудь бэкапил на всякий случай :).
Эпилог
На этом, наверное, стоит пока остановиться. К сожалению, за бортом статьи остались животрепещущие детали того, как на самом деле работает кластеризация и действительно ли Elasticsearch такой неубиваемый, как его хвалят. Не было сказано совсем ничего про систему плагинов и различные веб-панели для удобного администрирования поискового кластера. Но и без этого Elasticsearch уже выглядит достаточно интересным, чтобы продолжить с ним знакомство самостоятельно и, возможно, найти для себя идеальный поиск.